

Grok-4-Fast adalah xAI model penalaran hemat biaya baru dirancang untuk membuat penalaran berkualitas tinggi dan kemampuan pencarian web lebih murah dan lebih cepat untuk penggunaan konsumen dan pengembang. xAI memposisikannya sebagai perbatasan penawaran yang mempertahankan kinerja benchmark Grok-4 sambil meningkatkan efisiensi token, dan mengirimkan dua varian yang disesuaikan untuk keduanya pemikiran or tidak beralasan beban kerja.
Fitur utama (daftar cepat)
- Dua varian model:
grok-4-fast-reasoningdangrok-4-fast-non-reasoning(dapat disesuaikan dengan kedalaman vs. kecepatan). - Jendela konteks yang sangat besar: hingga 2,000,000 token, memungkinkan dokumen yang sangat panjang / transkrip multi-jam / alur kerja multi-dokumen.
- Efisiensi token / fokus biaya: laporan xAI ~40% lebih sedikit token berpikir rata-rata versus Grok-4 dan diklaim ~98% pengurangan biaya untuk mencapai kinerja benchmark yang sama (pada metrik yang dilaporkan xAI).
- Integrasi alat asli / penelusuran: dilatih secara menyeluruh dengan RL penggunaan alat untuk penelusuran web/X, eksekusi kode, dan perilaku pencarian agen.
- Panggilan multimodal & fungsi: mendukung gambar dan keluaran terstruktur; pemanggilan fungsi dan format respons terstruktur didukung dalam API.
Detail teknis
Arsitektur penalaran terpadu: Grok-4-Fast menggunakan basis berat model tunggal yang dapat diarahkan ke pemikiran (rantai pemikiran yang panjang) atau tidak beralasan (balasan cepat) melalui perintah sistem atau pemilihan varian, alih-alih mengirimkan dua model backbone yang sepenuhnya terpisah. Hal ini mengurangi latensi peralihan dan biaya token untuk beban kerja campuran.
Pembelajaran penguatan untuk kepadatan kecerdasan: xAI melaporkan penggunaan pembelajaran penguatan skala besar fokus pada kepadatan kecerdasan (memaksimalkan kinerja per token), yang merupakan dasar untuk perolehan efisiensi token yang dinyatakan.
Pengondisian alat dan pencarian agen: Grok-4-Fast dilatih dan dievaluasi pada tugas-tugas yang memerlukan pemanggilan alat (penjelajahan web, pencarian X, eksekusi kode). Model ini disajikan sebagai model yang mahir dalam memilih kapan harus memanggil alat dan bagaimana menyatukan bukti penelusuran menjadi jawaban.
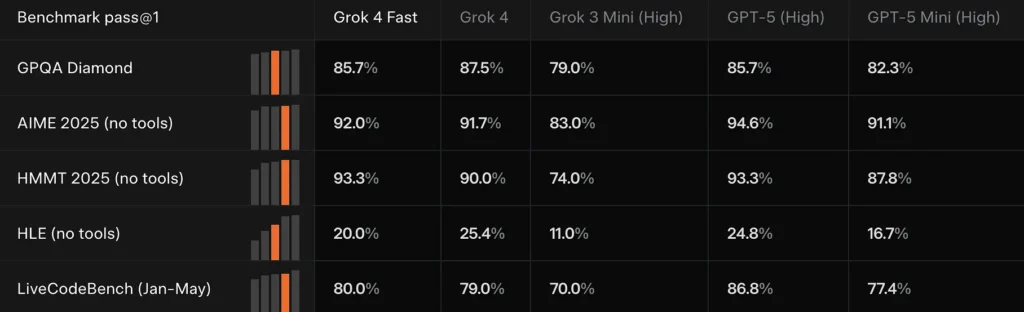
Kinerja tolok ukur
Ipeningkatan di BrowseComp (44.9% lulus @ 1 vs 43.0% untuk Grok-4), SimpleQA (95.0% vs 94.0%), dan keuntungan besar di arena penelusuran/pencarian berbahasa Mandarin tertentu. xAI juga melaporkan peringkat teratas di Arena Pencarian LMArena untuk grok-4-fast-search varian.
Versi model & penamaan
Nama publik yang diumumkan oleh xAI: grok-4-fast-reasoning dan **grok-4-fast-non-reasoning**Setiap varian melaporkan hal yang sama token 2 juta batas konteks. Platform ini juga terus menjadi tuan rumah Grok-4 kapal induk (misalnya, grok-4-0709 varian yang digunakan sebelumnya).
Keterbatasan dan pertimbangan keselamatan
- Kekhawatiran keamanan konten: Laporan dari media investigasi menunjukkan bahwa keluarga Grok xAI (dan beberapa fitur Grok) telah dikembangkan dengan opsi konten yang permisif dan beberapa alur kerja internal membuat para anotator terpapar materi yang sangat mengganggu. Terdapat kekhawatiran yang jelas tentang ketahanan moderasi dan pelaporan kepada pihak berwenang untuk konten ilegal. Masalah keamanan dan kepatuhan ini penting saat menerapkan varian Grok apa pun dalam tahap produksi.
- Verifikasi independen: Banyak klaim kinerja/ekonomi xAI dilaporkan sendiri; tolok ukur independen dan tinjauan sejawat masih dipublikasikan. Perlakukan klaim efisiensi biaya sebagai klaim yang disediakan vendor hingga replikasi pihak ketiga tersedia.
- Risiko operasional: karena Grok-4-Fast dibingkai untuk penelusuran agen, pengguna harus memperhatikan halusinasi, batas kesegaran data (meskipun memiliki kemampuan browsing), dan pribadi pertimbangan saat model digunakan dengan alat eksternal atau kueri web langsung.
Kasus penggunaan umum & yang direkomendasikan
- Pencarian dan pengambilan throughput tinggi — agen pencarian yang memerlukan penalaran web multi-hop yang cepat.
- Asisten agen & bot — agen yang menggabungkan penelusuran, eksekusi kode, dan panggilan alat asinkron (jika diizinkan).
- Penerapan produksi yang sensitif terhadap biaya — layanan yang memerlukan banyak panggilan dan menginginkan peningkatan ekonomi token-ke-utilitas dibandingkan model dasar yang lebih berat.
- Eksperimen pengembang — membuat prototipe aliran multimoda atau yang dilengkapi web yang mengandalkan kueri cepat dan berulang.
Bagaimana cara menelepon grok-4-fast API dari CometAPI
grok-code-fast-1 Harga API di CometAPI, diskon 20% dari harga resmi:
| grok-4-cepat-tanpa-penalaran | Token Masukan: $0.16/M token Token Keluaran: $0.40/M token |
| grok-4-penalaran-cepat | Token Masukan: $0.16/M token Token Keluaran: $0.40/M token |
Langkah-langkah yang Diperlukan
- Masuk ke cometapi.comJika Anda belum menjadi pengguna kami, silakan mendaftar terlebih dahulu
- Dapatkan kunci API kredensial akses antarmuka. Klik “Tambahkan Token” pada token API di pusat personal, dapatkan kunci token: sk-xxxxx dan kirimkan.
Gunakan Metode
- Pilih "
grok-4-fast-reasoning"/"grok-4-fast-reasoningTitik akhir "untuk mengirim permintaan API dan mengatur isi permintaan. Metode dan isi permintaan diperoleh dari dokumen API situs web kami. Situs web kami juga menyediakan uji Apifox untuk kenyamanan Anda. - Mengganti dengan kunci CometAPI Anda yang sebenarnya dari akun Anda.
- Masukkan pertanyaan atau permintaan Anda ke dalam kolom konten—inilah yang akan ditanggapi oleh model.
- Memproses respons API untuk mendapatkan jawaban yang dihasilkan.
CometAPI menyediakan REST API yang sepenuhnya kompatibel—untuk migrasi yang lancar. Detail penting untuk Dokumen API:
- URL dasar: https://api.cometapi.com/v1/chat/completions
- Nama Model:"
grok-4-fast-reasoning"/"grok-4-fast-reasoning" - Otentikasi: Token pembawa melalui
Authorization: Bearer YOUR_CometAPI_API_KEYHeader - Jenis konten:
application/json.
Integrasi API & Contoh
Potongan kode Python untuk Penyelesaian Obrolan panggilan melalui CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-4-fast's main features."}
]
response = openai.ChatCompletion.create(
model="grok-4-fast-reasoning",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Lihat Juga Grok 4