

Dalam lanskap yang didominasi oleh filosofi "scale-at-all-costs"—di mana model seperti Flux.2 dan Hunyuan-Image-3.0 mendorong jumlah parameter ke kisaran masif 30B hingga 80B—muncul penantang baru yang mengganggu status quo. Z-Image, dikembangkan oleh Tongyi Lab milik Alibaba, resmi diluncurkan, melampaui ekspektasi dengan arsitektur ramping 6 miliar parameter yang menandingi kualitas keluaran raksasa industri sembari berjalan di perangkat kelas konsumen.
Dirilis pada akhir 2025, Z-Image (dan varian super cepatnya Z-Image-Turbo) segera memikat komunitas AI, melampaui 500.000 unduhan dalam 24 jam sejak debutnya. Dengan menghasilkan gambar fotorealistik hanya dalam 8 langkah inferensi, Z-Image bukan sekadar model lain; ini adalah kekuatan yang mendemokratisasi AI generatif, memungkinkan kreasi fidelitas tinggi di laptop yang akan kewalahan oleh para pesaingnya.
Apa itu Z-Image?
Z-Image adalah model fondasi generasi gambar open-source baru yang dikembangkan oleh tim riset Tongyi-MAI / Alibaba Tongyi Lab. Ini adalah model generatif 6 miliar parameter yang dibangun di atas arsitektur baru Scalable Single-Stream Diffusion Transformer (S3-DiT) yang menggabungkan token teks, token semantik visual, dan token VAE ke dalam satu aliran pemrosesan. Tujuan desainnya jelas: menghadirkan fotorealisme kelas atas dan kepatuhan terhadap instruksi sambil secara drastis menurunkan biaya inferensi dan memungkinkan penggunaan praktis pada perangkat keras kelas konsumen. Proyek Z-Image mempublikasikan kode, bobot model, dan demo online di bawah lisensi Apache-2.0.
Z-Image hadir dalam beberapa varian. Rilis yang paling banyak dibahas adalah Z-Image-Turbo — versi terdistilasi dengan sedikit langkah yang dioptimalkan untuk deployment — serta Z-Image-Base yang tidak terdistilasi (checkpoint fondasi, lebih cocok untuk fine-tuning) dan Z-Image-Edit (di-tuning berdasarkan instruksi untuk pengeditan gambar).
Keunggulan "Turbo": Inferensi 8 Langkah
Varian flagship, Z-Image-Turbo, memanfaatkan teknik distilasi progresif yang dikenal sebagai Decoupled-DMD (Distribution Matching Distillation). Ini memungkinkan model mengompresi proses generasi dari standar 30–50 langkah menjadi hanya 8 langkah.
Hasil: Waktu generasi di bawah satu detik pada GPU enterprise (H800) dan performa nyaris real-time pada kartu konsumen (RTX 4090), tanpa tampilan "plastik" atau "pucat" yang khas pada model turbo/lightning lainnya.
4 Fitur Utama Z-Image
Z-Image sarat fitur yang melayani baik pengembang teknis maupun profesional kreatif.
1. Fotorealisme & Estetika Tak Tertandingi
Meski hanya memiliki 6 miliar parameter, Z-Image menghasilkan gambar dengan kejernihan yang mencengangkan. Model ini unggul dalam:
- Tekstur Kulit: Mereplikasi pori-pori, ketidaksempurnaan, dan pencahayaan alami pada subjek manusia.
- Fisika Material: Merender tekstur kaca, logam, dan kain secara akurat.
- Pencahayaan: Penanganan pencahayaan sinematik dan volumetrik yang superior dibandingkan SDXL.
2. Perenderan Teks Dwibahasa secara native
Salah satu titik nyeri paling signifikan dalam generasi gambar AI adalah perenderan teks. Z-Image mengatasinya dengan dukungan native untuk bahasa Inggris dan Tionghoa.
- Model ini dapat menghasilkan poster, logo, dan signage kompleks dengan ejaan dan kaligrafi yang benar dalam kedua bahasa—fitur yang sering absen pada model yang berpusat pada Barat.
3. Z-Image-Edit: Pengeditan Berbasis Instruksi
Bersamaan dengan model dasar, tim merilis Z-Image-Edit. Varian ini di-fine-tune untuk tugas image-to-image, memungkinkan pengguna memodifikasi gambar yang ada menggunakan instruksi bahasa alami (misal, "Buat orang tersebut tersenyum," "Ubah latar belakang menjadi pegunungan bersalju"). Varian ini menjaga konsistensi tinggi pada identitas dan pencahayaan selama transformasi.
4. Aksesibilitas Perangkat Keras Konsumen
- Efisiensi VRAM: Berjalan nyaman pada VRAM 6GB (dengan kuantisasi) hingga VRAM 16GB (presisi penuh).
- Eksekusi Lokal: Mendukung penuh deployment lokal melalui ComfyUI dan
diffusers, membebaskan pengguna dari ketergantungan cloud.
Bagaimana Z-Image Bekerja?
Transformer difusi aliran tunggal (S3-DiT)
Z-Image berbeda dari desain dual-stream klasik (encoder/aliran teks dan gambar terpisah) dan sebagai gantinya menggabungkan token teks, token VAE gambar, dan token semantik visual ke dalam satu masukan transformer. Pendekatan single-stream ini meningkatkan pemanfaatan parameter dan menyederhanakan penyelarasan lintas modal di dalam backbone transformer, yang menurut para penulis menghasilkan kompromi efisiensi/kualitas yang menguntungkan untuk model 6B.
Decoupled-DMD dan DMDR (distilasi + RL)
Untuk memungkinkan generasi beberapa langkah (8 langkah) tanpa penalti kualitas yang biasa, tim mengembangkan pendekatan distilasi Decoupled-DMD. Teknik ini memisahkan augmentasi CFG (classifier-free guidance) dari pencocokan distribusi, memungkinkan masing-masing dioptimalkan secara independen. Mereka kemudian menerapkan langkah reinforcement learning pasca-pelatihan (DMDR) untuk memperhalus penyelarasan semantik dan estetika. Kombinasi keduanya menghasilkan Z-Image-Turbo dengan jauh lebih sedikit NFE dibandingkan model difusi tipikal sambil mempertahankan realisme tinggi.
Throughput pelatihan dan optimisasi biaya
Z-Image dilatih dengan pendekatan optimisasi siklus hidup: pipeline data terkurasi, kurikulum yang disederhanakan, dan pilihan implementasi yang sadar efisiensi. Para penulis melaporkan menyelesaikan keseluruhan alur pelatihan dalam sekitar 314K jam GPU H800 (≈ USD $630K) — metrik rekayasa yang eksplisit dan dapat direproduksi yang memposisikan model ini sebagai hemat biaya dibandingkan alternatif yang sangat besar (>20B).
Hasil Benchmark Model Z-Image
Z-Image-Turbo menempati peringkat tinggi pada beberapa leaderboard kontemporer, termasuk posisi teratas open-source pada leaderboard Artificial Analysis Text-to-Image dan performa kuat pada evaluasi preferensi manusia di Alibaba AI Arena.
Namun, kualitas dunia nyata juga bergantung pada perumusan prompt, resolusi, pipeline upscaling, dan pemrosesan pasca tambahan.
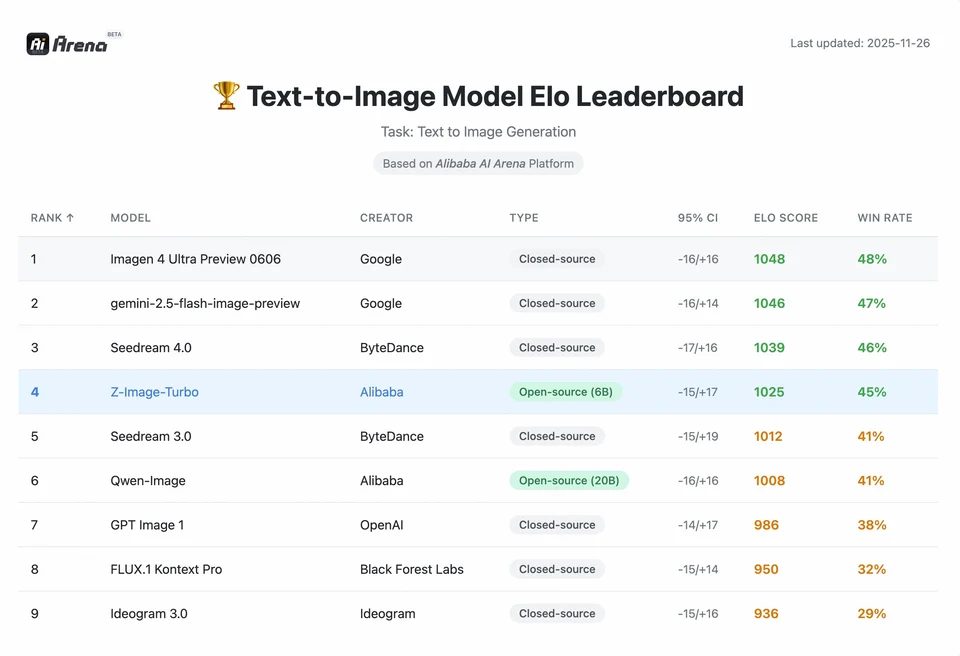
Untuk memahami besarnya pencapaian Z-Image, kita harus melihat data. Di bawah ini adalah analisis perbandingan Z-Image terhadap model open-source dan proprietari terkemuka.
Ringkasan Benchmark Komparatif
| Fitur / Metrik | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Arsitektur | S3-DiT (Aliran Tunggal) | MM-DiT (Aliran Ganda) | U-Net | Transformer Difusi |
| Parameter | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Langkah Inferensi | 8 Langkah | 25 - 50 Langkah | 1 - 4 Langkah | 30 - 50 Langkah |
| VRAM yang Diperlukan | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Perenderan Teks | Tinggi (EN + CN) | Tinggi (EN) | Sedang (EN) | Tinggi (CN + EN) |
| Kecepatan Generasi (4090) | ~1.5 - 3.0 Detik | ~15 - 30 Detik | ~0.5 Detik | ~20 Detik |
| Skor Fotorealisme | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Lisensi | Apache 2.0 | Non-Komersial (Dev) | OpenRAIL | Custom |
Analisis Data & Wawasan Performa
- Kecepatan vs. Kualitas: Walau SDXL Turbo lebih cepat (1 langkah), kualitasnya menurun signifikan pada prompt yang kompleks. Z-Image-Turbo mencapai "sweet spot" pada 8 langkah, menyamai kualitas Flux.2 sambil 5x hingga 10x lebih cepat.
- Demokratisasi Perangkat Keras: Flux.2, meskipun kuat, pada praktiknya terbatasi oleh kartu VRAM 24GB (RTX 3090/4090) untuk performa yang layak. Z-Image memungkinkan pengguna dengan kartu kelas menengah (RTX 3060/4060) membuat gambar 1024x1024 setara profesional secara lokal.
Bagaimana pengembang dapat mengakses dan menggunakan Z-Image?
Ada tiga pendekatan umum:
- Hosted / SaaS (web UI atau API): Gunakan layanan seperti z-image.ai atau penyedia lain yang mendepoy model dan menyediakan antarmuka web atau API berbayar untuk generasi gambar. Ini adalah jalur tercepat untuk eksperimen tanpa penyiapan lokal.
- Hugging Face + pipeline diffusers: Pustaka
diffusersdari Hugging Face mencakupZImagePipelinedanZImageImg2ImgPipelineserta menyediakan alur kerjafrom_pretrained(...).to("cuda")yang umum. Ini adalah jalur yang direkomendasikan bagi pengembang Python yang menginginkan integrasi sederhana dan contoh yang dapat direproduksi. - Inferensi native lokal dari repo GitHub: Repo Tongyi-MAI menyertakan skrip inferensi native, opsi optimisasi (FlashAttention, kompilasi, CPU offload), dan petunjuk untuk memasang
diffusersdari sumber untuk integrasi terbaru. Rute ini berguna bagi peneliti dan tim yang menginginkan kontrol penuh atau menjalankan pelatihan/fine-tuning kustom.
Seperti apa contoh Python minimal?
Di bawah ini cuplikan Python ringkas menggunakan diffusers dari Hugging Face yang mendemonstrasikan generasi teks-ke-gambar dengan Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Catatan: nilai bawaan dan pengaturan yang direkomendasikan untuk guidance_scale berbeda pada model Turbo; dokumentasi menyarankan guidance dapat diatur rendah atau nol untuk Turbo tergantung perilaku yang dituju.
Bagaimana menjalankan image-to-image (edit) dengan Z-Image?
ZImageImg2ImgPipeline mendukung pengeditan gambar. Contoh:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Ini mencerminkan pola penggunaan resmi dan cocok untuk tugas pengeditan kreatif serta inpainting.
Bagaimana sebaiknya Anda menyusun prompt dan guidance?
- Jelaskan struktur secara eksplisit: Untuk adegan kompleks, susun prompt agar mencakup komposisi adegan, objek fokus, kamera/lensa, pencahayaan, suasana, dan elemen tekstual. Z-Image diuntungkan oleh prompt yang detail dan dapat menangani isyarat posisional/naratif dengan baik.
- Sesuaikan guidance_scale dengan hati-hati: Model Turbo mungkin merekomendasikan nilai guidance lebih rendah; eksperimen diperlukan. Untuk banyak alur kerja Turbo,
guidance_scale=0.0–1.0dengan seed dan langkah tetap menghasilkan hasil yang konsisten. - Gunakan image-to-image untuk edit terkontrol: Saat Anda perlu mempertahankan komposisi namun mengubah gaya/pewarnaan/objek, mulailah dari gambar awal dan gunakan
strengthuntuk mengontrol besarnya perubahan.
Kasus Penggunaan Terbaik dan Praktik Terbaik
1. Prototipe Cepat & Storyboarding
Kasus: Sutradara film dan desainer gim perlu memvisualisasikan adegan secara instan.
Mengapa Z-Image? Dengan generasi di bawah 3 detik, kreator dapat mengiterasi ratusan konsep dalam satu sesi, menyempurnakan pencahayaan dan komposisi secara real-time tanpa menunggu menit untuk render.
2. E-Commerce & Periklanan
Kasus: Menghasilkan latar produk atau foto gaya hidup untuk barang dagangan.
Praktik Terbaik: Gunakan Z-Image-Edit.
Unggah foto produk mentah dan gunakan prompt instruksi seperti "Letakkan botol parfum ini di atas meja kayu di taman yang diterangi matahari." Model mempertahankan integritas produk sambil menghalusinasi latar belakang fotorealistik.
3. Pembuatan Konten Dwibahasa
Kasus: Kampanye pemasaran global yang membutuhkan aset untuk pasar Barat dan Asia.
Praktik Terbaik: Manfaatkan kemampuan perenderan teks.
- Prompt: "Sebuah papan neon bertuliskan 'OPEN' dan '营业中' yang menyala di gang gelap."
- Z-Image akan merender dengan benar baik karakter bahasa Inggris maupun Tionghoa—sebuah pencapaian yang gagal dilakukan oleh sebagian besar model lain.
4. Lingkungan Sumber Daya Rendah
Kasus: Menjalankan generasi AI pada perangkat edge atau laptop kantor standar.
Tip Optimisasi: Gunakan versi terkuantisasi INT8 dari Z-Image. Ini mengurangi penggunaan VRAM menjadi di bawah 6GB dengan kehilangan kualitas yang dapat diabaikan, membuatnya layak untuk aplikasi lokal di laptop non-gaming.
Intinya: siapa yang sebaiknya menggunakan Z-Image?
Z-Image dirancang untuk organisasi dan pengembang yang menginginkan fotorealisme berkualitas tinggi dengan latensi dan biaya yang praktis, serta yang lebih menyukai lisensi terbuka dan hosting on-premises atau kustom. Model ini sangat menarik bagi tim yang membutuhkan iterasi cepat (perangkat kreatif, mockup produk, layanan real-time) dan bagi peneliti/anggota komunitas yang tertarik melakukan fine-tuning pada model gambar yang ringkas namun bertenaga.
CometAPI menawarkan model Grok Image yang serupa namun lebih sedikit pembatasan, serta model seperti Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) dan lain-lain—dengan catatan Anda memiliki tips dan trik NSFW yang tepat untuk melewati pembatasan dan mulai berkarya secara bebas. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga jauh lebih rendah daripada harga resmi untuk membantu Anda mengintegrasikan.
Siap mulai?→ Uji coba gratis untuk membuat !