

Kemajuan terbaru Alibaba dalam kecerdasan buatan, Qwen3-Pembuat Kode, menandai tonggak penting dalam lanskap pengembangan perangkat lunak berbasis AI yang berkembang pesat. Diluncurkan pada 23 Juli 2025, Qwen3-Coder adalah model pengodean agen sumber terbuka yang dirancang untuk menangani tugas-tugas pemrograman kompleks secara mandiri, mulai dari pembuatan kode standar hingga debugging di seluruh basis kode. Dibangun di atas arsitektur campuran pakar (MoE) mutakhir dan memiliki 480 miliar parameter dengan 35 miliar diaktifkan per token, model ini mencapai keseimbangan optimal antara kinerja dan efisiensi komputasi. Dalam artikel ini, kami mengeksplorasi apa yang membedakan Qwen3-Coder, memeriksa kinerja benchmark-nya, menguraikan inovasi teknisnya, memandu pengembang melalui penggunaan yang optimal, dan mempertimbangkan penerimaan dan prospek masa depan model tersebut.
Apa itu Qwen3‑Coder?
Qwen3‑Coder adalah model pengkodean agen terbaru dari keluarga Qwen, yang resmi diumumkan pada 22 Juli 2025. Dirancang sebagai "model kode paling agen hingga saat ini", varian unggulannya, Qwen3‑Coder‑480B‑A35B‑Instruct, memiliki total 480 miliar parameter dengan desain Campuran Pakar (MoE) yang mengaktifkan 35 miliar parameter per token. Model ini secara native mendukung jendela konteks hingga 256 ribu token dan dapat diskalakan hingga satu juta token melalui teknik ekstrapolasi, memenuhi kebutuhan pemahaman dan pembuatan kode berskala repositori.
Sumber terbuka di bawah Apache 2.0
Sejalan dengan komitmen Alibaba terhadap pengembangan berbasis komunitas, Qwen3-Coder dirilis di bawah lisensi Apache 2.0. Ketersediaan sumber terbuka ini memastikan transparansi, mendorong kontribusi pihak ketiga, dan mempercepat adopsi di dunia akademis maupun industri. Para peneliti dan insinyur dapat mengakses bobot yang telah dilatih sebelumnya dan menyempurnakan model untuk domain khusus, mulai dari teknologi finansial hingga komputasi ilmiah.
Evolusi dari Qwen2.5
Berdasarkan kesuksesan Qwen2.5‑Coder, yang menawarkan model dengan parameter mulai dari 0.5 miliar hingga 32 miliar dan mencapai hasil SOTA di seluruh tolok ukur pembangkitan kode, Qwen3‑Coder memperluas kapabilitas pendahulunya melalui skala yang lebih besar, alur data yang disempurnakan, dan metode pelatihan yang baru. Qwen2.5‑Coder dilatih menggunakan lebih dari 5.5 triliun token dengan pembersihan data yang cermat dan pembangkitan data sintetis; Qwen3‑Coder mengembangkannya dengan menyerap 7.5 triliun token dengan rasio kode 70%, memanfaatkan model sebelumnya untuk menyaring dan menulis ulang input yang kurang akurat demi kualitas data yang superior.
Apa inovasi utama yang membedakan Qwen3-Coder?
Beberapa inovasi utama yang membedakan Qwen3-Coder:
- Orkestrasi Tugas Agen:Daripada sekadar menghasilkan cuplikan, Qwen3-Coder dapat secara mandiri menyatukan beberapa operasi—membaca dokumentasi, memanggil utilitas, dan memvalidasi keluaran—tanpa campur tangan manusia.
- Anggaran Pemikiran yang Ditingkatkan: Pengembang dapat mengonfigurasi berapa banyak komputasi yang dikhususkan untuk setiap langkah penalaran, yang memungkinkan keseimbangan yang dapat disesuaikan antara kecepatan dan ketelitian, yang sangat penting untuk sintesis kode berskala besar.
- Integrasi Alat yang Mulus:Antarmuka baris perintah Qwen3-Coder, “Qwen Code,” mengadaptasi protokol pemanggilan fungsi dan perintah yang disesuaikan untuk diintegrasikan dengan berbagai alat pengembang populer, sehingga memudahkan untuk disematkan dalam alur kerja CI/CD dan IDE yang sudah ada.
Bagaimana kinerja Qwen3‑Coder dibandingkan dengan pesaingnya?
Pertarungan patokan
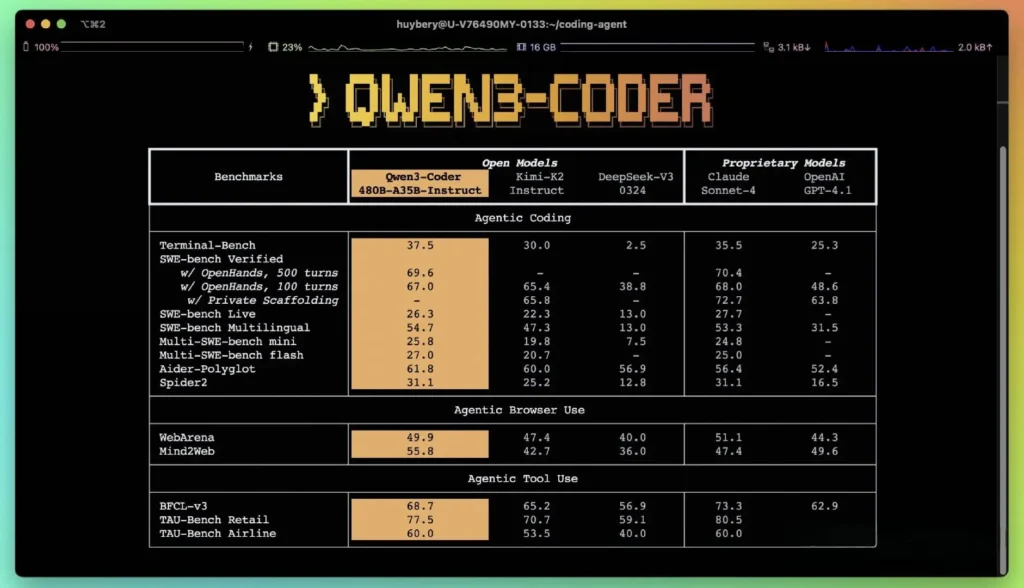
Menurut metrik kinerja yang dipublikasikan Alibaba, Qwen3-Coder mengungguli alternatif domestik terkemuka—seperti model bergaya kodeks DeepSeek dan K2 Moonshot AI—dan menyamai atau melampaui kemampuan pengkodean penawaran-penawaran terbaik AS di beberapa tolok ukur. Dalam evaluasi pihak ketiga:
- Aider Poliglot:Qwen3-Coder-480B mencapai skor 61.8%, yang menggambarkan pembuatan kode dan penalaran multibahasa yang kuat.
- MBPP dan HumanEval: Pengujian independen melaporkan bahwa Qwen3-Coder-480B-A35B mengungguli GPT-4.1 pada kebenaran fungsional dan penanganan perintah kompleks, khususnya dalam tantangan pengodean multi-langkah.
- Varian parameter 480B mencapai lebih dari 85% keberhasilan eksekusi pada SWE‑Bangku Rangkaian terverifikasi—melampaui model teratas DeepSeek (78%) dan K2 Moonshot (82%), serta menyamai Claude Sonnet 4 pada 86%.
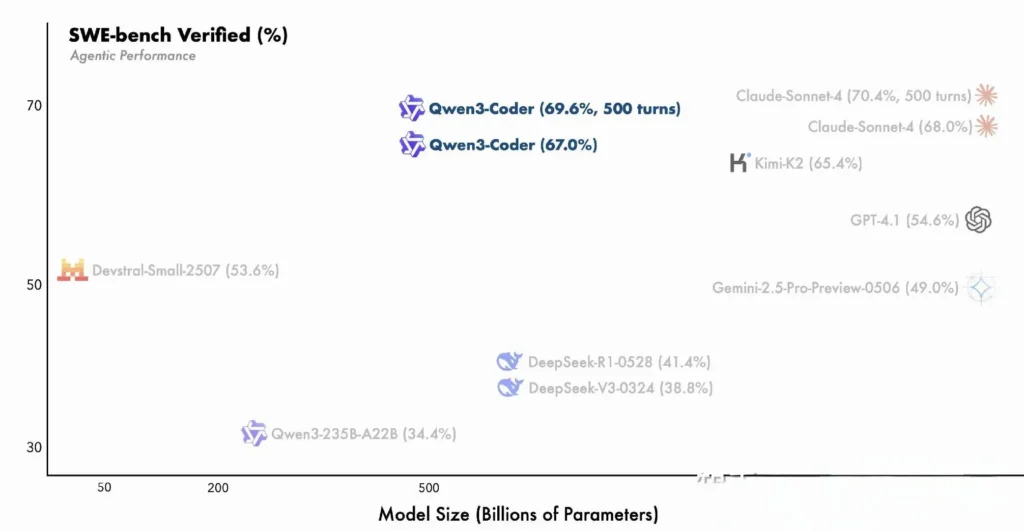
Perbandingan dengan Model Proprietary
Alibaba mengklaim bahwa kapabilitas agen Qwen3‑Coder selaras dengan Claude dari Anthropic dan GPT‑4 dari OpenAI dalam alur kerja pengkodean menyeluruh, sebuah prestasi luar biasa untuk model sumber terbuka. Para penguji awal melaporkan bahwa perencanaan multi-turn, pemanggilan alat dinamis, dan koreksi kesalahan otomatisnya dapat menangani tugas-tugas kompleks—seperti membangun aplikasi web tumpukan penuh atau mengintegrasikan alur kerja CI/CD—dengan perintah manusia yang minimal. Kapabilitas ini didukung oleh kapasitas model untuk melakukan validasi mandiri melalui eksekusi kode, sebuah fitur yang kurang menonjol dalam LLM generatif murni.
Apa inovasi teknis di balik Qwen3‑Coder?
Arsitektur Campuran Pakar (MoE)
Inti dari Qwen3‑Coder adalah desain MoE yang canggih. Tidak seperti model padat yang mengaktifkan semua parameter untuk setiap token, arsitektur MoE secara selektif melibatkan sub-jaringan khusus (pakar) yang dirancang khusus untuk jenis token atau tugas tertentu. Dalam Qwen3‑Coder, total 480 miliar parameter didistribusikan ke beberapa pakar, dengan hanya 35 miliar parameter aktif per token. Pendekatan ini memangkas biaya inferensi lebih dari 60% dibandingkan dengan model padat yang setara, sekaligus mempertahankan fidelitas tinggi dalam sintesis dan debugging kode.
Mode berpikir dan mode non-berpikir
Meminjam inovasi dari keluarga Qwen3 yang lebih luas, Qwen3‑Coder mengintegrasikan inferensi mode ganda kerangka:
- Mode Berpikir mengalokasikan “anggaran pemikiran” yang lebih besar untuk tugas-tugas penalaran yang kompleks dan bertahap seperti desain algoritma atau pemfaktoran ulang lintas-file.
- Mode Non-Berpikir menyediakan respons cepat berdasarkan konteks yang cocok untuk pelengkapan kode sederhana dan cuplikan penggunaan API.
Pengalihan mode terpadu ini menghilangkan kebutuhan untuk mengelola model terpisah untuk tugas yang dioptimalkan untuk obrolan versus tugas yang dioptimalkan untuk penalaran, sehingga menyederhanakan alur kerja pengembang.
Pembelajaran Penguatan dengan Sintesis Kasus Uji Otomatis
Inovasi yang menonjol adalah jendela konteks token 3K bawaan Qwen256-Coder—dua kali lipat kapasitas rata-rata model terbuka terkemuka—dan dukungan hingga satu juta token melalui metode ekstrapolasi (misalnya, YaRN). Hal ini memungkinkan model untuk memproses seluruh repositori, set dokumentasi, atau proyek multi-file dalam satu lintasan, mempertahankan dependensi lintas-file dan mengurangi permintaan berulang. Uji empiris menunjukkan bahwa perluasan jendela konteks menghasilkan peningkatan yang semakin berkurang tetapi tetap signifikan dalam kinerja tugas jangka panjang, terutama dalam skenario pembelajaran penguatan berbasis lingkungan.
Bagaimana pengembang dapat mengakses dan menggunakan Qwen3‑Coder?
Strategi rilis untuk Qwen3-Coder menekankan keterbukaan dan kemudahan adopsi:
- Bobot Model Sumber Terbuka: Semua titik pemeriksaan model tersedia di GitHub di bawah Apache 2.0, memungkinkan transparansi penuh dan peningkatan yang digerakkan oleh komunitas.
- Antarmuka Baris Perintah (Kode Qwen):Diambil dari Google Gemini Code, CLI mendukung perintah yang disesuaikan, pemanggilan fungsi, dan arsitektur plugin untuk terintegrasi secara mulus dengan sistem pembangunan dan IDE yang ada.
- Penerapan Cloud dan Lokal:Gambar Docker yang telah dikonfigurasikan sebelumnya dan bagan Kubernetes Helm memfasilitasi penerapan yang dapat diskalakan di lingkungan cloud, sementara resep kuantisasi lokal (kuantisasi dinamis 2–8 bit) memungkinkan inferensi lokal yang efisien, bahkan pada GPU komoditas.
- Akses API melalui CometAPI:Pengembang juga dapat berinteraksi dengan Qwen3-Coder melalui titik akhir yang dihosting di platform seperti API Komet, yang menawarkan Open source(
qwen3-coder-480b-a35b-instruct) dan versi komersial(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)dengan harga yang sama. Versi komersial panjangnya 1M. - Wajah Memeluk:Alibaba telah membuat bobot Qwen3‑Coder dan pustaka pendampingnya tersedia secara gratis di Hugging Face dan GitHub, dikemas di bawah lisensi Apache 2.0 yang mengizinkan penggunaan akademis dan komersial tanpa royalti.
Integrasi API dan SDK melalui CometAPI
CometAPI adalah platform API terpadu yang menggabungkan lebih dari 500 model AI dari penyedia terkemuka—seperti seri GPT OpenAI, Gemini Google, Claude Anthropic, Midjourney, Suno, dan lainnya—menjadi satu antarmuka yang ramah bagi pengembang. Dengan menawarkan autentikasi yang konsisten, pemformatan permintaan, dan penanganan respons, CometAPI secara drastis menyederhanakan integrasi kapabilitas AI ke dalam aplikasi Anda. Baik Anda sedang membangun chatbot, generator gambar, komposer musik, atau alur kerja analitik berbasis data, CometAPI memungkinkan Anda melakukan iterasi lebih cepat, mengendalikan biaya, dan tetap tidak bergantung pada vendor—semuanya sambil memanfaatkan terobosan terbaru di seluruh ekosistem AI.
Pengembang dapat berinteraksi dengan Qwen3-Pembuat Kode melalui API bergaya OpenAI yang kompatibel, tersedia melalui CometAPI. API Komet, yang menawarkan Open source(qwen3-coder-480b-a35b-instruct) dan versi komersial(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)dengan harga yang sama. Versi komersial panjangnya 1 juta. Contoh kode untuk Python (menggunakan klien yang kompatibel dengan OpenAI) dengan praktik terbaik yang merekomendasikan pengaturan pengambilan sampel suhu = 0.7, top_p = 0.8, top_k = 20, dan penalti_pengulangan = 1.05. Panjang keluaran dapat mencapai 65,536 token, sehingga cocok untuk tugas pembuatan kode berskala besar.
Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API.
Panduan Singkat tentang Hugging Face dan Alibaba Cloud
Pengembang yang ingin bereksperimen dengan Qwen3‑Coder dapat menemukan modelnya di Hugging Face di bawah repositori Qwen/Qwen3‑Coder‑480B‑A35B‑InstructIntegrasi disederhanakan melalui transformers perpustakaan (versi ≥ 4.51.0 untuk menghindari KeyError: 'qwen3_moe') dan klien Python yang kompatibel dengan OpenAI. Contoh minimal:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
Menentukan alat khusus dan alur kerja agen
Salah satu fitur unggulan Qwen3‑Coder adalah pemanggilan alat dinamisPengembang dapat mendaftarkan utilitas eksternal—linter, formatter, test runner—dan mengizinkan model untuk memanggilnya secara otomatis selama sesi pengkodean. Kemampuan ini mengubah Qwen3‑Coder dari asisten kode pasif menjadi agen pengkodean aktif, yang mampu menjalankan pengujian, menyesuaikan gaya kode, dan bahkan menerapkan layanan mikro berdasarkan maksud percakapan.
Aplikasi potensial dan arah masa depan apa yang dimungkinkan oleh Qwen3‑Coder?
Dengan menggabungkan kebebasan sumber terbuka dengan performa sekelas perusahaan, Qwen3-Coder membuka jalan bagi generasi baru alat pengembangan berbasis AI. Mulai dari audit kode otomatis dan pemeriksaan kepatuhan keamanan hingga layanan refactoring berkelanjutan dan asisten dev-ops bertenaga AI, fleksibilitas model ini telah menginspirasi perusahaan rintisan maupun tim inovasi internal.
Alur Kerja Pengembangan Perangkat Lunak
Pengguna awal melaporkan pengurangan waktu sebesar 30–50 persen untuk pengkodean standar, manajemen dependensi, dan perancah awal, yang memungkinkan para insinyur untuk berfokus pada tugas-tugas desain dan arsitektur bernilai tinggi. Rangkaian integrasi berkelanjutan dapat memanfaatkan Qwen3-Coder untuk menghasilkan pengujian secara otomatis, mendeteksi regresi, dan bahkan menyarankan pengoptimalan kinerja berdasarkan analisis kode waktu nyata.
Perusahaan Bermain
Seiring perusahaan di bidang keuangan, layanan kesehatan, dan e-commerce mengintegrasikan Qwen3-Coder ke dalam sistem penting, umpan balik antara tim pengguna dan tim R&D Alibaba akan mempercepat penyempurnaan—seperti penyetelan khusus domain, protokol keamanan yang ditingkatkan, dan plugin IDE yang lebih ketat. Lebih lanjut, strategi sumber terbuka Alibaba mendorong kontribusi dari komunitas global, yang mendorong ekosistem ekstensi, tolok ukur, dan pustaka praktik terbaik yang dinamis.
Kesimpulan
Singkatnya, Qwen3-Coder merupakan tonggak penting dalam AI sumber terbuka untuk rekayasa perangkat lunak: sebuah model agensi yang tangguh yang tidak hanya menulis kode, tetapi juga mengorkestrasi seluruh alur pengembangan dengan pengawasan manusia yang minimal. Dengan menyediakan teknologi ini secara gratis dan mudah diintegrasikan, Alibaba mendemokratisasi akses ke perkakas AI canggih dan menyiapkan panggung bagi era di mana kreasi perangkat lunak menjadi semakin kolaboratif, efisien, dan cerdas.
Pertanyaan Umum (FAQ)
Apa yang membuat Qwen3‑Coder “agentik”?
AI Agentik mengacu pada model yang dapat merencanakan dan menjalankan tugas multi-langkah secara mandiri. Kemampuan Qwen3-Coder untuk memanggil alat eksternal, menjalankan pengujian, dan mengelola basis kode tanpa campur tangan manusia merupakan contoh paradigma ini.
Apakah Qwen3‑Coder cocok untuk penggunaan produksi?
Sementara Qwen3‑Coder menunjukkan kinerja yang kuat pada tolok ukur dan pengujian dunia nyata, perusahaan harus melakukan evaluasi khusus domain dan menerapkan pembatas (misalnya, jalur verifikasi keluaran) sebelum mengintegrasikannya ke dalam alur kerja produksi yang penting.
Bagaimana arsitektur Mixture‑of‑Experts memberi manfaat bagi pengembang?
MoE mengurangi biaya inferensi dengan hanya mengaktifkan sub-jaringan yang relevan per token, memungkinkan pembangkitan yang lebih cepat dan biaya komputasi yang lebih rendah. Efisiensi ini krusial untuk penskalaan asisten pengkodean AI di lingkungan cloud.