

Apa itu Llama 4?
meta Platforms telah meluncurkan rangkaian model bahasa besar (LLM) terbarunya di bawah seri Llama 4, yang menandai kemajuan signifikan dalam teknologi kecerdasan buatan. Koleksi Llama 4 memperkenalkan dua model utama pada bulan April 2025: Llama 4 Scout dan Llama 4 Maverick. Model-model ini dirancang untuk memproses dan menerjemahkan berbagai format data, termasuk teks, video, gambar, dan audio, yang memamerkan kemampuan multimodanya. Selain itu, Meta telah mempratinjau Llama 4 Behemoth, model mendatang yang disebut-sebut sebagai salah satu LLM terkuat hingga saat ini, yang dimaksudkan untuk membantu dalam pelatihan model masa depan.

Apa yang Membedakan Llama 4 dari Model Sebelumnya?
Peningkatan Kemampuan Multimoda
Tidak seperti pendahulunya, Llama 4 dirancang untuk menangani berbagai modalitas data dengan lancar. Ini berarti ia dapat menganalisis dan menghasilkan respons berdasarkan teks, gambar, video, dan masukan audio, sehingga sangat mudah beradaptasi untuk berbagai aplikasi.
Pengenalan Model Khusus
Meta telah memperkenalkan dua versi khusus dalam seri Llama 4:
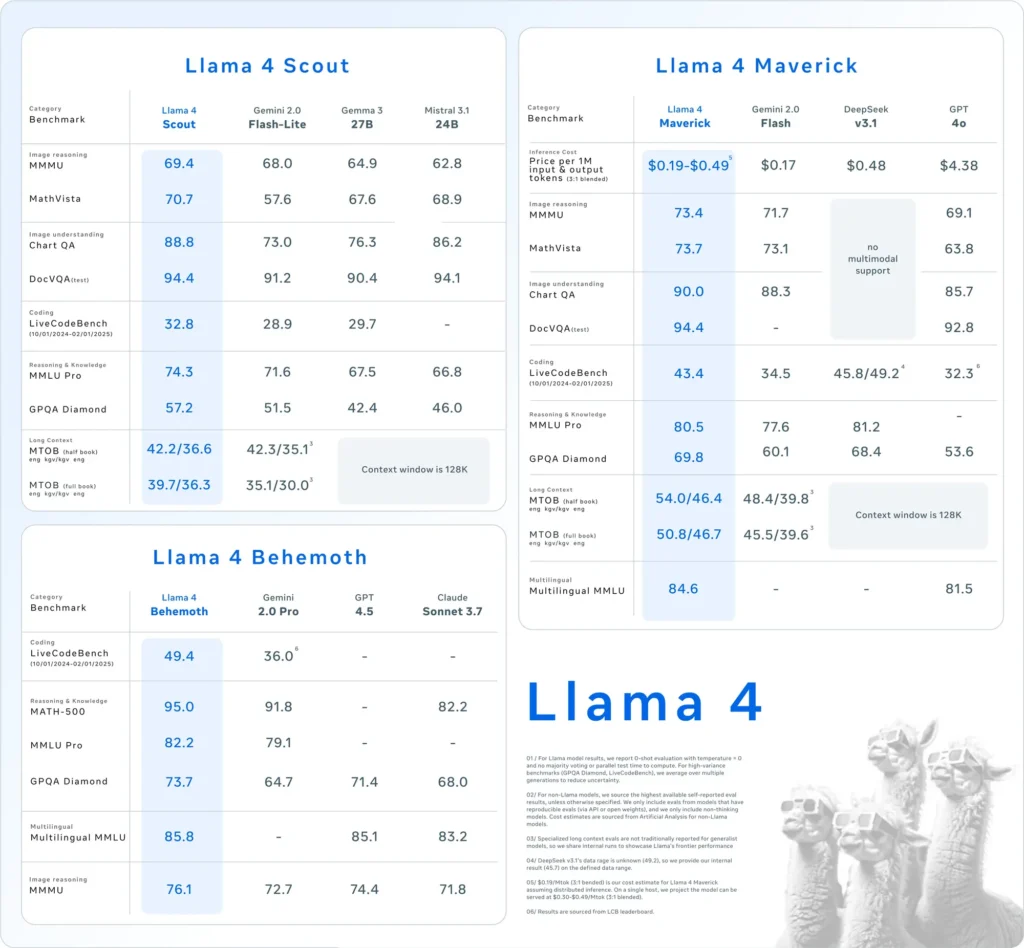
- Llama 4 Pramuka: Model ringkas yang dioptimalkan untuk berjalan secara efisien pada satu GPU Nvidia H100. Model ini memiliki jendela konteks 10 juta token dan telah menunjukkan kinerja yang unggul dibandingkan pesaing seperti Gemma 3 dan Mistral 3.1 dari Google dalam berbagai tolok ukur.
- Llama untuk Maverick: Model yang lebih besar yang kinerjanya sebanding dengan GPT-4o OpenAI dan DeepSeek-V3, khususnya unggul dalam tugas pengkodean dan penalaran sambil memanfaatkan lebih sedikit parameter aktif.
Selain itu, Meta sedang mengembangkan Llama 4 Behemoth, model dengan 288 miliar parameter aktif dan total 2 triliun, yang bertujuan melampaui model seperti GPT-4.5 dan Claude Sonnet 3.7 pada tolok ukur STEM.
Penerapan Arsitektur Campuran Para Ahli (MoE)
Llama 4 menggunakan arsitektur "campuran pakar" (MoE), yang membagi model menjadi unit-unit khusus untuk mengoptimalkan pemanfaatan sumber daya dan meningkatkan kinerja. Pendekatan ini memungkinkan pemrosesan yang lebih efisien dengan hanya mengaktifkan subset model yang relevan untuk tugas-tugas tertentu.
Bagaimana Llama 4 Dibandingkan dengan Model AI Lainnya?
Llama 4 memposisikan dirinya secara kompetitif di antara model AI terkemuka:
- Tolok Ukur Kinerja: Performa Llama 4 Maverick setara dengan GPT-4o dan DeepSeek-V3 milik OpenAI dalam tugas pengkodean dan penalaran, sementara Llama 4 Scout mengungguli model seperti Gemma 3 milik Google dan Mistral 3.1 dalam berbagai tolok ukur.
- Pendekatan Sumber Terbuka: Meta terus menawarkan model Llama sebagai sumber terbuka, yang mendukung kolaborasi dan integrasi yang lebih luas di berbagai platform. Namun, lisensi Llama 4 memberlakukan pembatasan pada entitas komersial dengan lebih dari 700 juta pengguna, yang mendorong diskusi tentang keterbukaan model yang sebenarnya.
| Kategori | patokan | Llama untuk Maverick | GPT-4o | Gemini 2.0 Kilat | Pencarian Mendalam v3.1 |
|---|---|---|---|---|---|
| Penalaran Gambar | MMMU | 73.4 | 69.1 | 71.7 | Tidak ada dukungan multimoda |
| MatematikaVista | 73.7 | 63.8 | 73.1 | Tidak ada dukungan multimoda | |
| Pemahaman Gambar | BaganQA | 90.0 | 85.7 | 88.3 | Tidak ada dukungan multimoda |
| DocVQA (uji coba) | 94.4 | 92.8 | - | Tidak ada dukungan multimoda | |
| Pengkodean | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| Penalaran & Pengetahuan | MMLU Profesional | 80.5 | - | 77.6 | 81.2 |
| Berlian GPQA | 69.8 | 53.6 | 60.1 | 68.4 | |
| Multilingual | MMLU multibahasa | 84.6 | 81.5 | - | - |
| Konteks Panjang | MTOB (setengah buku) eng→kgv/kgv→eng | 54.0/46.4 | Konteks terbatas pada 128K | 48.4/39.8 | Konteks terbatas pada 128K |
| MTOB (buku lengkap) eng→kgv/kgv→eng | 50.8/46.7 | Konteks terbatas pada 128K | 45.5/39.6 | Konteks terbatas pada 128K |
Bagaimana Performa Llama 4 dalam Uji Benchmark?
Evaluasi tolok ukur memberikan wawasan tentang kinerja model Llama 4:
- Llama 4 Pramuka: Model ini mengungguli beberapa pesaing, termasuk Gemma 3 dan Mistral 3.1 dari Google, dalam berbagai tolok ukur. Kemampuannya untuk beroperasi dengan jendela konteks 10 juta token pada satu GPU menonjolkan efisiensi dan efektivitasnya dalam menangani tugas-tugas kompleks.
- Llama untuk Maverick: Performanya sebanding dengan GPT-4o dan DeepSeek-V3 milik OpenAI, Llama 4 Maverick unggul dalam tugas pengkodean dan penalaran sambil menggunakan lebih sedikit parameter aktif. Efisiensi ini tidak mengorbankan kapabilitas, sehingga menjadikannya pesaing kuat dalam lanskap LLM.
- Llama 4 Behemoth: Dengan 288 miliar parameter aktif dan total 2 triliun, Llama 4 Behemoth melampaui model seperti GPT-4.5 dan Claude Sonnet 3.7 pada tolok ukur STEM. Jumlah parameter dan kinerjanya yang luas menunjukkan potensinya sebagai model dasar untuk pengembangan AI di masa mendatang.
Hasil benchmark ini menggarisbawahi dedikasi Meta untuk memajukan kemampuan AI dan memposisikan seri Llama 4 sebagai pemain tangguh di bidangnya.
Bagaimana Pengguna Dapat Mengakses Llama 4?
Meta telah mengintegrasikan model Llama 4 ke dalam asisten AI-nya, sehingga dapat diakses di berbagai platform seperti WhatsApp, Messenger, Instagram, dan web. Integrasi ini memungkinkan pengguna untuk merasakan kemampuan Llama 4 yang ditingkatkan dalam aplikasi yang sudah dikenal.
Bagi pengembang dan peneliti yang tertarik memanfaatkan Llama 4 untuk aplikasi khusus, Meta menyediakan akses ke bobot model melalui platform seperti Hugging Face dan saluran distribusinya sendiri. Pendekatan sumber terbuka ini memungkinkan komunitas AI untuk berinovasi dan mengembangkan kemampuan Llama 4.
Penting untuk dicatat bahwa meskipun Llama 4 dipasarkan sebagai sumber terbuka, lisensi tersebut memberlakukan pembatasan pada entitas komersial dengan lebih dari 700 juta pengguna. Organisasi harus meninjau ketentuan lisensi untuk memastikan kepatuhan terhadap pedoman Meta.
Bangun Cepat dengan Llama 4 di CometAPI
CometAPI menyediakan akses ke lebih dari 500 model AI, termasuk model multimoda sumber terbuka dan khusus untuk obrolan, gambar, kode, dan banyak lagi. Kekuatan utamanya terletak pada penyederhanaan proses integrasi AI yang secara tradisional rumit. Dengan memusatkan agregasi API dalam satu platform, aplikasi ini menghemat waktu dan sumber daya berharga bagi pengguna yang seharusnya digunakan untuk mengelola platform dan penyedia yang terpisah. Dengan aplikasi ini, akses ke berbagai alat AI terkemuka seperti Claude, OpenAI, Deepseek, dan Gemini tersedia melalui satu langganan terpadu. Anda dapat menggunakan API di CometAPI untuk membuat musik dan karya seni, membuat video, dan membangun alur kerja Anda sendiri.
API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda mengintegrasikan API Llama 4, dan Anda akan mendapatkan $1 di akun Anda setelah mendaftar dan masuk! Selamat datang untuk mendaftar dan mencoba CometAPI.CometAPI membayar sesuai pemakaian,API Llama 4 Harga di CometAPI disusun sebagai berikut:
| Kategori | llama-4-maverick | llama-4-pramuka |
| Harga API | Token Masukan: $0.48 / M token | Token Masukan: $0.216 / M token |
| Token Keluaran: $1.44/M token | Token Keluaran: $1.152/M token |
- Silakan lihat API Llama 4 untuk rincian integrasi.
- Untuk informasi Model yang diluncurkan di Comet API silakan lihat https://api.cometapi.com/new-model.
- Untuk informasi Harga Model di Comet API silakan lihat https://api.cometapi.com/pricing
Mulai membangun CometAPI hari ini – daftar di sini untuk akses gratis atau skala tanpa batas kecepatan dengan meningkatkan ke Paket berbayar CometAPI.

Apa Implikasi dari Perilisan Llama 4?
Integrasi Lintas Platform Meta
Llama 4 diintegrasikan ke dalam asisten AI Meta di seluruh platform seperti WhatsApp, Messenger, Instagram, dan web, meningkatkan pengalaman pengguna dengan kemampuan AI yang canggih.
Dampak pada Industri AI
Peluncuran Llama 4 menggarisbawahi dorongan agresif Meta ke dalam AI, dengan rencana untuk berinvestasi hingga $65 miliar dalam memperluas infrastruktur AI-nya. Langkah ini mencerminkan meningkatnya persaingan di antara para raksasa teknologi untuk memimpin dalam inovasi AI.
Pertimbangan Konsumsi Energi
Sumber daya komputasi yang besar yang dibutuhkan untuk Llama 4 menimbulkan kekhawatiran tentang konsumsi energi dan keberlanjutan. Mengoperasikan kluster yang terdiri dari lebih dari 100,000 GPU membutuhkan energi yang signifikan, yang mendorong diskusi tentang dampak lingkungan dari model AI skala besar.
Apa Masa Depan Llama 4?
Meta berencana untuk membahas lebih lanjut perkembangan dan aplikasi Llama 4 di konferensi LlamaCon mendatang pada tanggal 29 April 2025. Komunitas AI menantikan wawasan mengenai strategi Meta untuk mengatasi tantangan saat ini dan memanfaatkan kemampuan Llama 4 di berbagai sektor.
Singkatnya, Llama 4 merupakan kemajuan signifikan dalam model bahasa AI, yang menawarkan kemampuan multimoda yang ditingkatkan dan arsitektur khusus. Meskipun menghadapi tantangan pengembangan, investasi besar dan inisiatif strategis Meta memposisikan Llama 4 sebagai pesaing tangguh dalam lanskap AI yang terus berkembang.