

Z.ai (sebelumnya Zhipu AI) asal Tiongkok kembali menjadi berita utama dengan peluncuran Seri GLM 4.5 sumber terbukanya. Diposisikan sebagai alternatif yang hemat biaya dan berkinerja tinggi untuk model bahasa besar yang ada, GLM‑4.5 berjanji untuk membentuk kembali ekonomi token dan mendemokratisasi akses bagi perusahaan rintisan, perusahaan, dan lembaga penelitian. Artikel komprehensif ini mengeksplorasi asal-usul, struktur harga, dan nilai dunia nyata Seri GLM‑4.5—menjawab dua pertanyaan kunci yang ada di benak setiap pemangku kepentingan: berapa biayanya, dan apakah sepadan?
Apa itu Seri GLM 4.5?
Seri GLM 4.5 Z.ai dibangun di atas kerangka kerja AI "agentik", yang berarti model ini dapat secara otomatis menguraikan tugas-tugas kompleks menjadi sub-tugas yang lebih kecil dan berurutan—meningkatkan presisi dan mengurangi komputasi redundan. Hal ini berbeda dengan LLM yang lebih monolitik yang menangani perintah dalam satu lintasan. Menurut Z.ai, GLM 4.5 secara native menanamkan penalaran dan perencanaan tindakan dalam arsitektur intinya, memungkinkan alur kerja multi-langkah seperti pembuatan visualisasi data atau pemrosesan dokumen menyeluruh tanpa orkestrasi eksternal.
Seri GLM 4.5, yang dikembangkan oleh Z.ai, mewakili generasi terbaru model bahasa besar sumber terbuka Mixture-of-Experts (MoE) yang dirancang untuk menyatukan penalaran tingkat lanjut, pembuatan kode, dan kapabilitas agen dalam satu arsitektur. Seri ini hadir dalam dua varian utama: model unggulan GLM 4.5 (355 B total parameter, 32 B aktif) dan lebih ringan GLM 4.5‑Udara (106 B total, 12 B aktif). Kedua varian memanfaatkan mekanisme inferensi hibrida—"mode berpikir" untuk penalaran kompleks yang didukung alat dan "mode non-berpikir" untuk penyelesaian yang cepat dan lugas—yang melayani spektrum luas kasus penggunaan, mulai dari pengembangan tumpukan penuh hingga alur kerja agen otonom.
spesifikasi teknis inti:
- Parameter Teknis: GLM 4.5 menghadirkan 355 miliar parameter, dengan subset aktif sebanyak 32 miliar yang terlibat per inferensi untuk mengoptimalkan penggunaan perangkat keras dan throughput.
- Campuran Pakar (MoE):Seri ini memanfaatkan arsitektur MoE, merutekan token ke sub-jaringan ahli secara dinamis untuk efisiensi.
- Jendela Konteks: Diperluas hingga 128 K token pada platform tertentu (misalnya, SiliconFlow), mengakomodasi dokumen dan basis kode besar.
- Kecepatan Generasi: Varian kecepatan tinggi melebihi 100 token/detik, cocok untuk aplikasi waktu nyata.
- Mode Inferensi Hibrida:Pengguna dapat beralih antara mode “berpikir” (aktivasi MoE penuh untuk penalaran mendalam) dan mode “tidak berpikir” (aktivasi minimal untuk respons cepat dan spontan), yang memberikan pengembang kontrol yang sangat rinci atas kinerja versus kecepatan.
Varian apa saja yang ada dalam Seri ini?
- GLM 4.5 (Standar): 355 B total / 32 B parameter aktif. Dirancang terutama untuk kinerja yang seimbang di seluruh tugas penalaran, pengodean, dan agensi.
- GLM 4.5‑Udara: Versi ringan dengan total 106 B / parameter aktif 12 B, dirancang khusus untuk skenario dengan kendala perangkat keras atau latensi yang ketat—memberikan akurasi yang kompetitif di kelasnya.
Berapa harga Seri GLM 4.5?
Berapa harga token input dan output?
Menurut pengungkapan harga API publik Z.ai, GLM 4.5 dihargai:
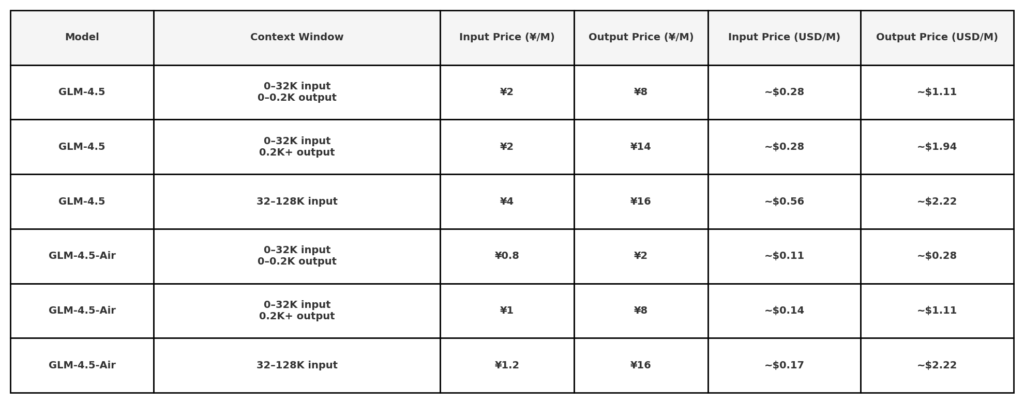
Catatan: tarif yang sangat rendah ($0.11/$0.28) mungkin terbatas pada panjang token kecil atau promosi tertentu. Diskon 50% untuk semua model untuk waktu terbatas, berlaku hingga 31 Agustus 2025. model lain merujuk ke halaman harga kantor.
Pada CometAPI, Seri ini dibundel dengan harga berjenjang yang sedikit berbeda, lihat API GLM‑4.5:
| Pilih Model | memperkenalkan | Harga |
glm-4.5 | Model penalaran kita yang paling kuat, dengan 355 miliar parameter | Token Masukan $0.48 Token Keluaran $1.92 |
glm-4.5-air | Hemat Biaya Ringan Performa Kuat | Token Masukan $0.16 Token Keluaran $1.07 |
glm-4.5-x | Performa Tinggi Penalaran Kuat Respons Sangat Cepat | Token Masukan $1.60 Token Keluaran $6.40 |
glm-4.5-airx | Ringan, Performa Kuat, Respons Sangat Cepat | Token Masukan $0.02 Token Keluaran $0.06 |
glm-4.5-flash | Performa Kuat Sangat Baik untuk Penalaran Coding & Agen | Token Masukan $3.20 Token Keluaran $12.80 |
Bagaimana harga GLM 4.5 dibandingkan dengan DeepSeek dan Western LLM?
Pada Konferensi AI Dunia 2025, Z.ai secara eksplisit memposisikan GLM 4.5 sebagai penantang DeepSeek—pemimpin biaya sebelumnya di Tiongkok—yang menjanjikan “sebagian kecil biaya token” dan setengah jejak perangkat keras dari model R1 DeepSeek.
- Pencarian Mendalam R1: Sekitar USD 0.14 masukan, USD 0.60 keluaran per juta token.
- GLM 4.5: Diklaim mampu mengalahkan DeepSeek sebesar 20–30% pada input dan output.
- Tolok Ukur Barat:GPT‑4 milik OpenAI dan Gemini milik Google berkisar antara USD 3–15 per juta token, memposisikan GLM 4.5 sebagai pengurangan biaya sebesar satu orde besarnya.
Strategi penetapan harga ini mencerminkan model ekonomi AI China yang lebih luas: komputasi yang lebih ramping, model yang lebih kecil, dan penawaran harga yang agresif untuk merebut pangsa pasar.
Apakah Seri GLM 4.5 Layak Dibeli?
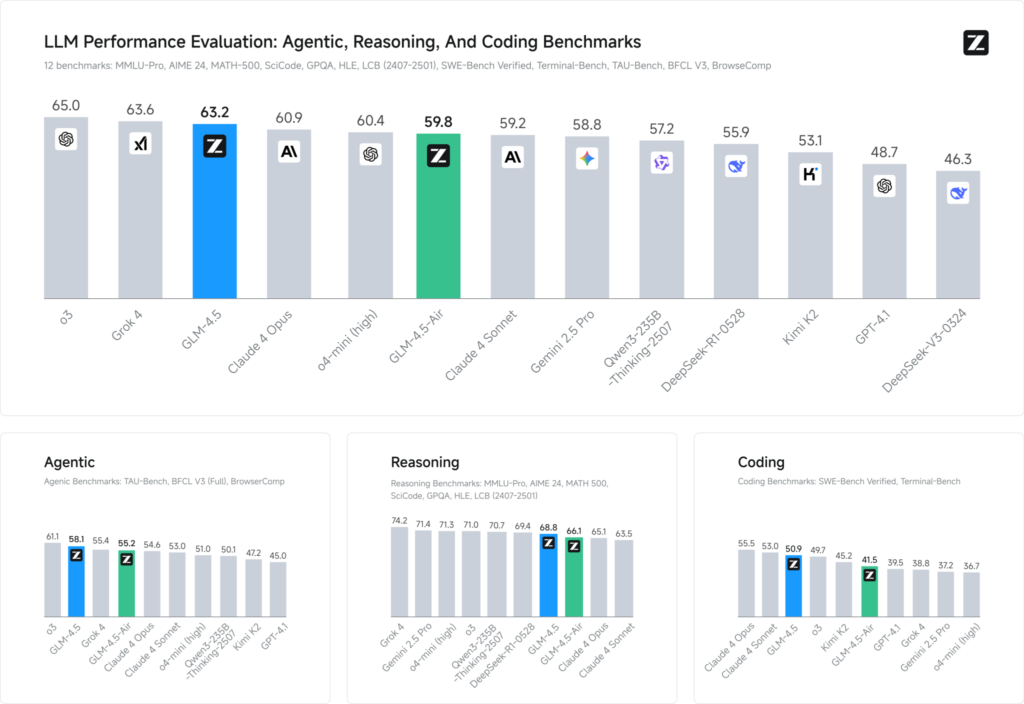
Evaluasi tolok ukur pada 12 set data representatif (mencakup MMLU Pro, MATH 500, SciCode, Terminal‑Bench, dan TAU‑Bench) mengungkapkan bahwa GLM 4.5 mengamankan peringkat global #3 di belakang Grok 4 milik xAI dan o3 milik OpenAI—namun tetap menempati peringkat #1 di antara penawaran sumber terbuka.
Dalam tugas pengkodean (LiveCodeBench, SWE‑Bench), desain Mixture‑of‑Experts pada GLM 4.5 berkontribusi pada kualitas pembuatan kode terbaik, sementara dalam penalaran (AIME 24, MMLU Pro), perencanaan multi-langkahnya menghasilkan akurasi yang tangguh, sebanding dengan rekan-rekan sumber tertutupnya. Varian Air yang ringan mempertahankan skor kompetitif dalam rentang parameternya (skala 100 B), menjadikannya pilihan yang menarik untuk penerapan edge dan sistem tertanam.
Tolok Ukur Kinerja
- Indeks Kecerdasan: Skor GLM 4.5 66 pada Indeks Kecerdasan komposit (MMLU Pro, MATH 500, AIME 24), melampaui banyak model menengah komersial dan sumber terbuka.
- Latensi Inferensi: Rata-rata waktu hingga token pertama 0.89 detik, kompetitif untuk tugas penalaran yang kompleks, meskipun sedikit lebih lambat dalam throughput (≈45.7 token/s) dibandingkan dengan beberapa model sumber tertutup yang dioptimalkan.
- Alur Kerja Agen: : Menunjukkan penguasaan yang kuat terhadap penggunaan alat multi-langkah dan pembuatan kode dinamis, dengan tingkat kemenangan head-to-head ~54% melawan Kimi K2 dan 81% menentang Qwen3‑Coder dalam evaluasi pengkodean independen.
Kasus penggunaan praktis apa yang menunjukkan ROI?
- Pengembangan Tumpukan Penuh: GLM‑4.5 dapat membangun seluruh aplikasi web—dari tata letak frontend dalam HTML/CSS/JavaScript hingga skema basis data backend—melalui perintah multi‑putaran, memangkas siklus pembuatan prototipe dari hitungan hari menjadi jam.
- Analisis Dokumen Kompleks:Jendela konteks 128 K yang diperluas memberdayakan firma hukum, keuangan, dan ilmiah untuk mengurai kontrak multi-halaman atau laporan penelitian sekaligus, mengurangi overhead segmentasi.
- Alur Kerja Agen Otomatis:Inferensi hibrida memungkinkan pembuatan skrip otonom (misalnya, bot pengikis web, agen perdagangan) yang bernalar melalui proses multi-langkah dengan campur tangan manusia yang minimal.
Studi kasus kuantitatif menunjukkan hingga 60 persen pengurangan jam kerja pengembang untuk tugas-tugas yang berpusat pada kode dan 40 persen penyelesaian yang lebih cepat pada analisis konten bentuk panjang.
Apa Saja Potensi Kekurangan dan Pertimbangannya?
Tidak ada teknologi yang tanpa kompromi. Calon pengadopsi harus memperhatikan faktor regulasi, operasional, dan ekosistem.
keterbatasan
Dukungan & SLA:Penyedia sumber terbuka mungkin tidak menawarkan SLA tingkat perusahaan atau dukungan 24/7, tidak seperti rekan komersial.
Batasan Throughput:Meskipun jendela konteksnya sangat besar, kecepatan token per detik tertinggal dibandingkan beberapa padanan sumber tertutup yang dioptimalkan untuk inferensi, sehingga berpotensi memengaruhi aplikasi waktu nyata.
Biaya Operasional:Model MoE yang dihosting sendiri memerlukan orkestrasi yang cermat (perutean ahli, manajemen memori) untuk menghindari kemacetan kinerja dan pembengkakan biaya.
Investasi infrastruktur apa yang dibutuhkan?
- Jejak Komputasi: Bahkan dengan efisiensi MoE, hosting varian standar GLM‑4.5 menuntut GPU dengan memori ≥80 GB dan interkoneksi NVLink yang kuat untuk inferensi latensi rendah.
- Penyetelan Halus Overhead: Menyesuaikan model untuk tugas spesifik domain mungkin memerlukan siklus GPU yang besar, sehingga meningkatkan biaya awal sebelum penghematan penagihan token terwujud.
- Pemeliharaan: Penerapan di lokasi mengalihkan tanggung jawab atas pembaruan, patch keamanan, dan penskalaan dari vendor ke tim DevOps internal.
Bagaimana Anda Bisa Memulai dengan GLM‑4.5?
Memulai integrasi GLM‑4.5 melibatkan beberapa langkah mudah—terutama mengingat buku pedoman sumber terbuka dan dukungan pihak ketiga yang luas.
API dan platform mana yang mendukung GLM‑4.5?
- API Komet API: Titik akhir yang sepenuhnya kompatibel dengan OpenAI, menampilkan SDK dalam Python, JavaScript, dan Java.
- Titik Akhir Z.ai Langsung: Menawarkan dukungan resmi dan fitur akses awal seperti orkestrasi multiagen.
- Cermin Komunitas: Host runtime sumber terbuka yang berkembang pesat (misalnya, Ollama, AutoGPT‑CLI) yang memungkinkan inferensi lokal.
Di mana pengembang dapat menemukan perkakas dan dokumentasi?
- Dokumen Resmi Z.ai: Panduan lengkap tentang instalasi, rekayasa cepat, dan pengoptimalan MoE.
- Repositori GitHub: Buku catatan contoh untuk pembuatan kode, pembuatan tambahan pengambilan (RAG), dan kerangka kerja agen yang kompatibel dengan alat orkestrasi utama.
- Forum Komunitas: Papan diskusi aktif pada platform seperti Hugging Face, tempat para praktisi berbagi resep penyempurnaan, pustaka perintah, dan tolok ukur kinerja.
Kesimpulan
Seri GLM‑4.5 mengukuhkan klaim yang berani di lanskap AI yang sangat kompetitif saat ini: kinerja biaya yang tak tertandingi bagi pengembang, perusahaan, dan lembaga riset. Dengan harga token serendah $0.11 per juta token input dan $0.28 per juta token output—yang selanjutnya dipangkas dengan diskon promosi 50 persen—dan kinerja benchmark yang menyaingi atau bahkan melampaui model proprietary yang lebih besar, GLM‑4.5 memberikan ROI yang substansial untuk aplikasi yang berpusat pada kode, pemahaman bentuk panjang, dan alur kerja agensi.
Mulai
CometAPI adalah platform API terpadu yang menggabungkan lebih dari 500 model AI dari penyedia terkemuka—seperti seri GPT OpenAI, Gemini Google, Claude Anthropic, Midjourney, Suno, dan lainnya—menjadi satu antarmuka yang ramah bagi pengembang. Dengan menawarkan autentikasi yang konsisten, pemformatan permintaan, dan penanganan respons, CometAPI secara drastis menyederhanakan integrasi kapabilitas AI ke dalam aplikasi Anda. Baik Anda sedang membangun chatbot, generator gambar, komposer musik, atau alur kerja analitik berbasis data, CometAPI memungkinkan Anda melakukan iterasi lebih cepat, mengendalikan biaya, dan tetap tidak bergantung pada vendor—semuanya sambil memanfaatkan terobosan terbaru di seluruh ekosistem AI.
Pengembang dapat mengakses GLM-4.5 Air API dan API GLM‑4.5 melalui API Komet, versi terbaru model Claude yang tercantum adalah per tanggal publikasi artikel. Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda berintegrasi.