

Pada tanggal 17 Juni 2025, pemimpin AI yang berbasis di Shanghai, MiniMax (juga dikenal sebagai Xiyu Technology) secara resmi merilis MiniMax-M1 (selanjutnya disebut “M1”)—model penalaran hybrid-attention skala besar dan berbobot terbuka pertama di dunia. Dengan menggabungkan arsitektur Mixture-of-Experts (MoE) dengan mekanisme Lightning Attention yang inovatif, M1 mencapai kinerja terdepan di industri dalam tugas-tugas yang berorientasi pada produktivitas, menyaingi sistem sumber tertutup teratas sambil mempertahankan efektivitas biaya yang tak tertandingi. Dalam artikel mendalam ini, kami membahas apa itu M1, cara kerjanya, fitur-fitur yang menentukannya, dan panduan praktis tentang cara mengakses dan menggunakan model tersebut.
Apa itu MiniMax-M1?
MiniMax-M1 merupakan puncak penelitian MiniMaxAI tentang mekanisme perhatian yang efisien dan terukur. Berdasarkan fondasi MiniMax-Text-01, iterasi M1 mengintegrasikan perhatian kilat dengan kerangka kerja MoE untuk mencapai efisiensi yang belum pernah terjadi sebelumnya selama pelatihan dan inferensi. Kombinasi ini memungkinkan model untuk mempertahankan kinerja tinggi bahkan saat memproses urutan yang sangat panjang — persyaratan utama untuk tugas yang melibatkan basis kode yang luas, dokumen hukum, atau literatur ilmiah.
Arsitektur inti dan parameterisasi
Pada intinya, MiniMax-M1 memanfaatkan sistem MoE hibrid yang secara dinamis merutekan token melalui subset subjaringan ahli. Sementara model tersebut terdiri dari total 456 miliar parameter, hanya 45.9 miliar yang diaktifkan untuk setiap token, sehingga mengoptimalkan penggunaan sumber daya. Desain ini terinspirasi dari implementasi MoE sebelumnya tetapi menyempurnakan logika perutean untuk meminimalkan overhead komunikasi antara GPU selama inferensi terdistribusi.
Perhatian kilat dan dukungan konteks panjang
Fitur penentu MiniMax-M1 adalah mekanisme perhatian kilatnya, yang secara drastis mengurangi beban komputasi perhatian diri untuk urutan yang panjang. Dengan memperkirakan matriks perhatian melalui kombinasi kernel lokal dan global, model tersebut memangkas FLOP hingga 75% dibandingkan dengan transformer tradisional saat memproses urutan token 100K. Efisiensi ini tidak hanya mempercepat inferensi tetapi juga membuka pintu untuk menangani jendela konteks hingga satu juta token tanpa persyaratan perangkat keras yang mahal.
Bagaimana MiniMax-M1 mencapai efisiensi komputasi?
Peningkatan efisiensi MiniMax-M1 berasal dari dua inovasi utama: arsitektur Mixture-of-Experts hibrid dan algoritma pembelajaran penguatan CISPO baru yang digunakan selama pelatihan. Bersama-sama, elemen-elemen ini mengurangi waktu pelatihan dan biaya inferensi, sehingga memungkinkan eksperimen dan penerapan yang cepat.
Rute Campuran Ahli Hibrida
Komponen MoE menggunakan 32 subjaringan pakar, yang masing-masing mengkhususkan diri dalam berbagai aspek penalaran atau tugas khusus domain. Selama inferensi, mekanisme gating yang dipelajari secara dinamis memilih pakar yang paling relevan untuk setiap token, mengaktifkan hanya subjaringan yang diperlukan untuk memproses input. Aktivasi selektif ini memangkas komputasi yang berlebihan dan mengurangi permintaan bandwidth memori, sehingga MiniMax-M1 memiliki keunggulan substansial dalam efisiensi biaya dibandingkan model transformator monolitik.
CISPO: Algoritma pembelajaran penguatan baru
Untuk lebih meningkatkan efisiensi pelatihan, MiniMaxAI mengembangkan CISPO (Clipped Importance Sampling with Partial Overrides), sebuah algoritma RL yang menggantikan pembaruan bobot tingkat token dengan pemotongan berbasis pengambilan sampel penting. CISPO mengurangi masalah ledakan bobot yang umum terjadi dalam pengaturan RL skala besar, mempercepat konvergensi, dan memastikan peningkatan kebijakan yang stabil di berbagai tolok ukur. Hasilnya, pelatihan RL penuh MiniMax-M1 pada 512 GPU H800 selesai hanya dalam tiga minggu, dengan biaya sekitar $534,700 — sebagian kecil dari biaya yang dilaporkan untuk pelatihan GPT-4 yang sebanding.
Apa saja tolok ukur kinerja MiniMax-M1?
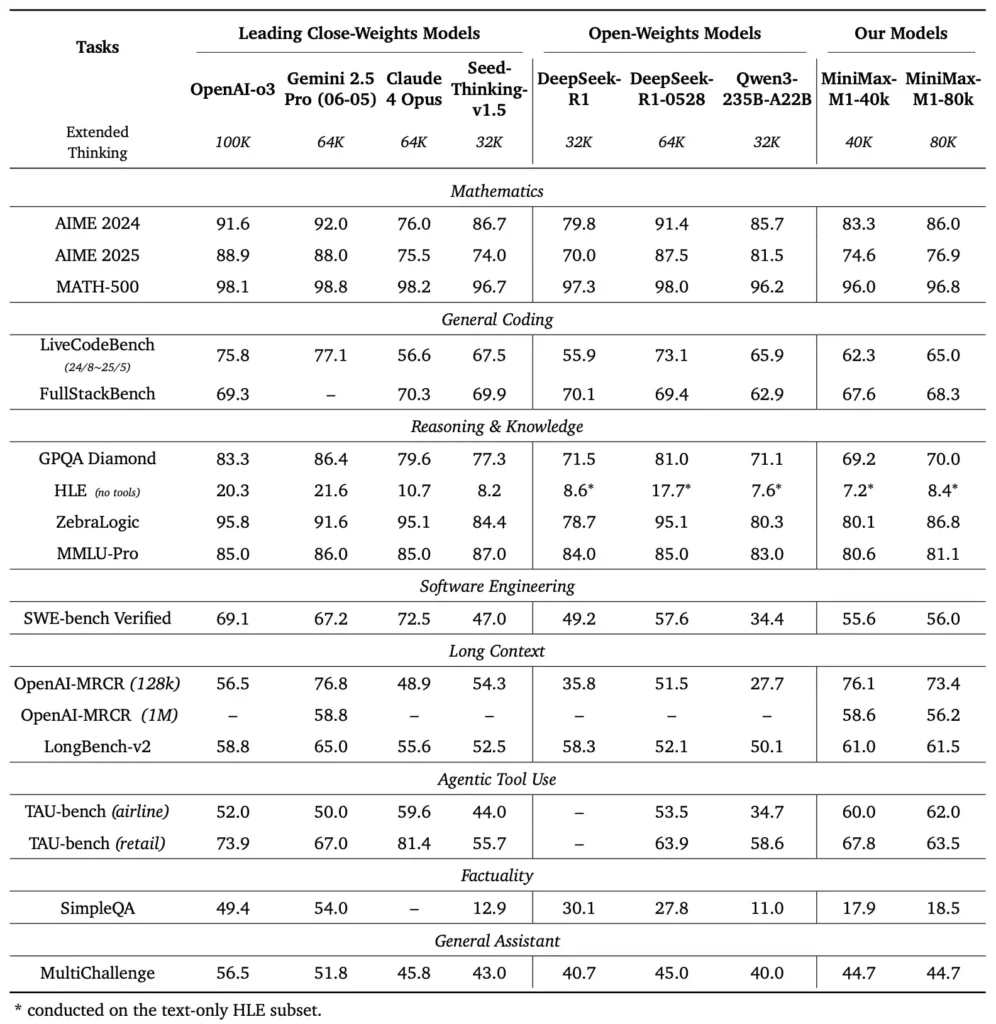
MiniMax-M1 unggul dalam berbagai tolok ukur standar dan khusus domain, menunjukkan kehebatannya dalam menangani penalaran konteks panjang, pemecahan masalah matematika, dan pembuatan kode.
Tugas penalaran konteks panjang
Dalam pengujian pemahaman dokumen yang ekstensif, MiniMax-M1 memproses jendela konteks hingga 1,000,000 token, mengungguli DeepSeek-R1 dengan faktor delapan dalam panjang konteks maksimum dan mengurangi separuh persyaratan komputasi untuk rangkaian 100K token. Pada tolok ukur seperti evaluasi konteks lanjutan NarrativeQA, model tersebut mencapai skor pemahaman mutakhir, yang dikaitkan dengan kemampuan perhatian kilatnya untuk menangkap dependensi lokal dan global secara efisien.
Rekayasa perangkat lunak dan pemanfaatan alat
MiniMax-M1 secara khusus dilatih pada lingkungan rekayasa perangkat lunak sandboxed menggunakan RL skala besar, yang memungkinkannya untuk menghasilkan dan men-debug kode dengan akurasi yang luar biasa. Dalam benchmark pengkodean seperti HumanEval dan MBPP, model tersebut mencapai tingkat kelulusan yang sebanding dengan atau melebihi Qwen3-235B dan DeepSeek-R1, khususnya dalam basis kode multi-file dan tugas yang memerlukan referensi silang segmen kode yang panjang. Lebih jauh, demonstrasi awal MiniMaxAI menunjukkan kemampuan model untuk terintegrasi dengan alat pengembang, mulai dari menghasilkan jalur CI/CD hingga alur kerja dokumentasi otomatis.
Bagaimana pengembang dapat mengakses MiniMax-M1?
Untuk mendorong adopsi yang meluas, MiniMaxAI telah menyediakan MiniMax-M1 secara gratis sebagai model dengan bobot terbuka. Pengembang dapat mengakses titik pemeriksaan yang telah dilatih sebelumnya, bobot model, dan kode inferensi melalui repositori GitHub resmi.
Rilis versi open-weight di GitHub
MiniMaxAI menerbitkan berkas model MiniMax-M1 dan skrip yang menyertainya di bawah lisensi sumber terbuka yang permisif di GitHub. Pengguna yang tertarik dapat mengkloning repositori di https://github.com/MiniMax-AI/MiniMax-M1, yang menjadi tempat checkpoint untuk varian anggaran token 40K dan 80K, serta contoh integrasi untuk kerangka kerja ML umum seperti PyTorch dan TensorFlow.
Titik akhir API dan integrasi cloud
Selain penerapan lokal, MiniMaxAI telah bermitra dengan penyedia cloud utama untuk menawarkan layanan API terkelola. Melalui kemitraan ini, pengembang dapat memanggil MiniMax-M1 melalui titik akhir RESTful, dengan SDK yang tersedia untuk Python, JavaScript, dan Java. API tersebut mencakup parameter yang dapat dikonfigurasi untuk panjang konteks, ambang batas perutean ahli, dan anggaran token, yang memungkinkan pengguna untuk menyesuaikan kinerja dengan kasus penggunaan mereka sambil memantau konsumsi komputasi secara real time.
Bagaimana cara mengintegrasikan dan menggunakan MiniMax-M1 dalam aplikasi nyata?
Memanfaatkan kemampuan MiniMax-M1 memerlukan pemahaman pola API, praktik terbaik untuk perintah konteks panjang, dan strategi untuk orkestrasi alat.
Contoh penggunaan API dasar
Panggilan API yang umum melibatkan pengiriman muatan JSON yang berisi teks masukan dan penggantian konfigurasi opsional. Misalnya:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Respons mengembalikan JSON terstruktur dengan teks yang dihasilkan, statistik penggunaan token, dan log perutean, yang memungkinkan pemantauan aktivasi ahli secara mendetail.
Penggunaan alat dan Agen MiniMax
Bersamaan dengan model inti, MiniMaxAI telah memperkenalkan MiniMax Agent, kerangka kerja agen beta yang dapat memanggil alat eksternal—mulai dari lingkungan eksekusi kode hingga web scraper—di balik layar. Pengembang dapat membuat contoh sesi agen yang merangkai penalaran model dengan pemanggilan alat, misalnya, untuk mengambil data waktu nyata, melakukan perhitungan, atau memperbarui basis data. Paradigma agen ini menyederhanakan pengembangan aplikasi menyeluruh, yang memungkinkan MiniMax-M1 berfungsi sebagai orkestrasi dalam alur kerja yang kompleks.
Praktik terbaik dan jebakan
- Rekayasa cepat untuk konteks yang panjang: Membagi masukan ke dalam segmen-segmen yang koheren, menanamkan ringkasan pada interval yang logis, dan memanfaatkan strategi “meringkas lalu memberi alasan” untuk mempertahankan fokus model.
- Komputasi vs. pertukaran kinerja: Bereksperimenlah dengan ambang batas keahlian yang lebih rendah atau anggaran pemikiran yang dikurangi (misalnya, varian 40K) untuk aplikasi yang sensitif terhadap latensi.
- Pemantauan dan tata kelola: Gunakan log perutean dan statistik token untuk mengaudit pemanfaatan ahli dan memastikan kepatuhan terhadap anggaran biaya, terutama di lingkungan produksi.
Dengan mengikuti pedoman ini, pengembang dapat memanfaatkan kekuatan MiniMax-M1—penanganan konteks yang luas dan penalaran yang efisien—sambil mengurangi risiko yang terkait dengan penerapan model berskala besar.
Bagaimana Anda menggunakan MiniMax-M1?
Setelah terinstal, M1 dapat dipanggil melalui skrip Python sederhana atau buku catatan interaktif.
Seperti Apa Skrip Inferensi Dasar?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Contoh ini menggunakan varian anggaran 40k; menukar ke "MiniMax-AI/MiniMax-M1-80k" membuka anggaran penalaran 80 k penuh ().
Bagaimana Anda Menangani Konteks yang Sangat Panjang?
Untuk input yang melebihi ukuran buffer biasa, M1 mendukung tokenisasi streaming. Gunakan stream=True bendera dalam tokenizer untuk memasukkan token dalam potongan, dan memanfaatkan inferensi restart titik pemeriksaan untuk mempertahankan kinerja pada rangkaian jutaan token.
Bagaimana Anda Dapat Menyempurnakan atau Mengadaptasi M1?
Meskipun titik pemeriksaan dasar sudah cukup untuk sebagian besar tugas, peneliti dapat menerapkan penyempurnaan RL menggunakan kode CISPO yang disertakan dalam repositori. Dengan menyediakan fungsi penghargaan khusus—mulai dari ketepatan kode hingga ketepatan semantik—praktisi dapat mengadaptasi M1 ke alur kerja khusus domain.
Kesimpulan
MiniMax-M1 menonjol sebagai model AI yang inovatif, yang mendorong batasan pemahaman dan penalaran bahasa konteks panjang. Dengan arsitektur MoE hibridnya, mekanisme perhatian kilat, dan program pelatihan yang didukung CISPO, model ini memberikan kinerja tinggi pada berbagai tugas mulai dari analisis hukum hingga rekayasa perangkat lunak, sekaligus mengurangi biaya komputasi secara drastis. Berkat rilis open-weight dan penawaran API berbasis cloud, MiniMax-M1 dapat diakses oleh berbagai pengembang dan organisasi yang ingin membangun aplikasi bertenaga AI generasi berikutnya. Seiring dengan terus dieksplorasinya potensi model konteks besar oleh komunitas AI, inovasi MiniMax-M1 siap memengaruhi penelitian dan pengembangan produk di masa mendatang di seluruh industri.
Mulai
CometAPI menyediakan antarmuka REST terpadu yang menggabungkan ratusan model AI—termasuk keluarga ChatGPT—di bawah titik akhir yang konsisten, dengan manajemen kunci API bawaan, kuota penggunaan, dan dasbor penagihan. Daripada harus mengelola beberapa URL dan kredensial vendor.
Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API.
API MiniMax‑M1 integrasi terbaru akan segera muncul di CometAPI, jadi nantikan! Sementara kami menyelesaikan unggahan Model MiniMax‑M1, jelajahi model kami yang lain di Halaman model atau mencobanya di Taman Bermain AIModel terbaru MiniMax di CometAPI adalah Minimax ABAB7-Pratinjau API dan API MiniMax Video-01 ,lihat:
