

Memulai dengan Gemini 2.5 Flash-Lite melalui CometAPI merupakan peluang yang menarik untuk memanfaatkan salah satu model AI generatif yang paling hemat biaya dan berlatensi rendah yang tersedia saat ini. Panduan ini menggabungkan pengumuman terbaru dari Google DeepMind, spesifikasi terperinci dari dokumentasi Vertex AI, dan langkah-langkah integrasi praktis menggunakan CometAPI untuk membantu Anda memulai dan menjalankannya dengan cepat dan efektif.
Apa itu Gemini 2.5 Flash-Lite dan mengapa Anda harus mempertimbangkannya?
Tinjauan umum keluarga Gemini 2.5
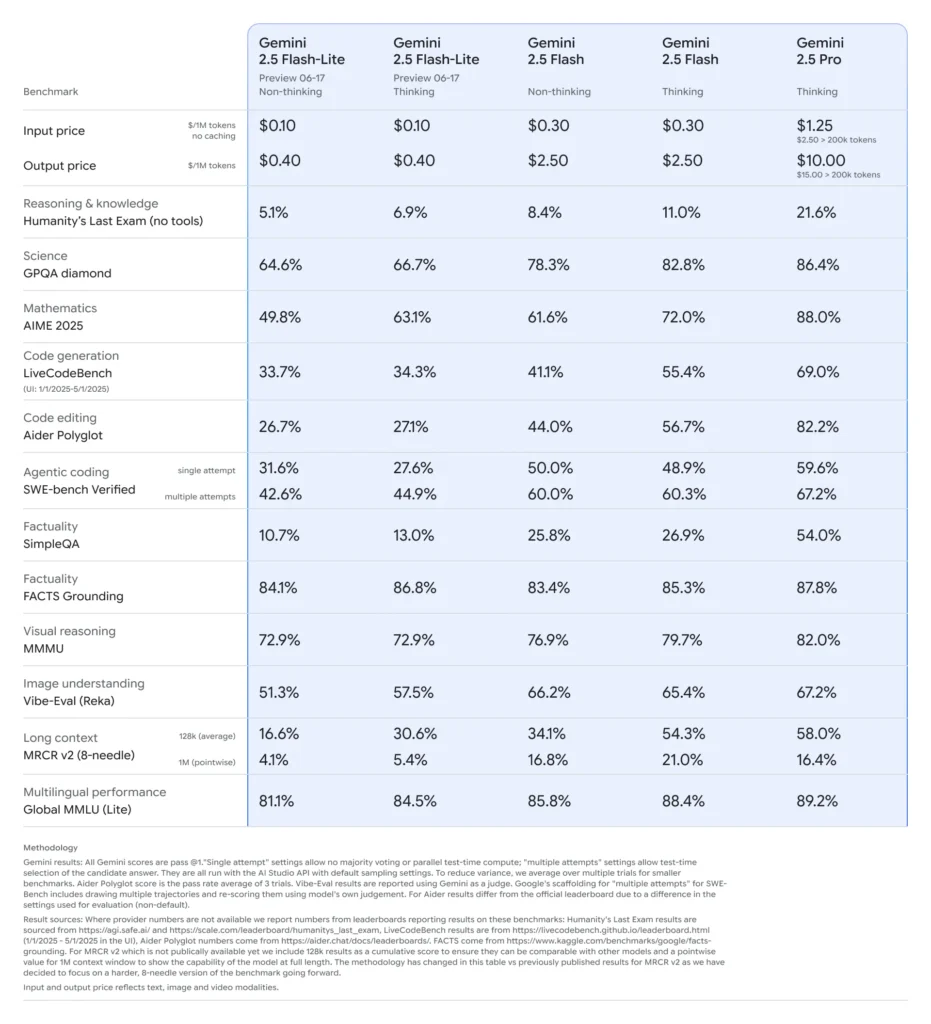
Pada pertengahan Juni 2025, Google DeepMind resmi merilis seri Gemini 2.5, termasuk versi GA stabil Gemini 2.5 Pro dan Gemini 2.5 Flash, bersamaan dengan pratinjau model baru yang ringan: Gemini 2.5 Flash-Lite. Dirancang untuk menyeimbangkan kecepatan, biaya, dan performa, seri 2.5 merupakan upaya Google untuk memenuhi berbagai macam kasus penggunaan—mulai dari beban kerja penelitian berat hingga penerapan berskala besar yang sensitif terhadap biaya.
Karakteristik utama Flash-Lite
Flash-Lite membedakan dirinya dengan menawarkan kemampuan multi-moda (teks, gambar, audio, video) pada latensi yang sangat rendah, dengan jendela konteks yang mendukung hingga satu juta token dan integrasi alat termasuk Google Search, eksekusi kode, dan pemanggilan fungsi. Yang terpenting, Flash-Lite memperkenalkan kontrol "anggaran pemikiran", yang memungkinkan pengembang untuk mempertimbangkan kedalaman penalaran dengan waktu respons dan biaya dengan menyesuaikan parameter anggaran token internal.
Posisi di jajaran model
Jika dibandingkan dengan saudaranya, Flash-Lite berada di garis batas efisiensi biaya Pareto: dengan harga sekitar $0.10 per juta token input dan $0.40 per juta token output selama pratinjau, Flash-Lite lebih murah daripada Flash (dengan harga $0.30/$2.50) dan Pro (dengan harga $1.25/$10) sambil mempertahankan sebagian besar kecakapan multi-moda dan dukungan pemanggilan fungsi. Hal ini menjadikan Flash-Lite ideal untuk tugas-tugas bervolume tinggi dan kompleksitas rendah seperti peringkasan, klasifikasi, dan agen percakapan ringan.
Mengapa pengembang harus mempertimbangkan Gemini 2.5 Flash-Lite?
Tolok ukur kinerja dan pengujian dunia nyata
Dalam perbandingan langsung, Flash-Lite menunjukkan:
- Throughput 2x lebih cepat daripada Gemini 2.5 Flash pada tugas klasifikasi.
- Penghematan biaya 3x untuk jalur ringkasan pada skala perusahaan.
- Akurasi kompetitif pada tolok ukur logika, matematika, dan kode, menyamai atau melampaui pratinjau Flash-Lite sebelumnya.
Kasus penggunaan yang ideal
- Chatbot bervolume tinggi: Memberikan pengalaman percakapan yang konsisten dan latensi rendah kepada jutaan pengguna.
- Pembuatan konten otomatis: Ringkasan dokumen skala, penerjemahan, dan pembuatan salinan mikro.
- Jalur pencarian dan rekomendasi: Memanfaatkan inferensi cepat untuk personalisasi waktu nyata.
- Pemrosesan data batch: Memberi anotasi pada himpunan data besar dengan biaya komputasi minimal.
Bagaimana Anda memperoleh dan mengelola akses API untuk Gemini 2.5 Flash-Lite melalui CometAPI?
Mengapa menggunakan CometAPI sebagai gerbang Anda?
CometAPI menggabungkan lebih dari 500 model AI—termasuk seri Gemini Google—di bawah titik akhir REST terpadu, menyederhanakan autentikasi, pembatasan tarif, dan penagihan di seluruh penyedia. Daripada menangani beberapa URL dasar dan kunci API, Anda mengarahkan semua permintaan ke https://api.cometapi.com/v1, tentukan model target dalam muatan, dan kelola penggunaan melalui satu dasbor.
Prasyarat dan pendaftaran
- Masuk ke cometapi.comJika Anda belum menjadi pengguna kami, silakan mendaftar terlebih dahulu
- Dapatkan kunci API kredensial akses antarmuka. Klik “Tambahkan Token” pada token API di pusat personal, dapatkan kunci token: sk-xxxxx dan kirimkan.
- Dapatkan url situs ini: https://api.cometapi.com/
Mengelola token dan kuota Anda
Dasbor CometAPI menyediakan kuota token terpadu yang dapat dibagikan di seluruh Google, OpenAI, Anthropic, dan model lainnya. Gunakan alat pemantauan bawaan untuk menetapkan peringatan penggunaan dan batas tarif sehingga Anda tidak akan pernah melampaui alokasi anggaran atau dikenakan biaya tak terduga.
Bagaimana Anda mengonfigurasi lingkungan pengembangan Anda untuk integrasi CometAPI?
Menginstal dependensi yang diperlukan
Untuk integrasi Python, instal paket berikut:
pip install openai requests pillow
- openai: SDK yang kompatibel untuk berkomunikasi dengan CometAPI.
- permintaan: Untuk operasi HTTP seperti mengunduh gambar.
- bantal: Untuk penanganan gambar saat mengirim input multi-modal.
Menginisialisasi klien CometAPI
Gunakan variabel lingkungan untuk menjaga kunci API Anda keluar dari kode sumber:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Instans klien ini sekarang dapat menargetkan model apa pun yang didukung dengan menentukan ID-nya (misalnya, gemini-2.5-flash-lite-preview-06-17) dalam permintaan Anda.
Mengonfigurasi anggaran pemikiran dan parameter lainnya
Saat Anda mengirim permintaan, Anda dapat menyertakan parameter opsional:
- suhu/atas_p: Mengontrol keacakan dalam pembangkitan.
- jumlahkandidat: Jumlah keluaran alternatif.
- max_tokens: Batasan token keluaran.
- anggaran_pikiran: Parameter khusus untuk Flash-Lite untuk mengorbankan kedalaman demi kecepatan dan biaya.
Seperti apa permintaan dasar ke Gemini 2.5 Flash-Lite melalui CometAPI?
Contoh hanya teks
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Panggilan ini mengembalikan ringkasan ringkas dalam waktu kurang dari 200 ms, ideal untuk chatbot atau jalur analitik waktu nyata.
Contoh masukan multi-modal
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite memproses hingga 7 MB gambar dan mengembalikan deskripsi kontekstual, membuatnya cocok untuk pemahaman dokumen, analisis UI, dan pelaporan otomatis.
Bagaimana Anda dapat memanfaatkan fitur-fitur canggih seperti streaming dan pemanggilan fungsi?
Respons streaming untuk aplikasi waktu nyata
Untuk antarmuka chatbot atau teks langsung, gunakan API streaming:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Ini memberikan keluaran parsial saat tersedia, mengurangi latensi yang dirasakan dalam UI interaktif.
Fungsi yang memanggil keluaran data terstruktur
Tentukan skema JSON untuk menerapkan respons terstruktur:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Pendekatan ini menjamin keluaran yang sesuai dengan JSON, menyederhanakan jalur data hilir dan integrasi.
Bagaimana Anda mengoptimalkan kinerja, biaya, dan keandalan saat menggunakan Gemini 2.5 Flash-Lite?
Pemikiran penyesuaian anggaran
Parameter anggaran pemikiran Flash-Lite memungkinkan Anda mengatur jumlah "upaya kognitif" yang dikeluarkan model. Anggaran rendah (misalnya, 0) memprioritaskan kecepatan dan biaya, sementara nilai yang lebih tinggi menghasilkan penalaran yang lebih mendalam dengan mengorbankan latensi dan token.
Mengelola batas token dan troughput
- Token masukan: Hingga 1,048,576 token per permintaan.
- Token keluaranBatas default 65,536 token.
- Masukan multimoda: Hingga 500 MB di seluruh aset gambar, audio, dan video.
Terapkan batching sisi klien untuk beban kerja bervolume tinggi dan manfaatkan penskalaan otomatis CometAPI untuk menangani lonjakan lalu lintas tanpa intervensi manual.
Strategi efisiensi biaya
- Kumpulkan tugas-tugas dengan kompleksitas rendah pada Flash-Lite sambil menyisakan Flash Pro atau standar untuk pekerjaan berat.
- Gunakan batasan tarif dan peringatan anggaran di dasbor CometAPI untuk mencegah pengeluaran yang tak terkendali.
- Pantau penggunaan berdasarkan ID model untuk membandingkan biaya per permintaan dan sesuaikan logika perutean Anda.
Apa praktik terbaik dan langkah selanjutnya setelah integrasi awal?
Pemantauan, pencatatan, dan keamanan
- Logging: Menangkap metadata permintaan/respons (cap waktu, latensi, penggunaan token) untuk audit kinerja.
- Alerts: Siapkan pemberitahuan ambang batas untuk tingkat kesalahan atau kelebihan biaya di CometAPI.
- Security: Putar kunci API secara berkala dan simpan dalam brankas aman atau variabel lingkungan.
Pola penggunaan umum
- Chatbots: Gunakan Flash-Lite untuk pertanyaan pengguna yang cepat dan kembali ke Pro untuk tindak lanjut yang rumit.
- Pemrosesan dokumen: Analisis PDF atau gambar batch dalam waktu semalam dengan anggaran yang lebih rendah.
- Analisis waktu nyata: Alirkan data keuangan atau operasional untuk wawasan instan melalui API streaming.
Menjelajah lebih jauh
- Bereksperimen dengan perintah hibrida: gabungkan masukan teks dan gambar untuk konteks yang lebih kaya.
- Prototipe RAG (Retrieval-Augmented Generation) dengan mengintegrasikan alat pencarian vektor dengan Gemini 2.5 Flash-Lite.
- Melakukan tolok ukur terhadap penawaran pesaing (misalnya, GPT-4.1, Claude Sonnet 4) untuk memvalidasi pertimbangan biaya dan kinerja.
Skala dalam produksi
- Memanfaatkan tingkatan perusahaan CometAPI untuk kumpulan kuota khusus dan jaminan SLA.
- Terapkan strategi penerapan biru-hijau untuk menguji perintah atau anggaran baru tanpa mengganggu pengguna langsung.
- Tinjau metrik penggunaan model secara berkala untuk mengidentifikasi peluang penghematan biaya lebih lanjut atau peningkatan kualitas.
Mulai
CometAPI menyediakan antarmuka REST terpadu yang menggabungkan ratusan model AI—di bawah titik akhir yang konsisten, dengan manajemen kunci API bawaan, kuota penggunaan, dan dasbor penagihan. Daripada harus mengelola beberapa URL dan kredensial vendor.
Pengembang dapat mengakses Gemini 2.5 Flash-Lite (pratinjau) API(Model: gemini-2.5-flash-lite-preview-06-17) Melalui API Komet, model terbaru yang tercantum adalah pada tanggal publikasi artikel. Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda berintegrasi.
Hanya dalam beberapa langkah, Anda dapat mengintegrasikan Gemini 2.5 Flash-Lite melalui CometAPI ke dalam aplikasi Anda, membuka kombinasi hebat antara kecepatan, keterjangkauan, dan kecerdasan multimoda. Dengan mengikuti panduan di atas—yang mencakup penyiapan, permintaan dasar, fitur lanjutan, dan pengoptimalan—Anda akan berada dalam posisi yang tepat untuk menghadirkan pengalaman AI generasi berikutnya kepada pengguna Anda. Masa depan AI yang hemat biaya dan berthroughput tinggi telah hadir: mulailah dengan Gemini 2.5 Flash-Lite hari ini.