

Nei suoi aggiornamenti di ottobre, OpenAI ha riferito che circa 0.15% degli utenti attivi settimanali avere conversazioni che contengono indicatori espliciti di potenziale pianificazione o intento suicida, una quota che, se rapportata all'ampia base di utenti di ChatGPT, corrisponde a più di un milione di persone ogni settimana discutendo di argomenti correlati al suicidio con il servizio, si è puntato l'attenzione su una questione spinosa: i modelli linguistici di grandi dimensioni possono rispondere in modo significativo e sicuro quando le persone portano in una chat gravi problemi di salute mentale, tra cui psicosi, mania, intenti suicidi e profonda dipendenza emotiva?
Pertanto, gli aggiornamenti di ottobre di OpenAI a GPT-5 sono stati implementati in produzione come gpt-5-oct-3 Aggiornamento: rappresentano l'impegno più esplicito e misurato dell'azienda per rendere i modelli linguistici di grandi dimensioni (LLM) più sicuri e utili quando gli utenti sollevano problemi di salute mentale. Le modifiche non rappresentano una soluzione magica; sono un insieme di misure tecniche, di processo e di valutazione volte a ridurre risultati dannosi o inutili, far emergere risorse professionali e scoraggiare gli utenti dall'affidarsi al modello come sostituto dell'assistenza clinica. Ma quanto è migliorato il sistema nella pratica, cosa è cambiato esattamente e quali sono i rischi rimanenti?
Quali aggiornamenti ha apportato OpenAI in gpt-5 e perché è importante?
OpenAI ha distribuito un aggiornamento al modello GPT-5 predefinito di ChatGPT (comunemente indicato nelle comunicazioni come gpt-5-oct-3) destinato specificamente a rafforzare il comportamento del modello in conversazioni sensibili — quelli che includono segni di psicosi o mania, ideazione o pianificazione suicida, o il tipo di dipendenza emotiva da un'intelligenza artificiale che può sostituire le relazioni nel mondo reale.
I cambiamenti sono stati influenzati dalle consultazioni con oltre 170 esperti di salute mentale e da nuove tassonomie interne e valutazioni automatizzate progettate attorno a concreti "comportamenti desiderati", dopo essere state ottimizzate da esperti di psicologia, il modello GPT-5:
- Nei set di sfide mirate alla salute mentale, il nuovo modello GPT-5 ha ottenuto punteggi ~ 92% conforme alla tassonomia comportamentale desiderata dall'azienda (rispetto a percentuali molto più basse per le versioni precedenti su set di test difficili).
- Per gli scenari di autolesionismo e suicidio, le valutazioni automatizzate sono aumentate a ~ 91% conformità da 77% sulla precedente variante GPT-5 nel benchmark specifico descritto. OpenAI segnala anche ~ 65% riduzione dei tassi di risposte “non pienamente conformi” in diversi ambiti della salute mentale nel traffico di produzione.
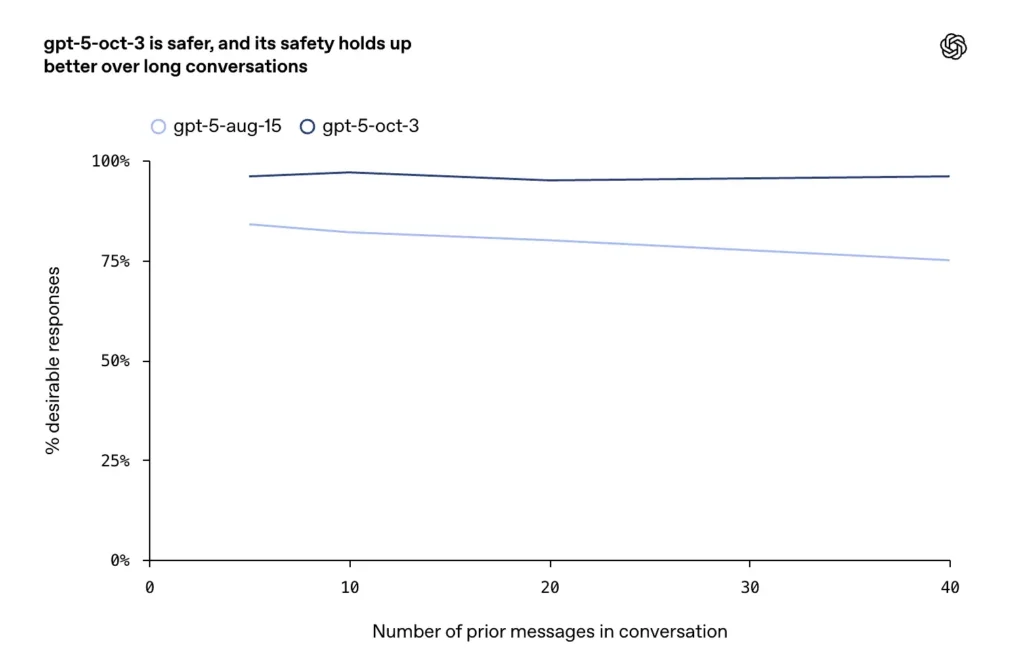
- Sono stati segnalati miglioramenti nelle conversazioni lunghe, conflittuali o prolungate (un noto modo di errore per i modelli di chat), in cui l'azienda afferma che gli aggiornamenti di ottobre mantengono una maggiore coerenza e sicurezza nei turni di dialogo prolungati.
perché è importante
OpenAI ha affermato che, data l'attuale portata di ChatGPT, anche percentuali molto piccole di conversazioni sensibili corrispondono a numeri assoluti molto elevati di persone. L'azienda ha riferito che, in una settimana tipo:
- informazioni 0.07% degli utenti attivi mostrano possibili segni compatibili con psicosi o mania; e
- informazioni 0.15% degli utenti attivi hanno conversazioni che includono indicatori espliciti di potenziale pianificazione o intento suicida; e
- approssimativamente 0.15% degli utenti attivi mostrano “livelli elevati” di attaccamento emotivo a ChatGPT.
Per rendere concrete queste percentuali: il CEO di OpenAI ha affermato che ChatGPT ha ~800 milioni di utenti attivi settimanaliMoltiplicando si ottengono i conteggi assoluti degli utenti:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Le categorie sono rumorose e sovrapposte (una singola conversazione potrebbe apparire in più di una categoria) e queste sono stime derivato da tassonomie di rilevamento interne piuttosto che da diagnosi cliniche.
In che modo OpenAI ha implementato questi cambiamenti, ovvero il meccanismo di miglioramento in cinque fasi?
OpenAI descrive un processo articolato e basato sulla consulenza di esperti. Di seguito è riportato un esempio sintetico e riproducibile. meccanismo di miglioramento in cinque fasi che corrisponde alle informative aziendali e alle prassi comuni nell'ingegneria della sicurezza dei modelli.
Meccanismo di miglioramento in cinque fasi
- Tassonomia ed etichettatura guidate da esperti. Riunire psichiatri, psicologi e medici di base per definire i comportamenti e il linguaggio che indicano psicosi/mania, intenzione di autolesionismo o dipendenza emotiva malsana; creare set di dati etichettati e regole di aggiudicazione.
- Raccolta dati mirata e prompt curati. Raccogliere frammenti di conversazioni rappresentative, esempi di casi limite e input avversari; integrare con trascrizioni di giochi di ruolo controllati, prodotte con la supervisione del medico.
- Messa a punto/ottimizzazione del modello con obiettivi di sicurezza. Addestrare o perfezionare il modello di base sul set di dati curato con termini di perdita che penalizzino il rinforzo delle illusioni, forniscano modelli di risposta sicura e promuovano l'instradamento verso le risorse di crisi.
- Classificatore + strato di protezione (sicurezza in fase di esecuzione). Implementare un classificatore rapido o un livello di monitoraggio che rilevi in tempo reale le svolte ad alto rischio e modifichi i parametri di decodifica del modello, passi a un risponditore specializzato o inoltri la richiesta a pipeline di revisione umana. (Ciò è fondamentale per evitare comportamenti instabili quando la conversazione si disperde.)
- Valutazione umana da parte di esperti e calibrazione continua. Chiedete ai medici di valutare alla cieca le risposte del modello utilizzando rubriche di valutazione clinica; misurate i tassi di risposta indesiderati; ripetete la tassonomia, i dati di training e i prompt di sistema. Mantenete la telemetria di produzione e rieseguite regolarmente i benchmark.
Di seguito è riportato uno pseudocodice compatto/schema tecnico che cattura il flusso di runtime implementato dalla maggior parte dei team di sicurezza (questo è illustrativo e non proprietari):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
La pipeline di produzione in genere prevede classificatori a breve termine (veloci), risponditori rallentati ma di qualità superiore (richieste specializzate/punti di controllo ottimizzati) e revisione umana per i casi segnalati. Non si tratta di un aspetto puramente accademico: i medici hanno esaminato oltre 1,800 risposte modello e le hanno classificate in base alla tassonomia, e che tali revisioni hanno influenzato in modo sostanziale il modo in cui sono stati scritti i prompt e i comportamenti di fallback.
Il pubblico di OpenAI ha dichiarato di aver utilizzato varianti di tutti e cinque i passaggi e valutazioni dei medici per valutare i risultati:
- Gli esperti hanno esaminato oltre 1,800 risposte modello.
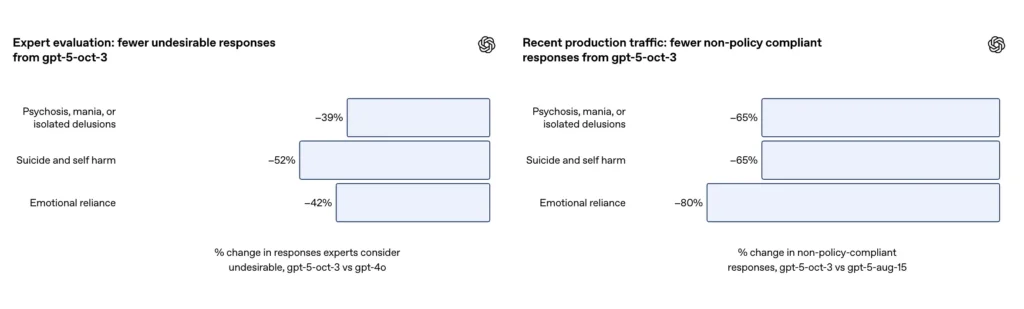
- GPT-5 ha ridotto le “risposte insoddisfacenti” del 39-52% in tutte le categorie.
- L'affidabilità inter-valutatore variava dal 71 al 77%, indicando un alto grado di consenso generale nonostante le differenze soggettive.
Come reagisce ora il GPT-5 alla psicosi o alla mania?
Cosa OpenAI ha insegnato al modello a fare (e cosa non fare)
Misurare: Migliorare il riconoscimento e la risposta del modello a sintomi gravi come allucinazioni e mania. Per le conversazioni che segnalano possibili convinzioni deliranti, allucinazioni o mania, OpenAI ha riscritto parti delle specifiche del modello e fornito esempi di addestramento supervisionato in modo che GPT-5 risponda senza confermare o amplificare convinzioni infondate. Il modello è incoraggiato a essere empatico, a evitare di convalidare le illusioni e a riformulare o indirizzare delicatamente l'utente verso misure di sicurezza pratiche e un aiuto professionale quando necessario.
Cosa mostra la valutazione
OpenAI riferisce che su un set di test di conversazioni impegnative su psicosi/mania, il nuovo GPT-5 ha ridotto sostanzialmente le risposte indesiderate rispetto ai precedenti valori di riferimento e che le valutazioni automatizzate hanno assegnato al modello aggiornato un punteggio elevato di conformità nella loro tassonomia.
| Metrico | GPT-4o | GPT-5 | Progresso |
|---|---|---|---|
| Tasso di risposta non conforme | Linea di base | ↓ 65% | Miglioramento significativo |
| Valutazione clinica degli esperti | - | Risposte avverse ridotte del 39% | - |
| Tasso di conformità alla valutazione automatica | 27% | 92% | ↑65 punti percentuali |
| Tasso di coinvolgimento dell'utente | ~0.07% utenti attivi settimanali | Estremamente basso ma chiaramente monitorato | - |
Nota:
- Le risposte inappropriate sono diminuite del 65%;
- Solo lo 0.07% degli utenti e lo 0.01% dei messaggi contenevano tali contenuti;
- Nelle valutazioni degli esperti, GPT-5 ha prodotto il 39% in meno di risposte inappropriate rispetto a GPT-4o;
- Nelle valutazioni automatizzate, GPT-5 ha raggiunto un tasso di conformità del 92% (rispetto al 27% del suo predecessore).
In che modo il GPT-5 affronta l'ideazione suicidaria e l'autolesionismo?
Instradamento più forte per supportare e rifiuto di fornire istruzioni
OpenAI descrive un addestramento esteso ed esplicito per i casi di autolesionismo e suicidio: il modello è addestrato a riconoscere segnali diretti e indiretti di intenzione o pianificazione, a fornire un linguaggio empatico e de-escalation, a presentare risorse di crisi (linee di assistenza, istruzioni di emergenza locali) e a rifiutarsi di fornire istruzioni per l'autolesionismo. Gli aggiornamenti di ottobre sottolineano un comportamento più duraturo nelle conversazioni lunghe, mentre i modelli precedenti a volte tendevano a dare risposte insicure o incoerenti.
Risultati misurati
In una serie di valutazioni curate di conversazioni impegnative su autolesionismo e suicidio, OpenAI segnala che il GPT-5 aggiornato ha raggiunto Conformità al 91%. con i comportamenti desiderati di OpenAI, rispetto a 77% per il precedente modello GPT-5. L'azienda afferma inoltre che gli esperti in materia hanno ritenuto che il modello aggiornato riducesse le risposte indesiderate di circa 52% rispetto a GPT-4o sullo stesso set di problemi. Inoltre, OpenAI afferma che una stima Riduzione 65% nel traffico di produzione di risposte che “non sono pienamente conformi” alla loro tassonomia per le situazioni di autolesionismo dopo l’implementazione delle nuove misure di sicurezza.
| Metrico | GPT-4o | GPT-5 | Progresso |
|---|---|---|---|
| Tasso di risposta inappropriato | Linea di base | ↓ 65% | Miglioramento significativo |
| Valutazione degli esperti clinici | - | Risposte inappropriate ridotte del 52% | - |
| Tasso di conformità alla valutazione automatica | 77% | 91% | ↑14 punti percentuali |
| Tasso di coinvolgimento dell'utente | 0.15% settimanale (milioni di utenti) | Molto basso ma socialmente significativo | - |
Nota:
- Le risposte inappropriate sono diminuite del 65%;
- Circa lo 0.15% degli utenti e lo 0.05% dei messaggi comportavano potenziali rischi di suicidio;
- Le valutazioni degli esperti hanno dimostrato che GPT-5 ha ridotto le risposte inappropriate del 52% rispetto a GPT-4o;
- Il tasso di conformità nelle valutazioni automatizzate è aumentato al 91% (rispetto al 77% della generazione precedente);
- Nelle conversazioni prolungate, GPT-5 ha mantenuto una stabilità superiore al 95%.
Che cosa si intende per “dipendenza emotiva” e come è stata affrontata?
La sfida degli utenti che formano legami
OpenAI definisce la dipendenza emotiva come modelli in cui un utente mostra una dipendenza potenzialmente malsana dall'IA a scapito delle relazioni, delle responsabilità o del benessere nel mondo reale. Non si tratta di un'immediata violazione della sicurezza fisica, come lo sono le istruzioni per l'autolesionismo, ma di un problema di sicurezza comportamentale che può erodere il supporto sociale e la resilienza di una persona nel tempo. L'azienda ha reso la dipendenza emotiva una categoria esplicita nel suo lavoro di specificazione del modello e ha insegnato al modello a incoraggiare la connessione nel mondo reale, a normalizzare il contatto con le persone e a evitare un linguaggio che rafforza l'esclusività dell'attaccamento.
In queste conversazioni, il modello è stato addestrato a:
- Incoraggiare gli utenti a contattare amici, familiari o uno psicoterapeuta;
- Evitare di rafforzare l'attaccamento all'IA;
- Rispondere alle illusioni o alle false credenze in modo gentile e razionale.
Risultati riportati
Secondo l'addendum di OpenAI, l'aggiornamento ha prodotto un ~80% di riduzione nel tasso di risposte del modello che non sono pienamente conformi alla tassonomia della dipendenza emotiva nel traffico di produzione. Nelle conversazioni di valutazione curate, le valutazioni automatizzate hanno valutato il modello aggiornato a Conformità al 97%. con il comportamento desiderato per gli scenari di dipendenza emotiva, rispetto al 50% del precedente GPT-5. I numeri suggeriscono un notevole miglioramento rispetto alla tassonomia specifica e al set di test; tuttavia, la misurazione della dipendenza emotiva in natura è intrinsecamente rumorosa e sensibile alle differenze culturali e contestuali.
| Metrico | GPT-4o | GPT-5 | Progresso |
|---|---|---|---|
| Tasso di risposta non conforme | 50% | 97% compatibile | ↓80% risposte inappropriate |
| Valutazione degli esperti | Risposte inappropriate ridotte del 42% | - | - |
| Tasso di coinvolgimento dell'utente | 0.15% utenti/settimana, 0.03% messaggi | Raro ma esiste | - |
| Comportamento del modello | Incoraggia le relazioni nel mondo reale; rifiuta la “simulazione di romanticismo sociale” | - | - |
Nota:
- Le risposte inappropriate sono diminuite del 80%;
- Circa lo 0.15% degli utenti/0.03% dei messaggi ha mostrato segni di potenziale dipendenza emotiva dall'IA;
- La valutazione degli esperti ha dimostrato che GPT-5 ha ridotto le risposte inappropriate del 42% rispetto a GPT-4o;
- La conformità alla valutazione automatizzata è migliorata significativamente, passando dal 50% al 97%.
Quali sono i limiti e i rischi in sospeso?
Falsi negativi e falsi positivi
- Falsi negativi: il modello potrebbe non riuscire a identificare segnali sottili o codificati che indicano che un utente è in grave pericolo, soprattutto quando le persone comunicano in modo obliquo o in codice.
- Falsi positivi: il sistema potrebbe intensificare o fornire messaggi di crisi in casi che non lo richiedono, il che può erodere la fiducia degli utenti o generare allarmi inutili. Entrambi i tipi di errore sono importanti perché influenzano il comportamento degli utenti e la percezione di cura. OpenAI riconosce che il rilevamento è imperfetto.
Eccessiva dipendenza dall’automazione
Anche il modello migliore può incoraggiare alcuni utenti a fare affidamento su risposte di intelligenza artificiale immediate e sempre disponibili, anziché cercare un supporto umano duraturo. OpenAI segnala esplicitamente la dipendenza emotiva come una categoria di sicurezza proprio a causa di questo rischio; gli aggiornamenti dell'azienda cercano di spingere gli utenti verso la connessione umana, ma le dinamiche sociali sono difficili da modificare solo con i messaggi.
Lacune contestuali e culturali
Le frasi di sicurezza che sembrano appropriate in una cultura o lingua possono perdere di vista le sfumature in un'altra. Sono necessarie una localizzazione approfondita e una valutazione culturalmente consapevole; i risultati pubblicati da OpenAI non forniscono ancora una ripartizione completa per lingua o regione.
Esposizione legale ed etica
Quando rari fallimenti hanno conseguenze gravi, le aziende affrontano rischi legali e reputazionali (come evidenziato dalla copertura mediatica e dalle cause legali). La trasparenza di OpenAI sulla portata del problema e sui suoi sforzi per mitigare i danni è un passo importante, ma richiede anche un controllo normativo e legale.
Quindi, GPT-5 è ora in grado di gestire i problemi di salute mentale?
Risposta breve: È significativamente migliore in molti compiti ristretti e misurabilie le metriche pubblicate da OpenAI mostrano riduzioni significative delle risposte indesiderate nelle suite di test per autolesionismo, psicosi/mania e dipendenza emotiva. Si tratta di miglioramenti reali, resi possibili dal contributo di esperti, tassonomie più chiare e una valutazione e un monitoraggio aggressivi. I numeri pubblici dell'azienda – elevati tassi di conformità e forti riduzioni delle risposte non conformi su set selezionati – sono la prova più forte finora che un'ingegneria deliberata e multidisciplinare e la collaborazione clinica possono modificare materialmente il comportamento dei modelli.
Come accedere all'ultima API GPT-5?
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Gli sviluppatori possono accedere API GPT-5 tramite CometAPI, l'ultima versione del modello è sempre aggiornato con il sito ufficiale. Per iniziare, esplora le capacità del modello nel Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!