

GLM-5 adalah model fondasi baru berbobot terbuka dari Zhipu AI yang berpusat pada agen, dibangun untuk pengodean jangka panjang dan agen multi-langkah. Model ini tersedia melalui beberapa API terkelola (termasuk CometAPI dan endpoint penyedia) serta sebagai rilis riset dengan kode dan bobot; Anda dapat mengintegrasikannya menggunakan panggilan REST yang kompatibel dengan OpenAI standar, streaming, dan SDK.
Apa itu GLM-5 dari Z.ai?
GLM-5 adalah model fondasi andalan generasi kelima dari Z.ai yang dirancang untuk rekayasa agentik: perencanaan jangka panjang, penggunaan alat multi-langkah, dan perancangan kode/sistem skala besar. Dirilis secara publik pada Februari 2026, GLM-5 adalah model Mixture-of-Experts (MoE) dengan ~744 miliar parameter total dan himpunan parameter aktif sekitar 40B per forward pass; arsitektur dan pilihan pelatihannya memprioritaskan koherensi konteks panjang, pemanggilan alat, dan inferensi hemat biaya untuk beban produksi. Pilihan desain ini memungkinkan GLM-5 menjalankan alur kerja agentik yang panjang (misalnya: jelajah → rencana → tulis/uji kode → iterasi) sambil mempertahankan konteks pada input yang sangat panjang.
Sorotan teknis utama:
- Arsitektur MoE pada ~744B total / ~40B parameter aktif; prapelatihan berskala (~28,5T token dilaporkan) untuk mendekatkan jarak dengan model tertutup terdepan.
- Dukungan konteks panjang dan optimasi (deep sparse attention, DSA) untuk menurunkan biaya deployment dibanding penskalaan dense naif.
- Fitur agentik bawaan: pemanggilan alat/fungsi, dukungan sesi berstatus, dan output terintegrasi (mampu menghasilkan artefak
.docx,.xlsx,.pdfsebagai bagian dari alur kerja agen di UI vendor). - Ketersediaan bobot terbuka (bobot dipublikasikan ke hub model) dan opsi akses terkelola (API vendor, mikroservis inferensi).
Apa keuntungan utama GLM-5?
Perencanaan agentik dan memori jangka panjang
Arsitektur dan penyetelan GLM-5 memprioritaskan penalaran multi-langkah yang konsisten dan memori di seluruh alur kerja — bermanfaat untuk:
- agen otonom (pipeline CI, pengorkestrasi tugas),
- pembuatan/refaktor kode multimapan, dan
- intelijensi dokumen yang perlu menyimpan riwayat besar.
Jendela konteks besar
GLM-5 mendukung ukuran konteks yang sangat besar (sekitar ~200k token dalam spesifikasi model yang dipublikasikan), memungkinkan Anda menyimpan lebih banyak sesi dalam satu permintaan dan mengurangi kebutuhan chunking agresif atau memori eksternal untuk banyak use case. (Lihat bagan perbandingan di bawah.)
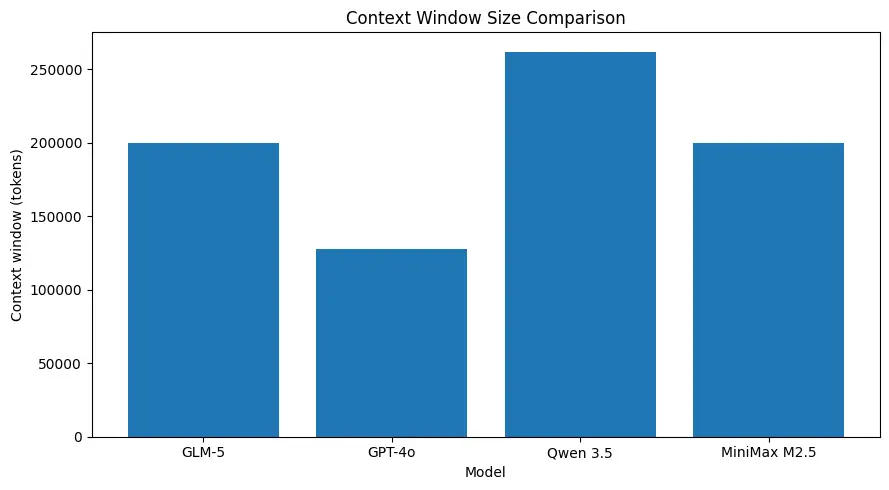
Kinerja pengodean yang kuat untuk tugas tingkat sistem
GLM-5 melaporkan kinerja sumber terbuka teratas pada tolok ukur rekayasa perangkat lunak (SWE-bench dan suite kode + agen terapan). Pada SWE-bench-Verified dilaporkan ~77,8%; pada pengujian agen bergaya pengodean/terminal (Terminal-Bench 2.0) skor berkisar di pertengahan 50-an — bukti kemampuan pengodean praktis yang mendekati model proprietari terdepan. Metrik ini berarti GLM-5 cocok untuk tugas seperti pembuatan kode, refaktorisasi otomatis, penalaran berkas jamak, dan skenario asisten CI/CD.
Kompromi biaya/efisiensi
Karena GLM-5 menggunakan MoE dan inovasi perhatian "sparse", model ini bertujuan menurunkan biaya inferensi per unit kapabilitas dibandingkan penskalaan dense secara brute-force. CometAPI menyediakan titik harga yang kompetitif yang membuat GLM-5 menarik untuk beban kerja agentik ber-throughput tinggi.
Bagaimana cara menggunakan API GLM-5 melalui CometAPI?
Jawaban singkat: perlakukan CometAPI seperti gerbang yang kompatibel dengan OpenAI — atur base URL dan kunci API Anda, pilih glm-5 sebagai model, lalu panggil endpoint chat/completions. CometAPI menyediakan permukaan REST bergaya OpenAI (endpoint seperti /v1/chat/completions) plus SDK dan proyek contoh yang membuat migrasi menjadi sepele.
Di bawah ini adalah panduan praktis berorientasi produksi: autentikasi, panggilan chat dasar, streaming, pemanggilan fungsi/alat, serta penanganan biaya/respons.
Langkah dasar untuk mengakses GLM-5 via CometAPI:
- Daftar di CometAPI, dapatkan kunci API.
- Temukan id model yang tepat untuk GLM-5 di katalog CometAPI (
"glm-5"tergantung listing). - Kirim permintaan POST terautentikasi ke endpoint chat/completions CometAPI (gaya OpenAI).
Detail dasar (pola CometAPI): platform ini mendukung jalur bergaya OpenAI seperti https://api.cometapi.com/v1/chat/completions, autentikasi Bearer, parameter model, pesan system/user, streaming, serta contoh curl/python dalam dokumentasi.
Contoh: penyelesaian chat Python cepat (requests) dengan GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Contoh: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Respons streaming (pola praktis)
CometAPI mendukung streaming bergaya OpenAI (SSE/chunked). Pendekatan paling sederhana di Python adalah meminta "stream": true dan mengiterasi data respons saat tiba. Ini penting ketika Anda memerlukan keluaran parsial berlatensi rendah (membangun asisten pengembang real-time, UI streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Referensi: dokumentasi streaming bergaya OpenAI dan kompatibilitas CometAPI.
Pemanggilan fungsi/alat (cara memanggil alat eksternal)
GLM-5 mendukung pola pemanggilan fungsi atau alat yang kompatibel dengan OpenAI/aggregator (gateway meneruskan pemanggilan fungsi terstruktur dalam respons model). Contoh use case: minta GLM-5 memanggil alat lokal “run_tests”; model mengembalikan instruksi terstruktur yang dapat Anda uraikan dan eksekusi.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Saat model mengembalikan muatan function_call, jalankan alat di sisi server, lalu umpankan hasil alat kembali sebagai pesan dengan role "tool" dan lanjutkan percakapan. Pola ini memungkinkan pemanggilan alat yang aman dan alur agen berstatus. Lihat dokumentasi dan contoh CometAPI untuk helper SDK yang konkret.
Parameter dan penyetelan praktis
function_call: gunakan untuk mengaktifkan pemanggilan alat terstruktur dan alur eksekusi yang lebih aman.
temperature: 0–0,3 untuk keluaran tingkat sistem yang deterministik (kode, infra), lebih tinggi untuk ideasi.
max_tokens: atur untuk panjang keluaran yang diharapkan; GLM-5 mendukung keluaran sangat panjang saat di-host (batas vendor bervariasi).
top_p / nucleus sampling: berguna untuk membatasi ekor yang tidak mungkin.
stream: true untuk UI interaktif.
Perbandingan GLM-5 dengan Claude Opus milik Anthropic dan model frontier lainnya
Jawaban singkat: GLM-5 mendekatkan jarak dengan model tertutup terdepan pada tolok ukur agentik dan pengodean, sekaligus menawarkan deployment bobot terbuka dan sering kali biaya per token yang lebih baik saat di-host oleh aggregator. Nuansanya: pada beberapa tolok ukur pengodean absolut (SWE-bench, varian Terminal-Bench) Claude Opus (4.5/4.6) dari Anthropic masih unggul beberapa poin di banyak papan peringkat yang dipublikasikan — tetapi GLM-5 sangat kompetitif dan mengungguli banyak model terbuka lainnya.
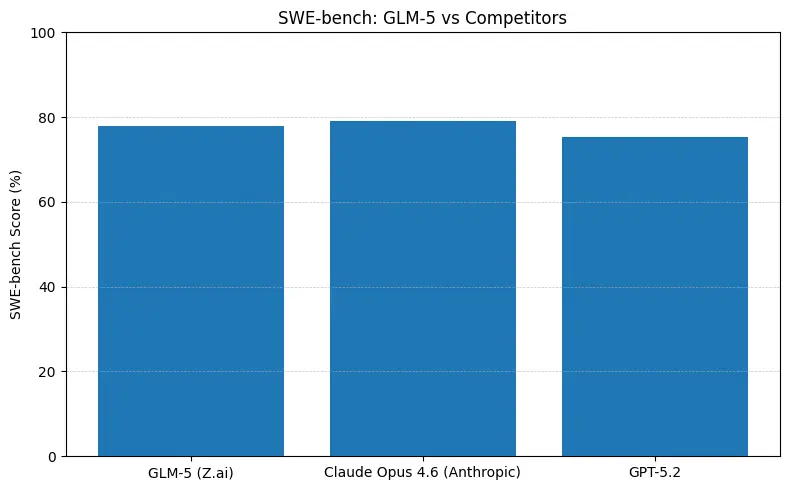
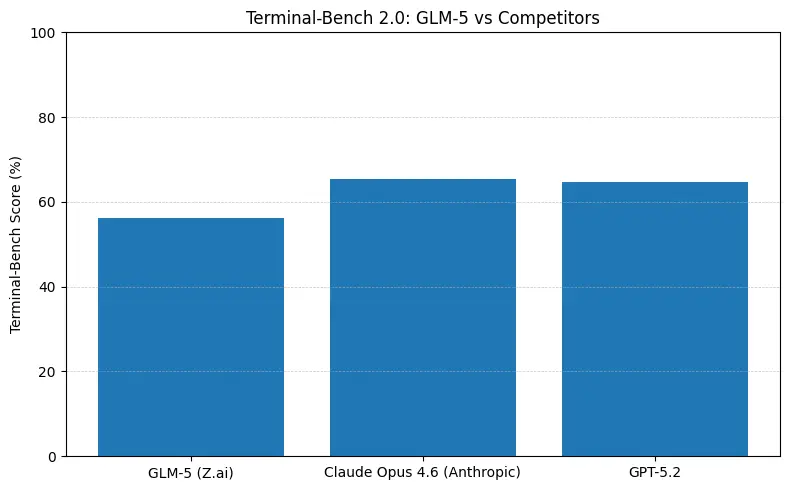
Apa arti angka-angka tersebut dalam praktik
- SWE-bench (~kebenaran kode/rekayasa): Claude Opus menunjukkan keunggulan tipis (≈79% vs GLM-5 ≈77,8%) pada papan peringkat yang dipublikasikan; untuk banyak tugas nyata, celah itu akan berujung pada lebih sedikit pengeditan manual, tetapi tidak selalu mengharuskan pilihan arsitektur berbeda untuk prototipe atau alur kerja agentik berskala.
- Terminal-Bench (tugas agentik command-line): Opus 4.6 memimpin (≈65,4% vs GLM-5 ≈56,2%) — jika Anda memerlukan otomasi terminal yang tangguh dan keandalan tertinggi pada operasi shell di luar distribusi, Opus sering lebih baik pada margin.
- Agentik dan jangka panjang: GLM-5 berkinerja sangat baik pada simulasi bisnis jangka panjang (Vending-Bench 2 saldo $4.432 dilaporkan) dan menunjukkan koherensi perencanaan yang kuat untuk alur kerja multi-langkah. Jika produk Anda adalah agen yang berjalan lama (keuangan, operasional), GLM-5 kuat.
Bagaimana saya merancang prompt dan sistem untuk mendapatkan keluaran GLM-5 yang andal?
Pesan sistem & batasan eksplisit
Berikan GLM-5 peran dan batasan yang ketat, terutama untuk tugas kode atau pemanggilan alat. Contoh:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Minta pengujian dan penalaran singkat untuk setiap perubahan yang tidak sepele.
Uraikan tugas-tugas kompleks
Alih-alih “tulis seluruh produk,” mintalah:
- garis besar desain,
- tanda tangan antarmuka,
- implementasi dan pengujian,
- skrip integrasi akhir.
Dekomposisi bertahap ini mengurangi halusinasi dan memberikan titik pemeriksaan deterministik yang bisa Anda validasi.
Gunakan temperature rendah untuk kode deterministik
Saat meminta kode, atur temperature = 0–0,2 dan max_tokens ke batas atas yang aman. Untuk penulisan kreatif atau brainstorming desain, naikkan temperature.
Praktik terbaik saat mengintegrasikan GLM-5 (melalui CometAPI atau host langsung)
Rekayasa prompt & prompt sistem
- Gunakan instruksi sistem eksplisit yang mendefinisikan peran agen, kebijakan akses alat, dan batasan keamanan. Contoh: “Anda adalah arsitek sistem: hanya usulkan perubahan ketika unit test lulus secara lokal; cantumkan perintah CLI persis yang akan dijalankan.”
- Untuk tugas pengodean, berikan konteks repositori (daftar berkas, cuplikan kode kunci) dan lampirkan hasil unit test jika ada. Penanganan konteks panjang GLM-5 membantu — tetapi selalu letakkan konteks esensial terlebih dahulu (peran, tugas) lalu artefak pendukung.
Manajemen sesi & status
- Gunakan ID sesi untuk percakapan agen yang panjang dan simpan “memori” langkah sebelumnya yang dipadatkan (ringkasan) untuk mencegah pembengkakan konteks. CometAPI dan gateway serupa menyediakan helper sesi/status — tetapi pemadatan status di tingkat aplikasi sangat penting untuk agen yang berjalan lama.
Perkakas & pemanggilan fungsi (keamanan + keandalan)
- Ekspos himpunan alat yang sempit dan dapat diaudit. Jangan izinkan eksekusi shell sewenang-wenang tanpa pengawasan manusia. Gunakan definisi fungsi terstruktur dan validasi argumennya di sisi server.
- Selalu log pemanggilan alat dan respons model untuk keterlacakan dan debugging pascainsiden.
Pengendalian biaya & batching
- Untuk agen volume tinggi, alihkan pemrosesan background ke varian model yang lebih murah saat kompromi kualitas dapat diterima (CometAPI memungkinkan Anda mengganti model berdasarkan nama). Batch permintaan serupa dan kurangi
max_tokensjika memungkinkan. Pantau rasio token input vs output — token output sering kali lebih mahal.
Rekayasa latensi & throughput
- Gunakan streaming untuk sesi interaktif. Untuk pekerjaan agen background, gunakan runtime async, antrean pekerja, dan rate-limiter. Jika Anda meng-host sendiri (bobot terbuka), sesuaikan topologi akselerator dengan arsitektur MoE — opsi FPGA/Ascend/silikon khusus dapat memberi keuntungan biaya.
Catatan penutup
GLM-5 merepresentasikan langkah praktis berbobot terbuka menuju rekayasa agentik: jendela konteks besar, kapabilitas perencanaan, dan kinerja kode yang kuat membuatnya menarik untuk alat pengembang, orkestrasi agen, dan otomasi tingkat sistem. Gunakan CometAPI untuk integrasi cepat atau taman model cloud untuk hosting terkelola; selalu validasi pada beban kerja Anda dan instrumentasi secara intensif untuk pengendalian biaya dan halusinasi.
Pengembang dapat mengakses GLM-5 via CometAPI sekarang. Untuk memulai, jelajahi kapabilitas model di Playground dan lihat Panduan API untuk instruksi terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga jauh di bawah harga resmi untuk membantu Anda berintegrasi.
Siap Mulai?→ Sign up fo M2.5 today!
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI, ikuti kami di VK, X dan Discord!