

Pada tanggal 17 Juni, unicorn AI Shanghai MiniMax secara resmi membuka sumbernya MiniMax‑M1, model inferensi perhatian hibrida skala besar berbobot terbuka pertama di dunia. Dengan menggabungkan arsitektur Mixture‑of‑Experts (MoE) dengan mekanisme Lightning Attention yang baru, MiniMax‑M1 memberikan peningkatan besar dalam kecepatan inferensi, penanganan konteks yang sangat panjang, dan kinerja tugas yang kompleks.
Latar Belakang dan Evolusi
Membangun di atas fondasi MiniMax-Teks-01, yang memperkenalkan perhatian kilat pada kerangka Mixture-of-Experts (MoE) untuk mencapai konteks 1 juta token selama pelatihan dan hingga 4 juta token pada inferensi, MiniMax-M1 mewakili generasi berikutnya dari seri MiniMax-01. Model pendahulunya, MiniMax-Text-01, berisi 456 miliar parameter total dengan 45.9 miliar diaktifkan per token, menunjukkan kinerja yang setara dengan LLM tingkat atas sambil memperluas kemampuan konteks secara signifikan.
Fitur Utama MiniMax‑M1
- MoE Hibrida + Perhatian Petir: MiniMax‑M1 memadukan desain Mixture‑of‑Experts yang jarang—total 456 miliar parameter, tetapi hanya 45.9 miliar yang diaktifkan per token—dengan Lightning Attention, perhatian kompleksitas linier yang dioptimalkan untuk rangkaian yang sangat panjang.
- Konteks Ultra-Panjang: Mendukung hingga 1 juta token input—sekitar delapan kali batas 128 K dari DeepSeek‑R1—memungkinkan pemahaman mendalam terhadap dokumen besar.
- Efisiensi Unggul: Saat menghasilkan 100 K token, Lightning Attention MiniMax‑M1 hanya memerlukan ~25–30% dari komputasi yang digunakan oleh DeepSeek‑R1.
Varian Model
- MiniMax‑M1‑40K: 1 konteks token M, anggaran inferensi token 40 K
- MiniMax‑M1‑80K: 1 konteks token M, anggaran inferensi token 80 K
Dalam skenario penggunaan alat bangku TAU, varian 40K mengungguli semua model bobot terbuka—termasuk Gemini 2.5 Pro—yang menunjukkan kemampuan agennya.
Biaya Pelatihan & Pengaturan
MiniMax-M1 dilatih secara menyeluruh menggunakan pembelajaran penguatan (RL) skala besar di berbagai tugas—mulai dari penalaran matematika tingkat lanjut hingga lingkungan rekayasa perangkat lunak berbasis sandbox. Algoritme baru, Bahasa Inggris CISPO (Clipped Importance Sampling for Policy Optimization), lebih meningkatkan efisiensi pelatihan dengan memotong bobot pengambilan sampel penting alih-alih pembaruan tingkat token. Pendekatan ini, dikombinasikan dengan perhatian kilat model, memungkinkan pelatihan RL penuh pada 512 GPU H800 selesai hanya dalam tiga minggu dengan total biaya sewa sebesar $534,700.
Ketersediaan dan Harga
MiniMax-M1 dirilis di bawah Apache 2.0 lisensi sumber terbuka dan dapat langsung diakses melalui:
- Repositori GitHub, termasuk bobot model, skrip pelatihan, dan tolok ukur evaluasi.
- Awan Silikon hosting, menawarkan dua varian—40 K‑token (“M1‑40K”) dan 80 K‑token (“M1‑80K”)—dengan rencana untuk mengaktifkan saluran penuh 1 M token.
- Harga saat ini ditetapkan pada ¥4 per juta token untuk input dan ¥16 per juta token untuk output, dengan diskon volume tersedia untuk pelanggan perusahaan.
Pengembang dan organisasi dapat mengintegrasikan MiniMax-M1 melalui API standar, menyempurnakan data spesifik domain, atau menerapkannya di lokasi untuk beban kerja yang sensitif.
Kinerja Tingkat Tugas
| Kategori Tugas | Menyoroti | Kinerja Relatif |
|---|---|---|
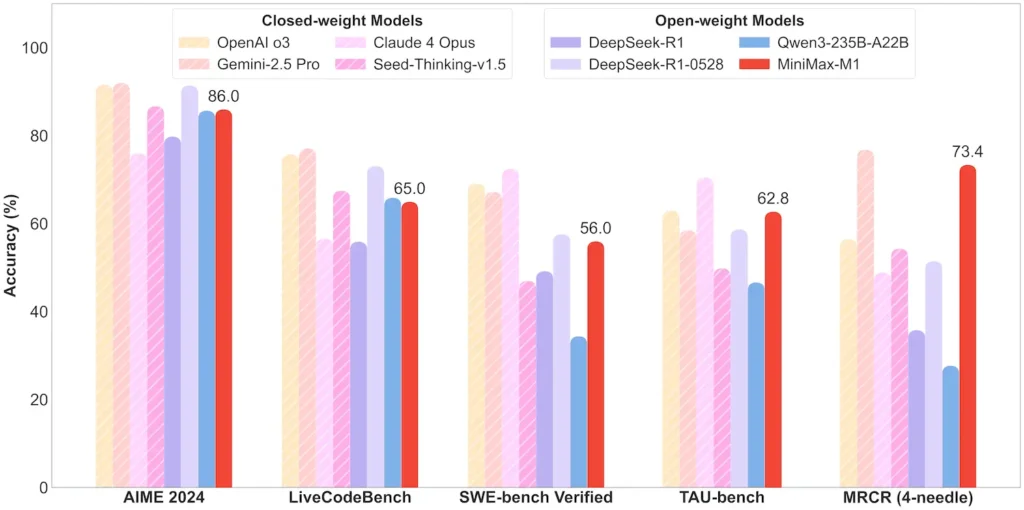
| Matematika dan Logika | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; sumber tertutup dekat |
| Pemahaman Konteks Panjang | Penguasa (4 token K–1 M): Tingkat atas yang stabil | Mengungguli GPT‑4 di atas panjang token 128 K |
| Rekayasa Perangkat Lunak | SWE‑bench (bug GitHub asli): 56% | Terbaik di antara model terbuka; ke-2 setelah model tertutup terkemuka |
| Penggunaan Agen & Alat | TAU‑bench (simulasi API) | 62–63.5% vs. Gemini 2.5, Claude 4 |
| Dialog & Asisten | Tantangan Ganda: 44.7% | Cocok dengan Claude 4, DeepSeek‑R1 |
| Tanya Jawab Fakta | QA Sederhana: 18.5% | Area untuk perbaikan di masa depan |
Catatan: persentase dan tolok ukur dari pengungkapan resmi MiniMax dan laporan berita independen
Inovasi Teknis
- Tumpukan Perhatian Hibrida: Perhatian Petir lapisan (biaya linier) disisipkan dengan Softmax Attention periodik (kuadratik tetapi lebih ekspresif) untuk menyeimbangkan efisiensi dan daya pemodelan.
- Pengalihan MoE Jarang: 32 modul ahli; setiap token hanya mengaktifkan ~10% dari total parameter, mengurangi biaya inferensi sambil mempertahankan kapasitas.
- Pembelajaran Penguatan CISPO: Algoritma “Clipped IS‑weight Policy Optimization” baru yang mempertahankan token langka namun penting dalam sinyal pembelajaran, mempercepat stabilitas dan kecepatan RL.
Rilisan bobot terbuka MiniMax‑M1 membuka inferensi konteks ultra panjang dan efisiensi tinggi untuk semua orang—menjembatani kesenjangan antara penelitian dan AI skala besar yang dapat diterapkan.
Mulai
CometAPI menyediakan antarmuka REST terpadu yang menggabungkan ratusan model AI—termasuk keluarga ChatGPT—di bawah titik akhir yang konsisten, dengan manajemen kunci API bawaan, kuota penggunaan, dan dasbor penagihan. Daripada harus mengelola beberapa URL dan kredensial vendor.
Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API.
API MiniMax‑M1 integrasi terbaru akan segera muncul di CometAPI, jadi nantikan! Sementara kami menyelesaikan unggahan Model MiniMax‑M1, jelajahi model kami yang lain di Halaman model atau mencobanya di Taman Bermain AIModel terbaru MiniMax di CometAPI adalah Minimax ABAB7-Pratinjau API dan API MiniMax Video-01 ,lihat:
