

OpenAI menerbitkan pratinjau penelitian gpt-oss-perlindungan, keluarga model inferensi bobot terbuka yang dirancang untuk memungkinkan pengembang menerapkan mereka sendiri kebijakan keselamatan pada waktu inferensi. Daripada mengirimkan pengklasifikasi tetap atau mesin moderasi kotak hitam, model-model baru disetel dengan baik untuk alasan dari kebijakan yang disediakan pengembang, memancarkan rantai pemikiran (CoT) yang menjelaskan penalaran mereka, dan menghasilkan keluaran klasifikasi terstruktur. Diumumkan sebagai pratinjau penelitian, gpt-oss-safeguard disajikan sebagai sepasang model penalaran—gpt-oss-safeguard-120b dan gpt-oss-safeguard-20b—disempurnakan dari keluarga gpt-oss dan dirancang secara eksplisit untuk melakukan tugas klasifikasi keselamatan dan penegakan kebijakan selama inferensi.
Apa itu gpt-oss-safeguard?
gpt-oss-safeguard adalah sepasang model penalaran berbobot terbuka, hanya teks yang telah dilatih pasca dari keluarga gpt-oss untuk menafsirkan kebijakan yang ditulis dalam bahasa alami dan memberi label teks sesuai dengan kebijakan tersebutCiri khasnya adalah kebijakannya disediakan pada waktu inferensi (kebijakan sebagai masukan), tidak terintegrasi ke dalam bobot pengklasifikasi statis. Model-model ini dirancang terutama untuk tugas-tugas klasifikasi keselamatan—misalnya, moderasi multi-kebijakan, klasifikasi konten di berbagai rezim regulasi, atau pemeriksaan kepatuhan kebijakan.
Mengapa ini penting
Sistem moderasi tradisional biasanya bergantung pada (a) set aturan tetap yang dipetakan ke pengklasifikasi yang dilatih pada contoh berlabel, atau (b) heuristik/regex untuk deteksi kata kunci. gpt-oss-safeguard berupaya mengubah paradigma: alih-alih melatih ulang pengklasifikasi setiap kali kebijakan berubah, Anda menyediakan teks kebijakan (misalnya, kebijakan penggunaan yang dapat diterima perusahaan Anda, TOS platform, atau pedoman regulator), dan model akan memberikan alasan tentang apakah suatu konten melanggar kebijakan tersebut. Hal ini menjanjikan kelincahan (kebijakan berubah tanpa pelatihan ulang) dan interpretabilitas (model menghasilkan rangkaian penalarannya).
Inilah inti filosofinya—”Mengganti hafalan dengan penalaran, dan menebak dengan penjelasan.”
Hal ini merupakan tahap baru dalam keamanan konten, yang beralih dari “mempelajari aturan secara pasif” menjadi “memahami aturan secara aktif”.
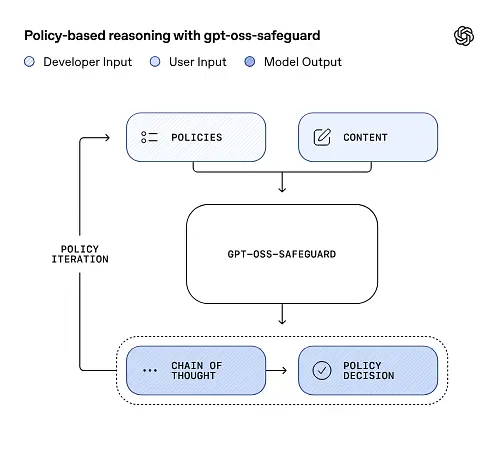
gpt-oss-safeguard dapat langsung membaca kebijakan keamanan yang ditetapkan oleh pengembang dan mengikuti kebijakan tersebut untuk membuat penilaian selama inferensi.
Bagaimana cara kerja gpt-oss-safeguard?
Penalaran kebijakan sebagai masukan
Pada saat inferensi, Anda memberikan dua hal: teks kebijakan dan konten kandidat untuk diberi label. Model memperlakukan kebijakan sebagai instruksi utama dan kemudian melakukan penalaran langkah demi langkah untuk menentukan apakah konten diizinkan, tidak diizinkan, atau memerlukan langkah moderasi tambahan. Pada tahap inferensi, model:
- menghasilkan keluaran terstruktur yang mencakup kesimpulan (label, kategori, keyakinan) dan jejak penalaran yang dapat dibaca manusia yang menjelaskan mengapa kesimpulan itu dicapai.
- menelan kebijakan dan konten yang akan diklasifikasikan,
- secara internal berargumen melalui klausul kebijakan menggunakan langkah-langkah seperti rantai pemikiran, dan
Sebagai contoh:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Ia akan merespons:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Rantai Pemikiran (CoT) dan keluaran terstruktur
gpt-oss-safeguard dapat memancarkan jejak CoT lengkap sebagai bagian dari setiap inferensi. CoT dirancang agar dapat diperiksa—tim kepatuhan dapat memahami alasan model mencapai kesimpulan, dan teknisi dapat menggunakan jejak tersebut untuk mendiagnosis ambiguitas kebijakan atau mode kegagalan model. Model ini juga mendukung keluaran terstruktur—misalnya, JSON yang berisi putusan, bagian kebijakan yang dilanggar, skor keparahan, dan tindakan perbaikan yang disarankan—sehingga mudah diintegrasikan ke dalam alur moderasi.
Tingkat “upaya penalaran” yang dapat disesuaikan
Untuk menyeimbangkan latensi, biaya, dan ketelitian, model mendukung upaya penalaran yang dapat dikonfigurasi: rendah / sedang / tinggiUpaya yang lebih tinggi meningkatkan kedalaman rantai pemikiran dan umumnya menghasilkan inferensi yang lebih kuat, tetapi lebih lambat dan lebih mahal. Hal ini memungkinkan pengembang untuk memilah beban kerja—gunakan upaya rendah untuk konten rutin dan upaya tinggi untuk kasus-kasus khusus atau konten berisiko tinggi.
Apa struktur modelnya dan versi apa saja yang ada?
Keluarga teladan dan garis keturunan
gpt-oss-safeguard adalah pasca pelatihan varian OpenAI sebelumnya gpt-oss model terbuka. Keluarga Safeguard saat ini mencakup dua ukuran yang dirilis:
- gpt-oss-safeguard-120b — model parameter 120 miliar yang ditujukan untuk tugas penalaran akurasi tinggi yang masih berjalan pada satu GPU 80GB dalam runtime yang dioptimalkan.
- gpt-oss-safeguard-20b — model parameter 20 miliar yang dioptimalkan untuk inferensi berbiaya rendah dan lingkungan edge atau on-prem (dapat berjalan pada perangkat VRAM 16GB dalam beberapa konfigurasi).
Catatan arsitektur dan karakteristik runtime (apa yang diharapkan)
- Parameter aktif per token: Arsitektur gpt-oss yang mendasarinya menggunakan teknik yang mengurangi jumlah parameter yang diaktifkan per token (campuran desain gaya perhatian padat dan jarang / campuran para ahli dalam gpt-oss induk).
- Secara praktis, kelas 120B cocok untuk akselerator tunggal berukuran besar dan kelas 20B didesain untuk beroperasi pada pengaturan VRAM 16 GB dalam runtime yang dioptimalkan.
Model perlindungan adalah tidak dilatih dengan data biologis atau keamanan siber tambahan, dan analisis skenario penyalahgunaan terburuk yang dilakukan untuk rilis gpt-oss secara kasar berlaku untuk varian perlindungan. Model-model ini ditujukan untuk klasifikasi, bukan pembuatan konten bagi pengguna akhir.
Apa tujuan dari gpt-oss-safeguard?
Anda
- Fleksibilitas kebijakan: biarkan pengembang menentukan kebijakan apa pun dalam bahasa alami dan biarkan model menerapkannya tanpa pengumpulan label khusus.
- Dapat dijelaskan: memaparkan alasan sehingga keputusan dapat diaudit dan kebijakan diulang.
- Aksesibilitas: menyediakan alternatif bobot terbuka sehingga organisasi dapat menjalankan penalaran keselamatan secara lokal dan memeriksa bagian dalam model.
Perbandingan dengan pengklasifikasi klasik
Kelebihan vs. pengklasifikasi tradisional
- Tidak ada pelatihan ulang untuk perubahan kebijakan: Jika kebijakan moderasi Anda berubah, perbarui dokumen kebijakan daripada mengumpulkan label dan melatih ulang pengklasifikasi.
- Alasan yang lebih kaya: Keluaran CoT dapat mengungkap interaksi kebijakan yang halus dan memberikan pembenaran naratif yang berguna bagi peninjau manusia.
- Kustomisasi: Satu model tunggal dapat menerapkan banyak kebijakan berbeda secara bersamaan selama inferensi.
Kontra vs. pengklasifikasi tradisional
- Batasan kinerja untuk beberapa tugas: Catatan evaluasi OpenAI mencatat bahwa pengklasifikasi berkualitas tinggi yang dilatih pada puluhan ribu contoh berlabel dapat mengungguli gpt-oss-safeguard pada tugas klasifikasi khusus. Ketika tujuannya adalah akurasi klasifikasi mentah dan Anda memiliki data berlabel, pengklasifikasi khusus yang dilatih pada distribusi tersebut dapat memberikan hasil yang lebih baik.
- Latensi dan biaya: Penalaran dengan CoT membutuhkan komputasi intensif dan lebih lambat daripada pengklasifikasi ringan; hal ini dapat membuat jalur yang sepenuhnya berbasis pengaman menjadi mahal dalam skala besar.
Singkatnya: gpt-oss-safeguard paling baik digunakan di mana kelincahan kebijakan dan auditabilitas merupakan prioritas atau ketika data berlabel langka — dan sebagai komponen pelengkap dalam jalur hibrida, tidak mesti sebagai pengganti langsung untuk pengklasifikasi yang dioptimalkan skalanya.
Bagaimana kinerja gpt-oss-safeguard dalam evaluasi OpenAI?
OpenAI menerbitkan hasil dasar dalam laporan teknis 10 halaman yang merangkum evaluasi internal dan eksternal. Poin-poin utama (metrik terpilih yang berpengaruh):
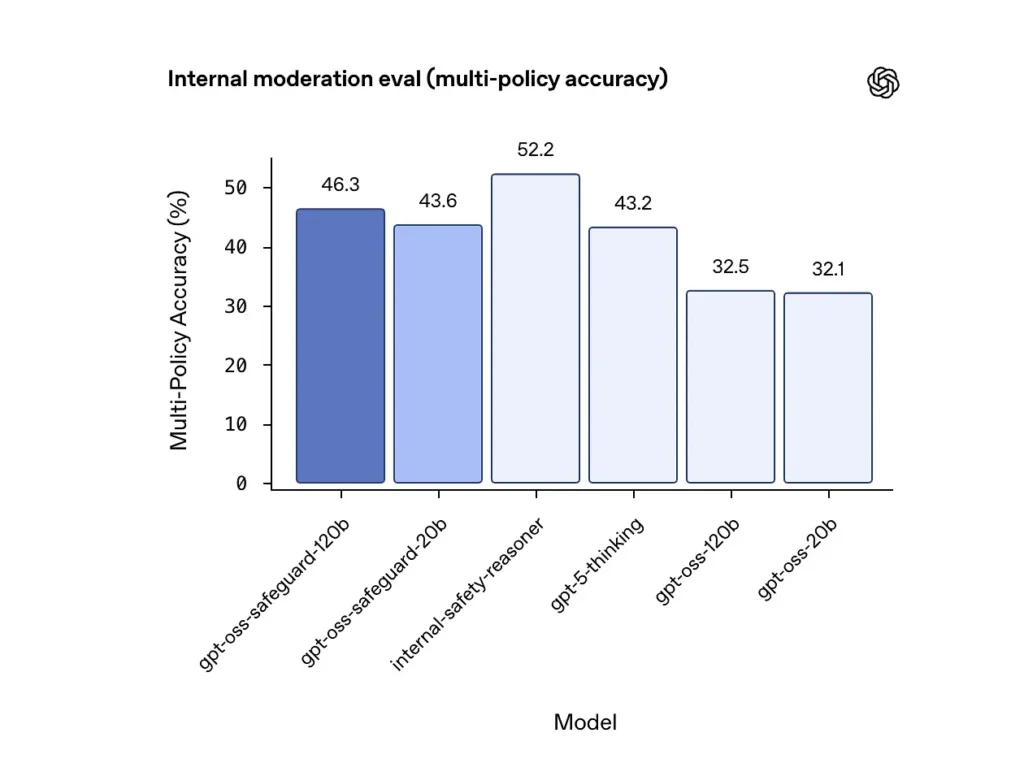
Akurasi multi-kebijakan (evaluasi internal)
OpenAI mengevaluasi akurasi multi-kebijakan dengan memberikan model beberapa kebijakan secara bersamaan dan menghitung prediksi sebagai benar hanya jika cocok dengan label emas di seluruh semua kebijakan. Hasil:
- gpt-oss-safeguard-120b: 46.3% akurasi multi-kebijakan
- gpt-oss-safeguard-20b: 43.6%
- Untuk perbandingan: gpt-5-berpikir: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
Kumpulan "safety-reasoner" internal OpenAI memperoleh skor 52.2% dalam pengujian yang sama. Angka-angka ini menunjukkan bahwa model pengamanan jauh lebih unggul daripada model dasar gpt-oss mereka dalam tugas multi-kebijakan, dan bahkan melampaui garis dasar pemikiran gpt-5 yang lebih besar dalam metrik multi-kebijakan internal.
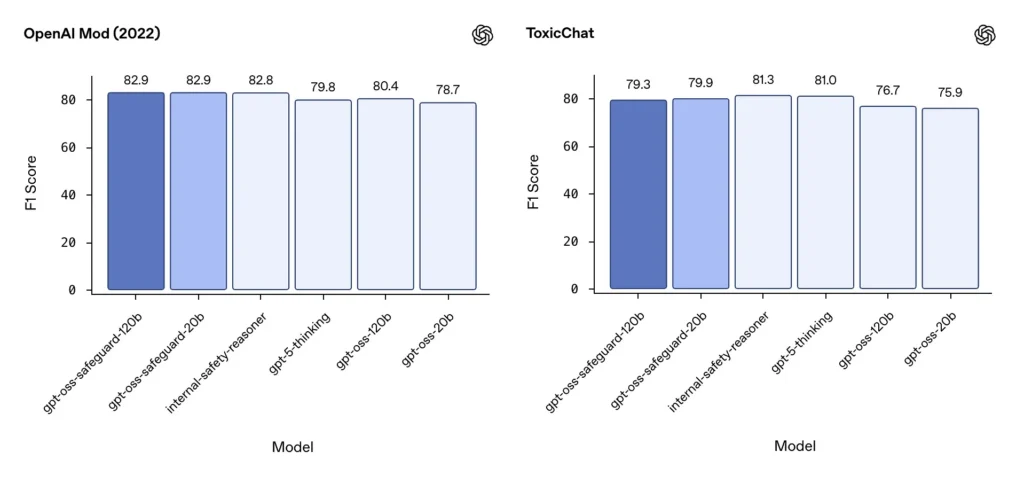
Moderasi F1 (benchmark eksternal)
Pada dataset moderasi OpenAI tahun 2022 dan tolok ukur publik ToxicChat, model gpt-oss-safeguard mencapai skor F1 yang solid:
- Mod OpenAI (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- Obrolan Beracun F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Skor ini menempatkan gpt-oss-safeguard di dekat atau sedikit di belakang sistem internal OpenAI yang terspesialisasi pada beberapa tolok ukur, dan secara umum di depan sistem gpt-oss yang belum disempurnakan.
Keterbatasan yang diamati
OpenAI menandai dua batasan praktis:
- Pengklasifikasi yang dilatih pada kumpulan data berlabel besar dan spesifik tugas masih dapat mengungguli model pengamanan ketika akurasi klasifikasi adalah satu-satunya tujuan.
- Biaya komputasi dan latensi: Penalaran CoT meningkatkan waktu inferensi dan konsumsi komputasi, yang mempersulit penskalaan ke lalu lintas tingkat platform kecuali jika dipasangkan dengan pengklasifikasi triase dan jalur asinkron.
Kesetaraan multibahasa
gpt-oss-safeguard berkinerja setara dengan model gpt-oss yang mendasarinya di banyak bahasa dalam pengujian bergaya MMMLU, yang menunjukkan varian perlindungan yang disetel dengan baik mempertahankan kemampuan penalaran yang luas.
Bagaimana tim dapat mengakses dan menerapkan gpt-oss-safeguard?
OpenAI menyediakan bobot di bawah Apache 2.0 dan menautkan model untuk diunduh (Hugging Face). Karena gpt-oss-safeguard adalah model bobot terbuka, penerapan lokal dan terkelola sendiri (disarankan untuk privasi dan kustomisasi)
- Unduh bobot model (dari OpenAI / Hugging Face) dan simpan di server atau VM cloud Anda sendiri. Apache 2.0 memungkinkan modifikasi dan penggunaan komersial.
- RuntimeGunakan runtime inferensi standar yang mendukung model transformator besar (ONNX Runtime, Triton, atau runtime vendor yang dioptimalkan). Runtime komunitas seperti Ollama dan LM Studio sudah menambahkan dukungan untuk keluarga gpt-oss.
- Perangkat kerasKapasitas 120GB biasanya membutuhkan GPU bermemori tinggi (misalnya, 80GB A100/H100 atau sharding multi-GPU), sementara kapasitas 20GB dapat dijalankan dengan biaya lebih rendah dan memiliki opsi yang dioptimalkan untuk pengaturan VRAM 16GB. Rencanakan kapasitas untuk throughput puncak dan biaya evaluasi multi-kebijakan.
Runtime yang dikelola dan pihak ketiga
Jika menjalankan perangkat keras Anda sendiri tidak praktis, API Komet Dukungan untuk model gpt-oss sedang ditambahkan dengan cepat. Platform ini mungkin menyediakan penskalaan yang lebih mudah, tetapi kembali menghadirkan risiko paparan data pihak ketiga. Evaluasi privasi, SLA, dan kontrol akses sebelum memilih runtime terkelola.
Strategi moderasi yang efektif dengan gpt-oss-safeguard
1) Gunakan jalur hibrida (triase → alasan → putuskan)
- Lapisan triase: Pengklasifikasi (atau aturan) yang kecil dan cepat menyaring kasus-kasus sepele. Hal ini mengurangi beban pada model pengamanan yang mahal.
- Lapisan pengaman: jalankan gpt-oss-safeguard untuk pemeriksaan yang ambigu, berisiko tinggi, atau multi-kebijakan di mana nuansa kebijakan menjadi penting.
- Penghakiman manusia: eskalasi kasus-kasus ekstrem dan banding, menyimpan CoT sebagai bukti transparansi. Desain hibrida ini menyeimbangkan throughput dan presisi.
2) Rekayasa kebijakan (bukan rekayasa cepat)
- Perlakukan kebijakan sebagai artefak perangkat lunak: buat versinya, uji terhadap kumpulan data, dan buat agar tetap eksplisit dan hierarkis.
- Tulis kebijakan dengan contoh dan contoh tandingan. Jika memungkinkan, sertakan instruksi yang memperjelas ambiguitas (misalnya, "Jika maksud pengguna jelas bersifat eksploratif dan historis, beri label X; jika maksudnya operasional dan waktu nyata, beri label Y").
3) Konfigurasikan upaya penalaran secara dinamis
- penggunaan usaha rendah untuk pemrosesan massal dan usaha tinggi untuk konten yang ditandai, banding, atau vertikal berdampak tinggi (hukum, medis, keuangan).
- Sesuaikan ambang batas dengan umpan balik tinjauan manusia untuk menemukan titik optimal dari segi biaya/kualitas.
4) Validasi CoT dan perhatikan penalaran halusinasi
CoT memang berharga, tetapi dapat menimbulkan halusinasi: jejaknya adalah rasional yang dihasilkan model, bukan kebenaran dasar. Audit keluaran CoT secara rutin; instrumen detektor untuk sitasi halusinasi atau penalaran yang tidak sesuai. OpenAI mendokumentasikan rantai pemikiran halusinasi sebagai tantangan yang teramati dan menyarankan strategi mitigasi.
5) Membangun kumpulan data dari operasi sistem
Mencatat keputusan model dan koreksi manusia untuk menciptakan set data berlabel yang dapat meningkatkan pengklasifikasi triase atau menginformasikan penulisan ulang kebijakan. Seiring waktu, set data berlabel yang kecil dan berkualitas tinggi ditambah dengan pengklasifikasi yang efisien sering kali mengurangi ketergantungan pada inferensi CoT penuh untuk konten rutin.
6) Pantau komputasi & biaya; gunakan aliran asinkron
Untuk aplikasi latensi rendah yang dihadapi konsumen, pertimbangkan pemeriksaan keamanan asinkron dengan UX konservatif jangka pendek (misalnya, sembunyikan konten sementara sambil menunggu peninjauan) daripada melakukan CoT yang membutuhkan upaya tinggi secara sinkron. OpenAI mencatat Safety Reasoner menggunakan alur asinkron secara internal untuk mengelola latensi layanan produksi.
7) Pertimbangkan privasi dan lokasi penerapan
Karena bobotnya terbuka, Anda dapat menjalankan inferensi sepenuhnya di tempat untuk mematuhi tata kelola data yang ketat atau mengurangi paparan terhadap API pihak ketiga—yang berharga bagi industri yang diatur.
Kesimpulan:
gpt-oss-safeguard adalah alat yang praktis, transparan, dan fleksibel untuk penalaran keselamatan yang didorong oleh kebijakanItu bersinar saat kamu membutuhkannya keputusan yang dapat diaudit terkait dengan kebijakan eksplisit, ketika kebijakan Anda sering berubah, atau ketika Anda ingin melakukan pemeriksaan keamanan di tempat. Ini adalah tidak Solusi ajaib yang akan secara otomatis menggantikan pengklasifikasi khusus bervolume tinggi—evaluasi OpenAI sendiri menunjukkan bahwa pengklasifikasi khusus yang dilatih pada korpus berlabel besar dapat mengungguli model ini dalam hal akurasi mentah untuk tugas-tugas yang sempit. Sebagai gantinya, perlakukan gpt-oss-safeguard sebagai komponen strategis: mesin penalaran yang dapat dijelaskan di jantung arsitektur keamanan berlapis (triase cepat → penalaran yang dapat dijelaskan → pengawasan manusia).
Mulai
CometAPI adalah platform API terpadu yang menggabungkan lebih dari 500 model AI dari penyedia terkemuka—seperti seri GPT OpenAI, Gemini Google, Claude Anthropic, Midjourney, Suno, dan lainnya—menjadi satu antarmuka yang ramah bagi pengembang. Dengan menawarkan autentikasi yang konsisten, pemformatan permintaan, dan penanganan respons, CometAPI secara drastis menyederhanakan integrasi kapabilitas AI ke dalam aplikasi Anda. Baik Anda sedang membangun chatbot, generator gambar, komposer musik, atau alur kerja analitik berbasis data, CometAPI memungkinkan Anda melakukan iterasi lebih cepat, mengendalikan biaya, dan tetap tidak bergantung pada vendor—semuanya sambil memanfaatkan terobosan terbaru di seluruh ekosistem AI.
Integrasi terbaru gpt-oss-safeguard akan segera muncul di CometAPI, jadi nantikan!Sementara kami menyelesaikan unggahan Model gpt-oss-safeguard, pengembang dapat mengakses API GPT-OSS-20B dan API GPT-OSS-120B melalui CometAPI, versi model terbaru selalu diperbarui dengan situs web resmi. Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda berintegrasi.
Siap untuk berangkat?→ Daftar ke CometAPI hari ini !
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI, ikuti kami di VK, X dan Discord!