

Il team Qwen di Alibaba ha rilasciato Qwen3-Max-Preview (Istruzione) — il modello più grande dell'azienda fino ad oggi, con più di 1 trilione di parametri — e lo ha reso immediatamente disponibile tramite Qwen Chat, Alibaba Cloud Model Studio (API) e marketplace di terze parti come CometAPI. L'anteprima è rivolta a flussi di lavoro di ragionamento, codifica e documenti lunghi, combinando un'estrema scalabilità con una finestra di contesto molto ampia e il caching del contesto per mantenere bassa la latenza durante le sessioni lunghe.
Punti salienti tecnici chiave
- Numero enorme di parametri (oltre mille miliardi): Il passaggio a un modello con oltre mille miliardi di parametri è progettato per aumentare la capacità di apprendimento di pattern complessi (ragionamento multi-step, sintesi del codice, comprensione approfondita dei documenti). I primi benchmark rilasciati da Qwen indicano risultati migliori in termini di ragionamento, codifica e suite di benchmark rispetto ai precedenti modelli di punta di Qwen.
- Contesto ultra lungo e memorizzazione nella cache: . Gettone da 262k Window consente ai team di alimentare interi report di grandi dimensioni, basi di codice multi-file o lunghe cronologie di chat in un'unica operazione. Il supporto per la memorizzazione nella cache del contesto riduce l'elaborazione ripetuta per il contesto ricorrente e può ridurre la latenza e i costi per sessioni prolungate.
- Capacità di programmazione multilingue: La famiglia Qwen3 privilegia il supporto bilingue (cinese/inglese) e un ampio supporto multilingue, oltre a una codifica più solida e una gestione strutturata dell'output, utili per gli assistenti di programmazione, la generazione automatica di report e l'analisi di testo su larga scala.
- Progettato per velocità e qualità. Gli utenti dell'anteprima descrivono una velocità di risposta "strabiliante" e un miglioramento nel seguire le istruzioni e nel ragionamento rispetto alle precedenti varianti di Qwen3. Alibaba posiziona il modello come un fiore all'occhiello ad alta produttività per scenari di produzione, agenti e di sviluppo.
Disponibilità e accesso
Costi di Alibaba Cloud a livelli, basato su token prezzi per Qwen3-Max-Preview (tariffe di input e output separate). La fatturazione è per milione di token e applicata ai token effettivamente consumati dopo qualsiasi quota gratuita.
I prezzi di anteprima pubblicati da Alibaba (USD) sono suddivisi in livelli in base alla richiesta ingresso volume del token (gli stessi livelli determinano quali tariffe unitarie si applicano):
- Token di input da 0 a 32K: $0.861 / 1 milione di token di input e al $3.441 / 1 milione di token di output.
- Token di input da 32K a 128K: $1.434 / 1 milione di token di input e al $5.735 / 1 milione di token di output.
- Token di input da 128K a 252K: $2.151 / 1 milione di token di input e al $8.602 / 1 milione di token di output.
CometAPI offre uno sconto ufficiale del 20% per aiutare gli utenti a chiamare l'API, i dettagli si riferiscono a Anteprima Qwen3-Max:
| Token di input | $0.24 |
| Gettoni di uscita | $2.42 |
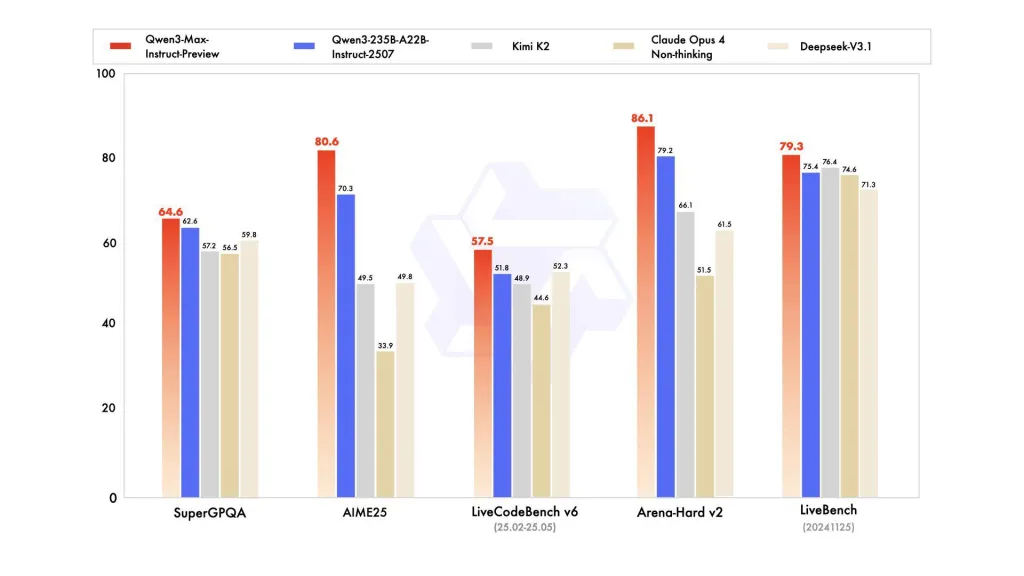
Qwen3-Max amplia la famiglia Qwen3 (che ha utilizzato design ibridi come le varianti Mixture-of-Experts e più livelli di parametri attivi nelle build precedenti). Le precedenti versioni di Qwen3 di Alibaba si concentravano sia sulla modalità "thinking" (ragionamento passo-passo) che su quella "instruct"; Qwen3-Max si posiziona come la nuova variante instruct di fascia alta in quella linea, dimostrando di superare il precedente prodotto più performante dell'azienda, Qwen3-235B-A22B-2507, dimostrando che il modello di parametri 1T è leader in una vasta gamma di test.
Su SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2 e LiveBench (20241125), Qwen3-Max-Preview si posiziona costantemente davanti a Claude Opus 4, Kimi K2 e Deepseek-V3.1.
Come accedere e utilizzare Qwen3-Max (guida pratica)
1) Provalo nel browser (Qwen Chat)
Visita Chat di Qwen (interfaccia web/chat ufficiale di Qwen) e seleziona Anteprima Qwen3-Max Modello (di istruzione) se visualizzato nel selettore del modello. Questo è il modo più rapido per valutare visivamente le attività di conversazione e di istruzione.
2) Accesso tramite Alibaba Cloud (Studio modello / API cloud)
- Accedi ad Alibaba Cloud → Studio di modelli / Servizio di modelliCrea un'istanza di inferenza o seleziona l'endpoint del modello ospitato per anteprima qwen3-max (o la versione di anteprima etichettata).
- Autenticati utilizzando i tuoi ruoli Alibaba Cloud Access Key/RAM e chiama l'endpoint di inferenza con una richiesta POST contenente il tuo prompt e tutti i parametri di generazione (temperatura, token massimi, ecc.).
3) Utilizzare attraverso host/aggregatori di terze parti
Secondo quanto riportato, l'anteprima è accessibile tramite CometAPI e altri aggregatori di API che consentono agli sviluppatori di richiamare più modelli ospitati con un'unica chiave API. Questo può semplificare i test tra provider, ma consente anche di verificare la latenza, la disponibilità regionale e le policy di gestione dei dati per ciascun host.
Iniziamo
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Conclusione
Qwen3-Max-Preview colloca Alibaba tra le aziende che distribuiscono ai clienti modelli su scala trilioni. La combinazione di un contesto estremamente lungo e di un'API compatibile con OpenAI riduce la barriera di integrazione per le aziende che necessitano di ragionamento su documenti lunghi, automazione del codice o orchestrazione degli agenti. Costi e stabilità dell'anteprima sono le principali considerazioni sull'adozione: le aziende vorranno testare la soluzione con caching, streaming e chiamate in batch per gestire sia la latenza che i prezzi.