

Google DeepMind hari ini mengumumkan perluasan signifikan pada keluarga Gemini 2.5, dengan meluncurkan rilis stabil Gemini 2.5 Pro dan Gemini 2.5 Flash bersamaan dengan pratinjau model Gemini 2.5 Flash‑Lite yang sepenuhnya baru. Pembaruan ini mencerminkan komitmen berkelanjutan Google untuk menawarkan spektrum model AI yang menyeimbangkan biaya, kecepatan, dan kinerja untuk berbagai beban kerja.
Rilis Stabil: Gemini 2.5 Pro & Flash
Pada tanggal 17 Juni 2025, Google menandai ketersediaan umum Gemini 2.5 Pro dan Gemini 2.5 Flash. Varian Pro memberikan daya nalar maksimum dan dirancang khusus untuk tugas-tugas dengan kompleksitas tinggi seperti pembuatan kode tingkat lanjut, analisis ilmiah, dan sintesis data skala besar. Sebaliknya, Gemini 2.5 Flash menawarkan opsi tingkat menengah yang dioptimalkan untuk penggunaan sehari-hari yang menuntut latensi rendah—ideal untuk chatbot, peringkasan, dan pembuatan konten dalam skala besar.
Tinjauan Umum: Tiga Model dalam Keluarga Gemini -2.5
| Pilih Model | Status | Kekuatan | Kasus Penggunaan Ideal |
|---|---|---|---|
| Gemini 2.5 Flash-Lite (pratinjau) | Preview | Tercepat & termurah; multimodal; penalaran yang dapat dikontrol; didukung oleh alat | Tugas bervolume tinggi seperti chatbot, peringkasan, pencarian |
| Gemini 2.5 Kilat | Stabil | Seimbang: latensi rendah, penalaran bagus, multimodal | Percakapan waktu nyata, dukungan pelanggan |
| Gemini 2.5 Pro | Stabil | Paling mampu: penalaran mendalam, konteks besar, multimodal | Penelitian, pengkodean kompleks, tugas ilmiah |
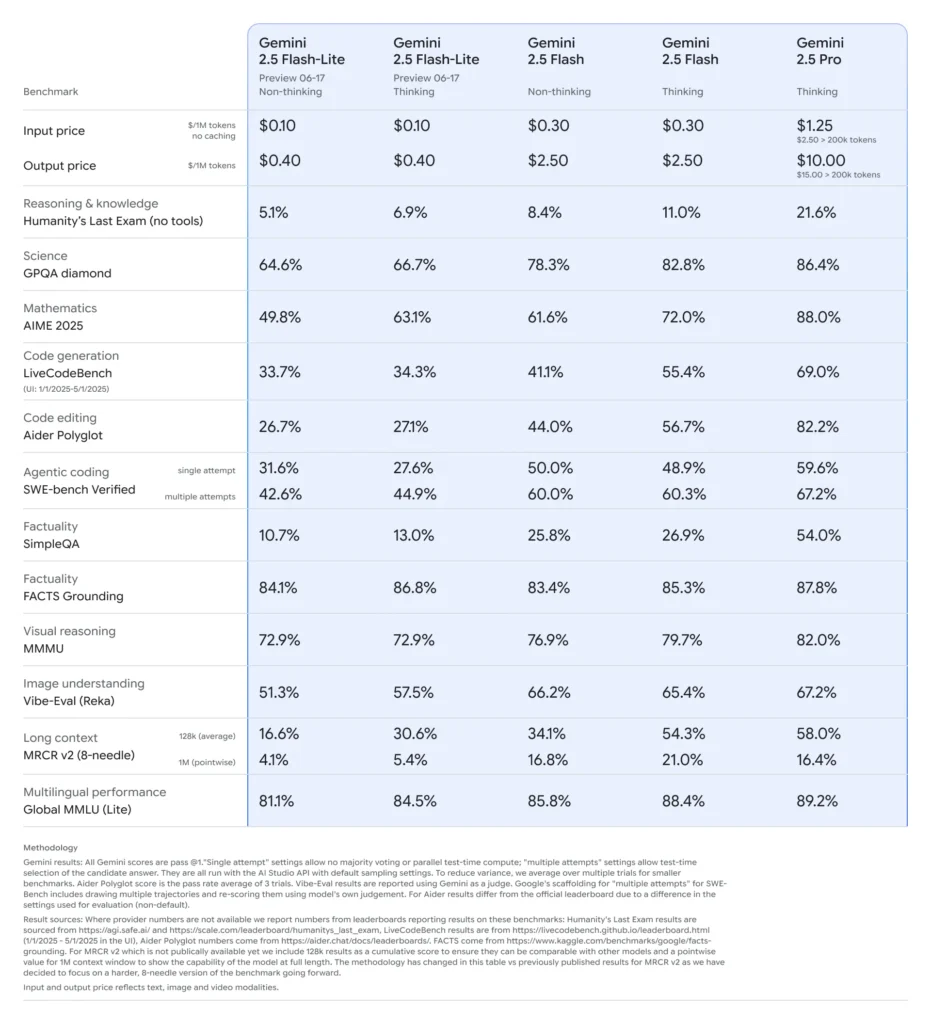
Gemini 2.5 Flash‑Lite: Sorotan Pratinjau
Latensi sangat rendah & penghematan biaya:Dirancang untuk aplikasi real-time bervolume tinggi seperti penerjemahan, klasifikasi, dan peringkasan. Menawarkan inferensi yang lebih cepat dan biaya per panggilan yang lebih rendah dibandingkan dengan Flash‑Lite 2.0 dan versi Flash lengkap.
Peningkatan kinerja dasar: Mengungguli model Flash‑Lite sebelumnya dalam berbagai tolok ukur dalam pembuatan kode, logika, matematika, penalaran multimoda, dan sains.
Biaya dan efisiensi: Harga Flash‑Lite (pratinjau): ~$0.10 per 1 juta token masukan dan ~$0.40 per 1 juta token keluaran—jauh lebih murah daripada Flash ($0.30/$2.50) dan Pro ($1.25/$10).
Kemampuan penuh Gemini -2.5:
- Berpikir yang Dapat Dikendalikan: Pengguna dapat mengatur “anggaran pemikiran” (batas token) untuk memperdagangkan kecepatan demi kedalaman—Flash‑Lite dapat mengaktifkannya sesuai kebutuhan.
- Masukan Multimoda: Mendukung teks, gambar, audio, dan video (termasuk klip berdurasi satu jam), dengan kemampuan untuk mengurai bagan, UI, adegan, ringkasan acara.
- Integrasi Alat: Termasuk Google Search, eksekusi kode dan jendela konteks juta token, yang menyamai kemampuan Flash dan Pro.
Posisi pada Kurva Harga‑Kinerja
Google memposisikan Flash‑Lite dengan kecepatan tinggi dan biaya rendah di Batas Pareto, yang berarti model ini termasuk salah satu model yang paling hemat biaya dan mampu di seluruh dunia (). Dalam evaluasi komparatif, Flash‑Lite mewakili nilai terbaik: cerdas namun terjangkau.
Tentang Flash dan Pro
- Gemini 2.5 Kilat: Model pemikiran multimodal yang stabil, berlatensi rendah. Diposisikan di bawah Pro tetapi kira-kira setara dengan GPT-4o dalam hal kemampuan, dengan kecepatan dan efisiensi biaya yang unggul ().
- Gemini 2.5 Pro: Model Google yang paling canggih. Terkenal karena menangani video/audio berdurasi berjam-jam, kode dan matematika yang rumit, serta penalaran kontekstual yang sangat besar. Juga memperkenalkan "anggaran pemikiran" yang selektif dan kualitas kode yang ditingkatkan untuk berfungsi sebagai AI andalan yang stabil dalam jangka panjang.
Penerapan & Harga
- Ketersediaan:Ketiga model tersebut dapat diakses melalui Google AI Studio, AI Google Cloud Vertex, Dan aplikasi gemini .
- Struktur biaya (Harga Vertex AI mulai 16 Juni 2025):
- per: $1.25/1 juta input, $10/1 juta output (lebih tinggi dari 200 ribu token)
- flash: $0.15/1 juta input, $3.50/1 juta output dalam mode “berpikir”—dan mencakup 1,500 permintaan gratis setiap hari ()
- Flash‑Lite (pratinjau): ~$0.10/$0.40 per 1 juta token
Mulai
CometAPI menyediakan antarmuka REST terpadu yang menggabungkan ratusan model AI—di bawah titik akhir yang konsisten, dengan manajemen kunci API bawaan, kuota penggunaan, dan dasbor penagihan. Daripada harus mengelola beberapa URL dan kredensial vendor.
Pengembang dapat mengakses Gemini 2.5 Flash-Lite (pratinjau) API melalui API Komet, model terbaru yang tercantum adalah pada tanggal publikasi artikel. Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda berintegrasi.