Detail Teknis
- Penalaran Adaptif:
Gemini 2.5 Flash-Litemendukung pemikiran sesuai kebutuhan, memungkinkan pengembang mengalokasikan sumber daya komputasi hanya saat penalaran yang lebih mendalam diperlukan. - Integrasi Alat: Kompatibel penuh dengan alat native Gemini 2.5, termasuk Grounding with Google Search, Code Execution, URL Context, dan Function Calling untuk alur kerja multimodal yang mulus.
- Model Context Protocol (MCP): Memanfaatkan MCP milik Google untuk mengambil data web waktu nyata, memastikan respons terbaru dan relevan secara kontekstual.
- Opsi Penyebaran: Tersedia melalui CometAPI, Gemini API, Vertex AI, dan Google AI Studio, dengan jalur pratinjau bagi para pengadopsi awal untuk bereksperimen dan memberikan masukan .
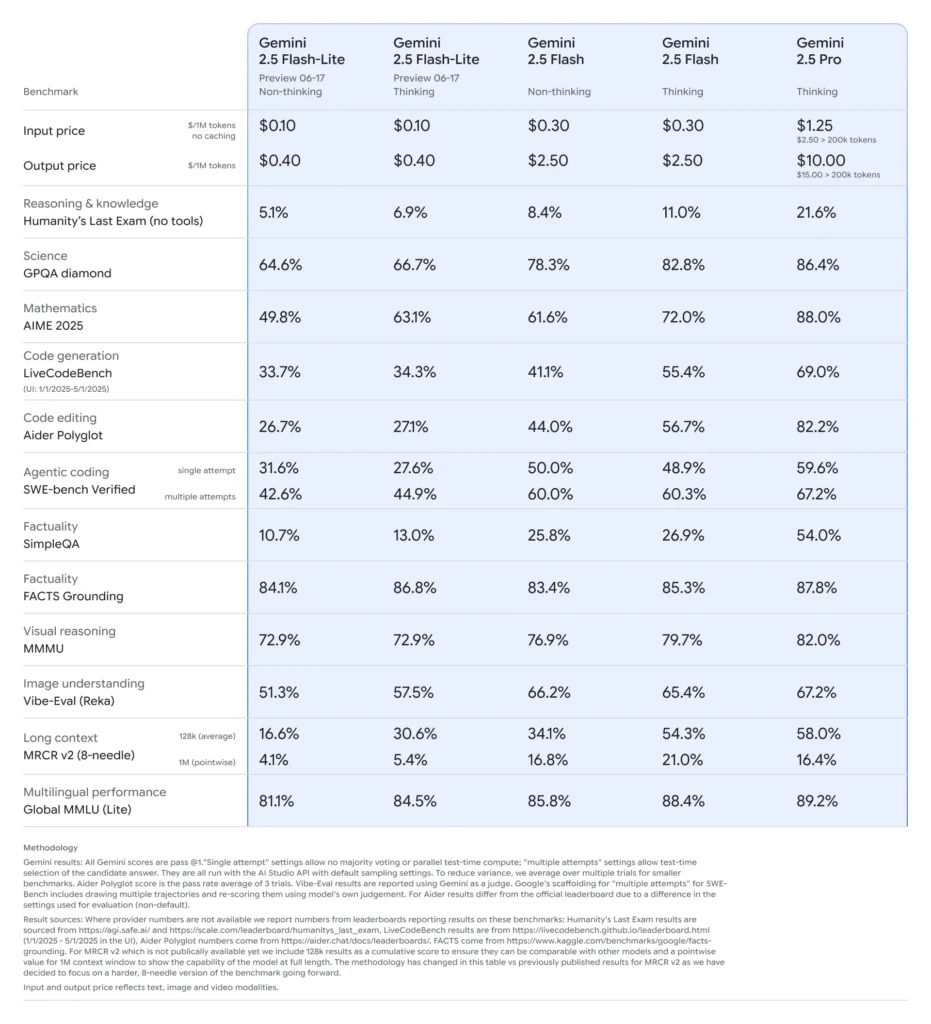
Performa Benchmark dari Gemini 2.5 Flash-Lite
- Latensi: Mencapai waktu respons median hingga 50% lebih rendah dibandingkan Gemini 2.5 Flash, dengan latensi khas di bawah 100 ms pada tolok ukur klasifikasi dan peringkasan standar.
- Throughput: Dioptimalkan untuk beban kerja bervolume tinggi, mempertahankan puluhan ribu permintaan per menit tanpa degradasi kinerja.
- Performa Biaya: Menunjukkan pengurangan 25% pada biaya per 1.000 token dibandingkan versi Flash-nya, menjadikannya pilihan Pareto-optimal untuk penerapan yang sensitif terhadap biaya.
- Adopsi Industri: Pengguna awal melaporkan integrasi yang mulus ke pipeline produksi, dengan metrik kinerja yang selaras dengan atau melampaui proyeksi awal .
Kasus Penggunaan Ideal
- Tugas Frekuensi Tinggi, Kompleksitas Rendah: Pelabelan otomatis, analisis sentimen, dan terjemahan massal
- Pipeline Sensitif Biaya: Ekstraksi data dari korpus dokumen besar, peringkasan batch berkala
- Skenario Edge dan Mobile: Saat latensi krusial tetapi anggaran sumber daya terbatas
Keterbatasan Gemini 2.5 Flash-Lite
- Status Pratinjau: Dapat mengalami perubahan API sebelum GA; integrasi harus mengantisipasi kemungkinan kenaikan versi.
- Tanpa Fine-Tuning On-the-Fly: Tidak dapat mengunggah bobot kustom; andalkan rekayasa prompt dan pesan sistem.
- Kreativitas Berkurang: Disetel untuk tugas deterministik ber-throughput tinggi; kurang cocok untuk generasi terbuka atau penulisan “kreatif”.
- Batas Sumber Daya: Menskalakan secara linear hanya hingga ~16 vCPU; di atas ini, peningkatan throughput berkurang.
- Keterbatasan Multimodal: Mendukung masukan gambar/audio tetapi dengan fidelitas terbatas; tidak ideal untuk tugas visi berat atau transkripsi audio.
- Trade-off Jendela Konteks : Meskipun menerima hingga 1 M token, inferensi praktis pada skala tersebut mungkin mengalami penurunan throughput.