

Dalam lanskap kecerdasan buatan yang berkembang pesat, tahun 2025 telah menyaksikan kemajuan signifikan dalam model bahasa besar (LLM). Di antara yang terdepan adalah Qwen2.5 milik Alibaba, model V3 dan R1 milik DeepSeek, dan ChatGPT milik OpenAI. Masing-masing model ini menghadirkan kemampuan dan inovasi yang unik. Artikel ini membahas perkembangan terbaru seputar Qwen2.5, membandingkan fitur dan kinerjanya dengan DeepSeek dan ChatGPT untuk menentukan model mana yang saat ini memimpin persaingan AI.
Apa itu Qwen2.5?
Ringkasan
Qwen 2.5 adalah model bahasa besar terbaru dari Alibaba Cloud yang padat dan hanya untuk dekoder, tersedia dalam berbagai ukuran mulai dari 0.5B hingga 72B parameter. Model ini dioptimalkan untuk mengikuti instruksi, keluaran terstruktur (misalnya, JSON, tabel), pengodean, dan pemecahan masalah matematika. Dengan dukungan lebih dari 29 bahasa dan panjang konteks hingga 128K token, Qwen2.5 dirancang untuk aplikasi multibahasa dan khusus domain.
Fitur utama
- Dukungan multibahasa: Mendukung lebih dari 29 bahasa, melayani basis pengguna global.
- Panjang Konteks yang Diperluas: Menangani hingga 128K token, memungkinkan pemrosesan dokumen dan percakapan yang panjang.
- Varian Khusus: Termasuk model seperti Qwen2.5-Coder untuk tugas pemrograman dan Qwen2.5-Math untuk pemecahan masalah matematika.
- Aksesibilitas :Tersedia melalui platform seperti Hugging Face, GitHub, dan antarmuka web yang baru diluncurkan di obrolan.qwenlm.ai.
Bagaimana cara menggunakan Qwen 2.5 secara lokal?
Berikut adalah panduan langkah demi langkah untuk 7 B Obrolan titik pemeriksaan; ukuran yang lebih besar hanya berbeda dalam persyaratan GPU.
1. Prasyarat perangkat keras
| Pilih Model | vRAM untuk 8‑bit | vRAM untuk 4-bit (QLoRA) | Ukuran disk |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Satu RTX 4090 (24 GB) mencukupi untuk inferensi 7 B pada presisi 16‑bit penuh; dua kartu tersebut atau CPU off‑load plus kuantisasi dapat menangani 14 B.
2. Instalasi
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Skrip inferensi cepat
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
The trust_remote_code=True bendera diperlukan karena Qwen mengirimkan yang khusus Penanaman Posisi Putar pembungkus.
4. Penyetelan halus dengan LoRA
Berkat adaptor LoRA yang hemat parameter, Anda dapat melatih Qwen secara khusus pada ~50 K pasangan domain (misalnya, medis) dalam waktu kurang dari empat jam pada satu GPU 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
File adaptor yang dihasilkan (~120 MB) dapat digabungkan kembali atau dimuat sesuai permintaan.
Opsional: Jalankan Qwen 2.5 sebagai API
CometAPI bertindak sebagai hub terpusat untuk API beberapa model AI terkemuka, menghilangkan kebutuhan untuk bekerja sama dengan beberapa penyedia API secara terpisah. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda mengintegrasikan Qwen API, dan Anda akan mendapatkan $1 di akun Anda setelah mendaftar dan masuk! Selamat datang untuk mendaftar dan mencoba CometAPI. Bagi pengembang yang ingin menggabungkan Qwen 2.5 ke dalam aplikasi:
Langkah 1: Instal pustaka yang diperlukan:
bash
pip install requests
Langkah 2: dapatkan Kunci API
- Navigasi ke API Komet.
- Masuk dengan akun CometAPI Anda.
- Pilih Menu Utama.
- Klik “Dapatkan Kunci API” dan ikuti petunjuk untuk membuat kunci Anda.
Langkah 3: Menerapkan Panggilan API
Gunakan kredensial API untuk membuat permintaan ke Qwen 2.5.Ganti dengan kunci CometAPI Anda yang sebenarnya dari akun Anda.
Misalnya, dalam Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Integrasi ini memungkinkan penggabungan kemampuan Qwen 2.5 yang mulus ke dalam berbagai aplikasi, meningkatkan fungsionalitas dan pengalaman pengguna.Pilih “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” titik akhir untuk mengirim permintaan API dan mengatur isi permintaan. Metode permintaan dan isi permintaan diperoleh dari dokumen API situs web kami. Situs web kami juga menyediakan pengujian Apifox demi kenyamanan Anda.
Silakan lihat API Qwen 2.5 Max untuk detail integrasi.CometAPI telah memperbarui yang terbaru API QwQ-32BUntuk informasi Model lebih lanjut di Comet API silakan lihat Dokumen API.
Praktik dan tip terbaik
| Contoh | Rekomendasi |
|---|---|
| Tanya Jawab dokumen panjang | Bagi bagian-bagian menjadi ≤16 K token dan gunakan perintah yang ditambah dengan pengambilan alih-alih konteks 100 K yang naif untuk mengurangi latensi. |
| Keluaran terstruktur | Awali pesan sistem dengan: You are an AI that strictly outputs JSON. Pelatihan penyelarasan Qwen 2.5 unggul pada pembangkitan terbatas. |
| Pelengkapan kode | set temperature=0.0 dan top_p=1.0 untuk memaksimalkan determinisme, maka ambil sampel beberapa balok (num_return_sequences=4) untuk pemeringkatan. |
| Penyaringan keamanan | Gunakan bundel regex “Qwen‑Guardrails” sumber terbuka milik Alibaba atau text‑moderation‑004 milik OpenAI sebagai langkah awal. |
Keterbatasan yang diketahui dari Qwen 2.5
- Kerentanan injeksi cepat. Audit eksternal menunjukkan tingkat keberhasilan jailbreak sebesar 18% pada Qwen 2.5‑VL—sebuah pengingat bahwa ukuran model yang besar tidak menghindarkan kita dari instruksi yang merugikan.
- Kebisingan OCR non‑Latin. Saat disetel dengan baik untuk tugas-tugas bahasa penglihatan, jalur ujung-ke-ujung model terkadang membingungkan glif bahasa Mandarin tradisional vs. yang disederhanakan, sehingga memerlukan lapisan koreksi khusus domain.
- Tebing memori GPU pada 128 K. FlashAttention‑2 mengimbangi RAM, tetapi penerusan padat 72 B melintasi 128 K token masih menuntut >120 GB vRAM; praktisi harus melakukan window‑attend atau KV‑cache.
Peta jalan & ekosistem komunitas
Tim Qwen telah mengisyaratkan Qwen 3.0, yang menargetkan tulang punggung perutean hibrida (Dense + MoE) dan prapelatihan ucapan‑penglihatan‑teks terpadu. Sementara itu, ekosistem tersebut telah menjadi tuan rumah:
- Agen Q – agen rantai pemikiran gaya ReAct yang menggunakan Qwen 2.5‑14B sebagai kebijakan.
- Alpaka Keuangan Cina – LoRA pada Qwen2.5‑7B dilatih dengan 1 juta pengajuan regulasi.
- Buka plug-in Interpreter – menukar GPT‑4 dengan pos pemeriksaan Qwen lokal di VS Code.
Kunjungi halaman “Koleksi Qwen2.5” Hugging Face untuk mendapatkan daftar titik pemeriksaan, adaptor, dan harness evaluasi yang terus diperbarui.
Analisis Perbandingan: Qwen2.5 vs. DeepSeek dan ChatGPT
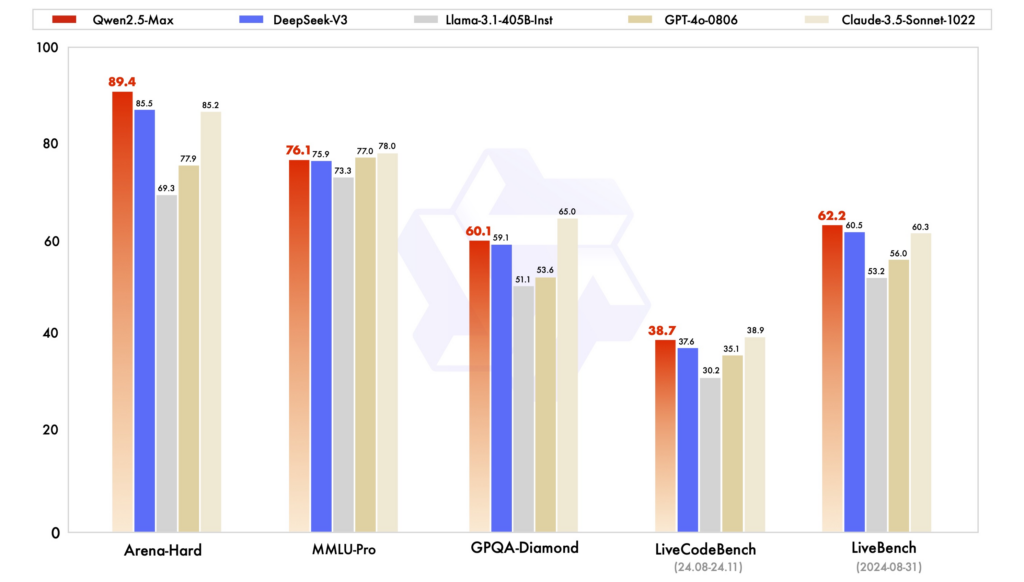
Tolok Ukur Kinerja: Dalam berbagai evaluasi, Qwen2.5 telah menunjukkan kinerja yang kuat dalam tugas-tugas yang memerlukan penalaran, pengodean, dan pemahaman multibahasa. DeepSeek-V3, dengan arsitektur MoE-nya, unggul dalam efisiensi dan skalabilitas, memberikan kinerja tinggi dengan sumber daya komputasi yang berkurang. ChatGPT tetap menjadi model yang tangguh, khususnya dalam tugas-tugas bahasa tujuan umum.
Efisiensi dan Biaya: Model DeepSeek terkenal karena pelatihan dan inferensi yang hemat biaya, memanfaatkan arsitektur MoE untuk mengaktifkan hanya parameter yang diperlukan per token. Qwen2.5, meskipun padat, menawarkan varian khusus untuk mengoptimalkan kinerja untuk tugas tertentu. Pelatihan ChatGPT melibatkan sumber daya komputasi yang substansial, yang tercermin dalam biaya operasionalnya.
Aksesibilitas dan Ketersediaan Open-Source: Qwen2.5 dan DeepSeek telah mengadopsi prinsip-prinsip open-source dalam berbagai tingkatan, dengan model-model yang tersedia pada platform-platform seperti GitHub dan Hugging Face. Peluncuran antarmuka web terbaru Qwen2.5 meningkatkan aksesibilitasnya. ChatGPT, meskipun bukan open-source, dapat diakses secara luas melalui platform dan integrasi OpenAI.
Kesimpulan
Qwen 2.5 berada di titik manis antara layanan premium dengan bobot tertutup dan model hobi yang sepenuhnya terbukaPerpaduan antara lisensi permisif, kekuatan multibahasa, kompetensi konteks panjang, dan skala parameter yang luas menjadikannya landasan yang kuat bagi penelitian dan produksi.
Seiring dengan pesatnya perkembangan lanskap LLM sumber terbuka, proyek Qwen menunjukkan bahwa transparansi dan kinerja dapat hidup berdampinganBagi para pengembang, ilmuwan data, dan pembuat kebijakan, menguasai Qwen 2.5 saat ini merupakan investasi untuk masa depan AI yang lebih pluralistik dan ramah inovasi.