

Anthropic’s Claude Opus 4.6 arrived in February 2026 as a clear, purpose-built push toward enterprise-grade agents, long-context knowledge work, and stronger autonomous coding. The release mixes ambitious engineering (a beta one-million-token context mode, an “adaptive thinking” capability, and agent teamwork features) with a pragmatic commercial decision: Anthropic kept API pricing consistent with its previous Opus family models. That combination — materially improved capabilities without an immediate price jump — is the headline.
What exactly is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic’s flagship in the Opus line: a large-scale, enterprise-focused generative AI model optimized for agentic workflows, coding, and long-horizon knowledge work. Anthropic positions Opus 4.6 as their most intelligent model for building agents and automations — something designed not just to answer queries but to plan, call tools, coordinate sub-agents, and follow multi-step tasks across large codebases and document corpora.
Unlike consumer-oriented chatbots, Opus 4.6 targets enterprise integrations: it’s available through Anthropic’s claude.ai UI, the Claude API, and via CometAPI. Opus 4.6’s strength for agentic coding tasks and tool calling. For enterprises, this means Opus 4.6 is positioned as a drop-in upgrade for agentic assistants, code migration tools, document review pipelines, and analytical workflows that need broader context than typical chat sessions provide.
In-depth analysis of key new features in Opus 4.6
One-million-token context (and practical modes)
Opus 4.6 supports an expanded default context window (advertised at 200K tokens with a 1M token context window available in beta). A million-token window is transformational on paper: it enables the model to hold entire code repositories, long legal briefs, multi-year email archives, or large data tables in a single conversation, which reduces the need for external retrieval scaffolding. Anthropic pairs the raw context window with “context compaction” tools that help compress relevant information and reduce token costs. In short: Opus can legitimately work with very large artifacts without chopping them into fragments, which simplifies building long-lived agents.
Why it matters: for code refactoring, legal/financial review, or research projects that require cross-document reasoning, the larger window reduces engineering overhead (fewer retrievals, less state management) and improves coherence over very long chains of reasoning.
Adaptive thinking and extended reasoning controls
Opus 4.6 introduces what Anthropic calls “adaptive thinking” (an evolution of the company’s earlier “extended thinking” ideas). This is both an internal capability and an API control: developers can tune the model’s “effort levels” and planning depth, letting it spend more compute on complicated planning or keep replies short and fast for trivial tasks.
Why it matters: agentic workflows are where marginal quality improvements compound: better planning + coordination means fewer human corrections and more reliable autonomous execution.
What is “agent teams” and agentic orchestration?
Opus 4.6 introduces improved support for agentic workflows: the ability to spawn, coordinate, and supervise multiple subagents that divide and conquer tasks. Anthropic’s materials (and early partner reports) stress that Opus can proactively create subagents, assign subtasks, monitor their progress, and terminate or shift strategies as needed — effectively acting as a lightweight orchestrator for complex, multi-step engineering or analysis work. This tight integration between planning, tool use, and error-correction is a core selling point for automation-heavy teams.
API and tooling improvements for enterprise integration
Anthropic expanded API controls for compaction, persistence, and tool-calling. The model supports larger output limits (Anthropic notes up to 128K output tokens), finer retrieval semantics, and enterprise integrations for Microsoft 365 and developer environments. The practical upshot is less glue code when hooking Opus into spreadsheets, slide decks, and internal toolchains. Anthropic has integrated Opus 4.6 into higher level tooling like Claude Cowork (no-code interfaces) and updates to Claude Code that let non-technical users access automation.
How does Opus 4.6 perform on benchmarks?
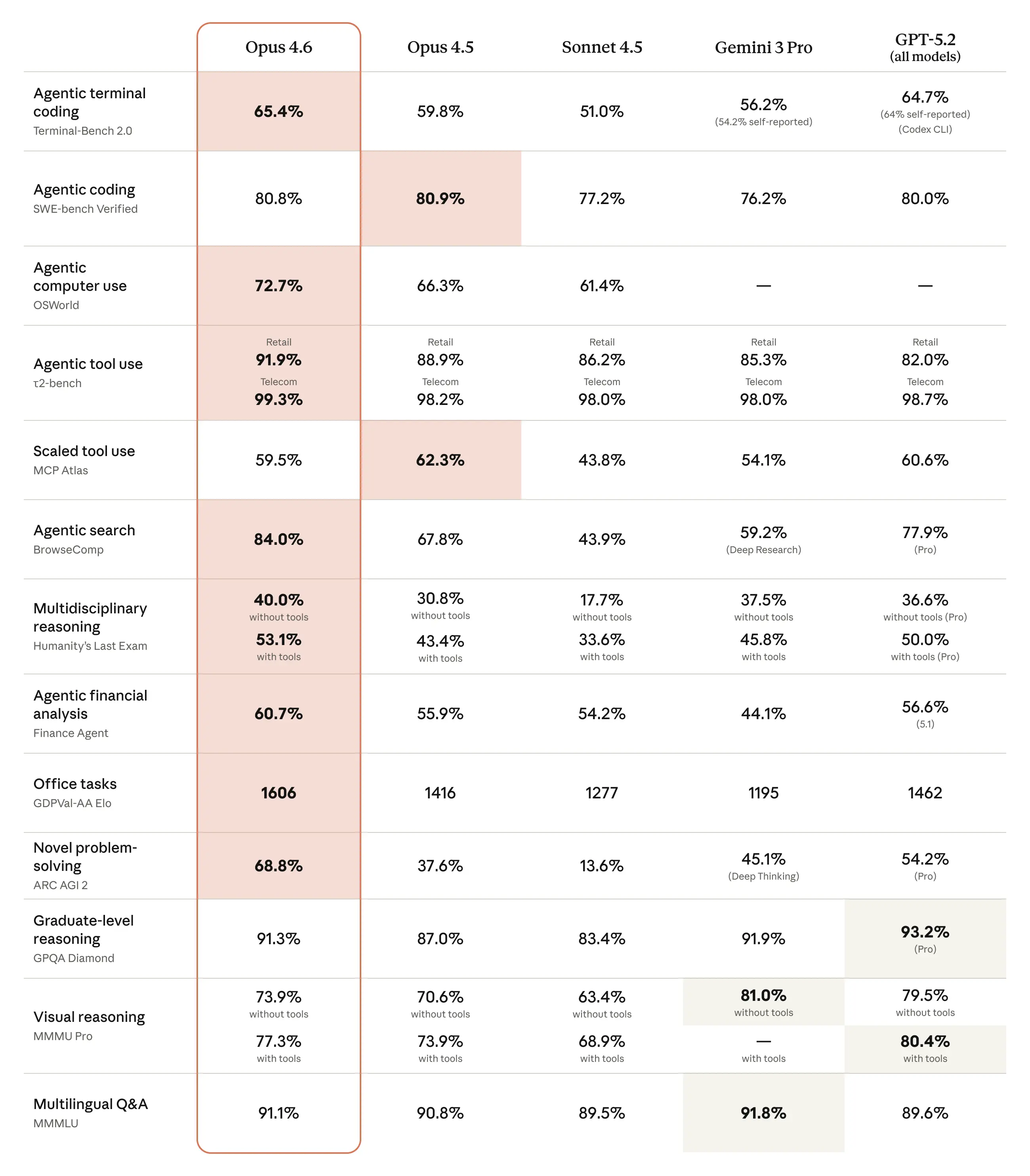
Opus 4.6 gains versus Opus 4.5 and show competitive placements against recent models from OpenAI and Google on a mix of coding, reasoning, and domain-specific suites. Examples reported in brief:
- BigLaw Bench: Opus 4.6 reached ~90.2% on Anthropic’s BigLaw Bench (legal reasoning).
- Terminal-Bench 2.0 / GDPval metrics: independent coverage lists Terminal-Bench 2.0 scores and GDPval-AA Elo ratings that place Opus 4.6 ahead of Opus 4.5 and competitive with some recent releases from rivals. One report listed a Terminal-Bench 2.0 score of 65.4% and GDPval-AA Elo ~1,606.
Anthropic reports large gains in agentic coding tasks, with better planning, fewer iterations, and stronger performance on huge codebases — including claims of planning and executing migrations on multi-million-line repos in less time. The model’s improved ability to “self-catch” errors and sustain reasoning across many steps is emphasized.
How much does Opus 4.6 cost?
Short answer — per-token pricing
- Standard (prompts ≤ 200K tokens): $5 / 1M input tokens and $25 / 1M output tokens.
- Large prompts (prompts > 200K tokens): $10 / 1M input and $37.50 / 1M output.
- Fast mode (research preview): a premium tier — $30 / 1M input and $150 / 1M output (faster inference).
Practical cost considerations:
- Agentic workflows tend to be token-expensive. Multi-step planning, tool calls, and long outputs increase output tokens; careful use of compaction and cache reads matters to control billings.
- Batching saves money. If your workload fits asynchronous batch processing, Anthropic’s batch API pricing can materially reduce per-token costs.
- Premium context is pricier. If you rely on the 1M token beta frequently, plan for higher per-token charges. Many organizations will mix modes: large contexts only where absolutely necessary and lean sessions elsewhere.
Looking for cheaper solutions to use the Claude API
CometAPI is a good choice. The Opus 4.6 API also comes from Anthropic, but its API pricing is 20% of the official price, and this doesn't change with changes in context length.
How does Opus 4.6 compare to GPT-5.3 and Google Gemini 3?
Opus 4.6 vs OpenAI’s GPT-5.3
OpenAI’s recent GPT-5.3 (branded by OpenAI in the “Codex” line for coding / agent tasks) is explicitly tuned for deep coding and agent-style workflows and claims industry-leading scores on several engineering benchmarks (SWE-Bench Pro, Terminal-Bench). Early coverage suggests GPT-5.3-Codex pushes state-of-the-art in software-engineering benchmarks and agentic planning, positioning it as Opus 4.6’s closest direct rival in pure coding and agentic tasks. Opus 4.6—by contrast—emphasizes extremely long context and multi-agent orchestration as differentiators. In short: GPT-5.3 looks optimized for raw engineering depth and benchmark dominance on developer-centric tests; Opus 4.6 emphasizes breadth across long-context enterprise workflows and domain reasoning.
Opus 4.6 vs Google Gemini 3?
Google’s Gemini 3 (and Gemini 3 Pro / Deep Think variants) has been highlighted for strong performance on abstract reasoning, visual problem-solving, and certain scientific QA benchmarks; it has also pushed advanced multimodal reasoning further than its predecessors. Coverage positions Gemini 3 as particularly strong on scientific and visual reasoning suites, while Opus 4.6’s win is in long-context code and legal/enterprise work. For organizations that need multimodal scientific reasoning or advanced visual-logic tasks, Gemini 3 may hold an edge; for sustained, long-context knowledge work and multi-agent automation, Opus 4.6 stakes a claim.
Who “wins” in head-to-heads?
No single vendor “wins” universally: the choice depends on the workflow you care about. Early independent comparisons show Opus 4.6 outperforming Opus 4.5 by a meaningful margin on long-horizon and domain tasks, while GPT-5.3 and Gemini 3 maintain advantages in certain coding and multimodal testbeds. As with any rapidly evolving generation, the winner is the customer who maps model strengths to real-world workloads and tooling integration, not the model with the highest single benchmark.
Is the Claude Opus 4.6 worth it?
Short answer: Yes — if your primary problems are long-context reasoning, autonomous agent workflows, or enterprise compliance. Opus 4.6’s strengths are real and relevant: the 200K (and beta 1M) windows, adaptive thinking, agent teams, and enterprise integrations are tangible upgrades that reduce product engineering complexity and increase the class of problems you can automate.
If instead your workload is predominantly short, highly repetitive microtasks where unit cost and latency are paramount, Opus 4.6 may be overkill compared with a short-horizon specialist model (e.g., GPT-5.3 Codex) — unless you plan to combine them and route tasks appropriately.
CometAPI is a one-stop aggregation platform for large model APIs, offering seamless integration and management of API services. It supports the invocation of various mainstream AI models.This includes image generation, video generation, chat, TTS, and STT AI, all on one platform.
You can also choose the model you want based on your desired cost and model capabilities, and switch between them at any time, such as Gemini 3 Flash, GPT 5.3, or Opus 4.6. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo code today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!