

Google e la sua divisione di ricerca DeepMind hanno spinto in modo discreto (e poi non così discreto) un altro passo importante nella roadmap di Gemini: Gemini 3.1 Pro. La release, distribuita sulle superfici rivolte ai consumatori CometAPI, è presentata come un aggiornamento di prestazioni e capacità di ragionamento per la famiglia Gemini 3 — promettendo un ragionamento lungo più robusto, una comprensione multimodale migliorata e una migliore scalabilità per applicazioni reali.
Il modello più recente di Google — cos’è Gemini 3.1 Pro?
Gemini 3.1 Pro è il primo aggiornamento incrementale nella famiglia Gemini 3 posizionato come modello di ragionamento “più capace”, ottimizzato per attività multi-step, multimodali e agentiche. Rilasciato in anteprima pubblica a metà febbraio 2026 (anteprima annunciata il 19–20 febbraio 2026), il modello è esplicitamente mirato a scenari che richiedono catene di pensiero sostenute, uso di strumenti e comprensione di contesti lunghi — per esempio: sintesi di ricerca su larga scala, agenti di ingegneria che coordinano strumenti e sistemi, e analisi multimodale di documenti che mescolano testo, immagini, audio e video.
A livello alto, Gemini 3.1 Pro è descritto dai suoi sviluppatori come:
- Nativamente multimodale — in grado di accettare e ragionare su testo, immagini, audio e video.
- Progettato per il contesto lungo — supporta finestre di contesto molto ampie adatte a interi codebase, dossier multi-documento o trascrizioni lunghe.
- Ottimizzato per ragionamento affidabile e flussi di lavoro basati su agenti, ovvero è calibrato per pianificare, chiamare strumenti e verificare gli output su attività multi-step.
Perché questo è importante ora: organizzazioni e sviluppatori stanno passando da “buoni assistenti conversazionali” a “agenti di supporto decisionale e di ricerca ad alto impatto” (redazione legale, sintesi di R&D, comprensione multimodale di documenti). Gemini 3.1 Pro è progettato esplicitamente per quel corridoio — per ridurre le allucinazioni, produrre ragionamenti tracciabili e integrarsi con CometAPI sia per il prototyping sia per la produzione.
Quali sono i punti tecnici salienti e le funzionalità di Gemini 3.1 Pro?
Multimodalità nativa e finestre di contesto estreme
Gemini 3.1 Pro prosegue il focus della linea Gemini sulla multimodalità. Secondo la scheda del modello e le note di prodotto, il modello accetta e ragiona su testo, immagini, audio e video nello stesso pipeline — una capacità che semplifica i flussi di lavoro in cui i tipi di dati sono misti (ad es. deposizioni legali con audio + trascrizione + scansioni). In particolare, il modello supporta una finestra di contesto da 1,000,000-token e può produrre output lunghi (note pubblicate indicano limiti di output a dimensioni molto grandi, adeguate a compiti long-form). Questa scala lo rende adatto a casi d’uso come l’analisi di interi repository di codice, documenti multi-capitolo o trascrizioni lunghe senza ricorrere al chunking.
“Dynamic thinking”: ragionamento migliorato e pianificazione per passi
Google descrive 3.1 Pro come dotato di “thinking” migliorato — cioè una migliore gestione interna della catena di pensiero e selezione dinamica delle strategie di ragionamento in base alla complessità del compito. Il modello è calibrato per attivare una pianificazione esplicita multi-step quando necessario, risultando al contempo efficiente nell’uso dei token. In pratica, questo si traduce in meno allucinazioni per problemi complessi, articolati per passi, e in una migliore coerenza fattuale su benchmark di ragionamento multi-step.
Flussi di lavoro basati su agenti e uso di strumenti
Un focus progettuale principale per 3.1 Pro è la performance agentica: coordinare strumenti, invocare grounding sul web o ricerca, scrivere ed eseguire snippet di codice e verificare gli output tramite passaggi secondari. Google ha integrato 3.1 Pro in prodotti orientati agli agenti (ad es. l’ambiente di sviluppo Antigravity) per consentire ai modelli di eseguire attività che coinvolgono editor, terminale e browser — e registrare artefatti come screenshot e registrazioni del browser per verificare i progressi. Queste funzionalità mirano a ridurre il divario tra modelli che “forniscono consigli” e modelli che effettivamente eseguono flussi di lavoro multi-strumento in modo affidabile.
Sottomode specializzate (Deep Research, Deep Think)
Google abbina 3.1 Pro a “Deep Research” e fa riferimento a una variante “Deep Think” in arrivo. Queste sottomode sono mirate rispettivamente a compiti di ricerca ad alto richiamo e alla massima profondità di ragionamento (a costo di calcolo e latenza extra). Sono pensate per servire analisti, ricercatori e sviluppatori che necessitano di output più deliberati e di maggiore qualità, piuttosto che delle risposte più rapide ed economiche.
Come si comporta Gemini 3.1 Pro nei benchmark?
Gemini 3.1 Pro registra forti guadagni rispetto ai precedenti risultati di Gemini 3 Pro, spesso prendendo il comando su un ampio set di misure di ragionamento multi-step e multimodali — ma rimanendo dietro alcuni concorrenti su compiti specifici specializzati (in particolare alcuni coding avanzati o suite di domande a livello esperto). In breve: miglioramenti ampi con vantaggi circoscritti dei concorrenti in benchmark specialistici.
Principali dichiarazioni sui benchmark e numeri di copertina
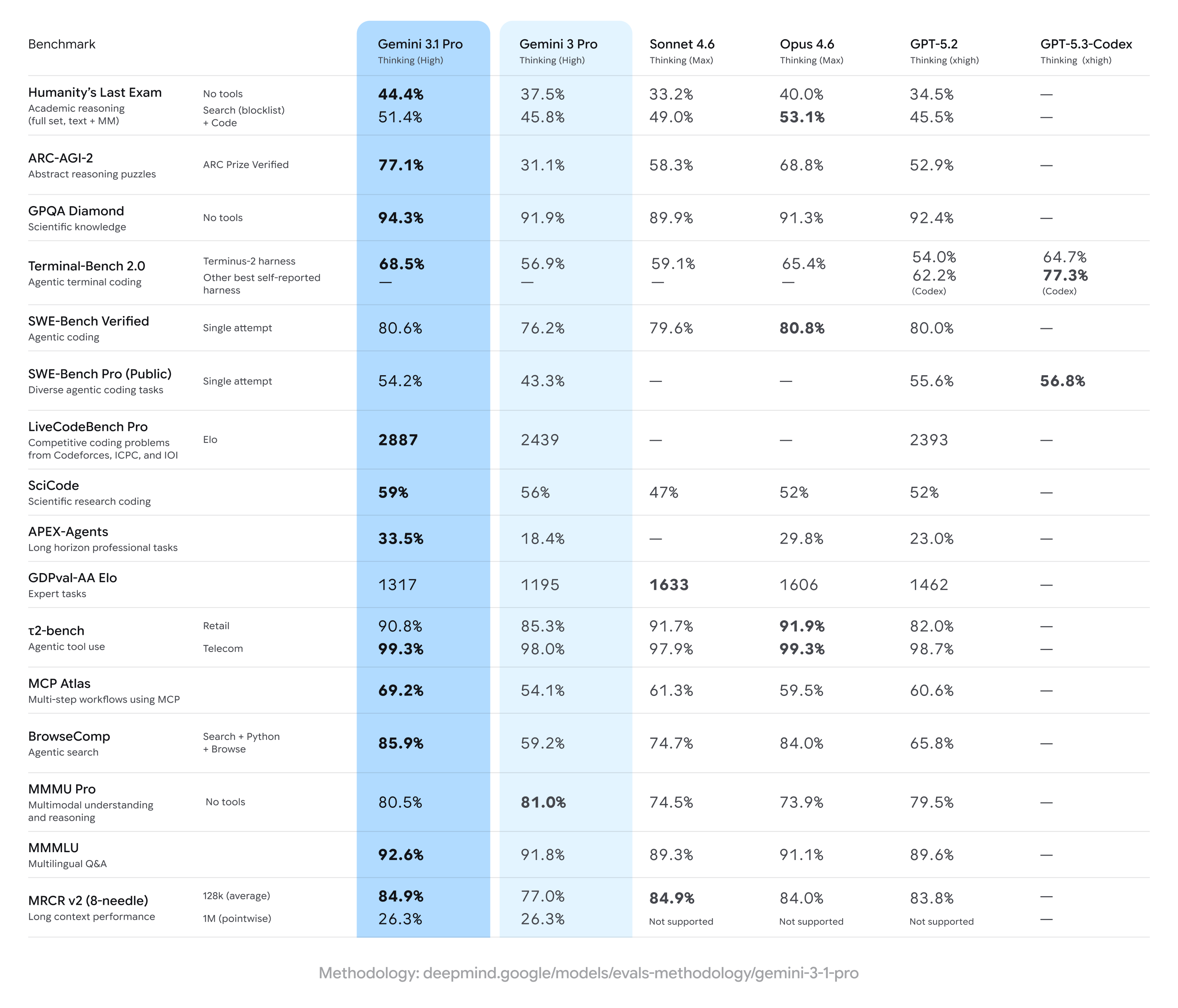
- ARC-AGI-2 (ragionamento astratto / enigmi scientifici multi-step): Gli incrementi riportati per Gemini 3.1 Pro mostrano un miglioramento sostanziale rispetto alle precedenti versioni di Gemini 3 Pro; una suite di test comunitari ha indicato un miglioramento più che doppio su ARC-AGI-2 rispetto al baseline precedente di Gemini 3 Pro in test brevi e mirati. Specifici punteggi riportati (test comunitari) collocano Gemini 3.1 Pro a ~77.1% su alcune aggregazioni in stile ARC (reporting pubblico).
- GPQA Diamond e benchmark scientifici a livello graduate: I dati indicano che Gemini 3.1 Pro ha raggiunto record su GPQA Diamond (un benchmark QA scientifico a livello graduate), superando i modelli Gemini precedenti e fissando una nuova pietra miliare per la famiglia in run indipendenti. Questi guadagni riflettono la migliore calibrazione della catena di pensiero e del ragionamento multi-step del modello.
- “Humanity’s Last Exam” con strumenti abilitati (multi-tool, ragionamento con grounding): In confronti diretti con Claude Opus 4.6 di Anthropic, Claude ha ottenuto 53.1% su questo complesso benchmark con strumenti abilitati mentre Gemini 3.1 Pro ha raggiunto 51.4% nello stesso round di test — mostrando Gemini molto vicino ma non in cima in quell’esame multi-strumento specifico.
- Benchmark di coding e terminale (Terminal-Bench 2.0, SWE-Bench Pro): I benchmark specialistici di coding hanno mostrato maggiore divergenza. Su Terminal-Bench 2.0 con specifici harness, varianti GPT-5.3-Codex hanno segnato circa 77.3% rispetto ai ~68.5% di Gemini 3.1 Pro nelle stesse comparazioni. Su SWE-Bench Pro, risultati pubblici riportano Gemini 3.1 Pro a ~54.2% rispetto ai 56.8% di GPT-5.3-Codex — più ravvicinato, ma con la famiglia Codex di OpenAI che mantiene un vantaggio su compiti di programmazione specialistici in quelle run.
- GDPval-AA Elo (rating di compiti esperti): In un ranking aggregato in stile Elo per compiti esperti, varianti Claude Sonnet/Opus hanno segnato punteggi più alti (ad es. ~1606–1633 punti) mentre un report pubblico ha collocato Gemini 3.1 Pro a ~1317 punti nello stesso dataset — indicando margini di miglioramento su alcuni domini esperti ristretti.
Risultati di prove sul campo e test pratici
Analisi pratiche mostrano che Gemini 3.1 Pro eccelle in particolare in:
- Sintesi a contesto lungo e sintesi multi-documento, dove la finestra da 1M token evita lo chunking soggetto ad artefatti.
- Compiti di comprensione multimodale in cui il grounding immagine + testo migliora l’estrazione fattuale.
- Automazione agentica (ad es. coordinamento di catene di strumenti semplici) — con prove in Antigravity che dimostrano la fattibilità di orchestrazione multi-agente con artefatti che registrano ogni passaggio.
Dove Gemini 3.1 Pro è ancora indietro (cosa dicono i numeri)
Nessun modello è uniformemente il migliore. Commenti indipendenti e test comunitari evidenziano lacune specifiche:
- Benchmark di ingegneria software e manutenzione del codice (SWE-Bench Pro e simili) — Gemini 3.1 Pro dietro a un concorrente (Claude Opus 4.6 di Anthropic) su compiti che testano abilità pratiche di ingegneria software: refactoring su larga scala, triage di bug in codebase disordinati e alcuni tipi di riparazione automatizzata dei programmi. In altre parole, per la manutenzione ingegneristica quotidiana, modelli specializzati mantengono ancora un vantaggio in alcuni testbed.
- Microtask sensibili alla latenza — poiché Gemini 3.1 Pro è calibrato per la profondità, compiti che richiedono latenza ultra-bassa e alto throughput (ad es. micro-inferenza per UI conversazionali leggere) potrebbero essere meglio serviti da varianti “Flash” o altre ottimizzate nella famiglia Gemini.
Qual è il prezzo di Gemini 3.1 Pro?
Puoi accedere a Gemini 3.1 Pro in due modi — abbonamento consumer o API per sviluppatori — e i prezzi sono diversi per ciascuno.
- Consumer (app Gemini / Google AI Pro): L’accesso a Gemini 3.1 Pro è incluso nell’abbonamento Google AI Pro, che negli Stati Uniti è $19.99 / mese (Google offre anche il tier inferiore “AI Plus” e un tier superiore “AI Ultra”). Google.
- Developer / API (basato su token): Se chiami i modelli Gemini tramite la API per sviluppatori Gemini/AI, il prezzo è misurato per token. Per la preview di Gemini 3.x Pro i prezzi pubblicati per sviluppatori sono approssimativamente: $2.00 per 1M token di input e $12.00 per 1M token di output per la fascia standard (≤200k prompt) — con tier più alti (ad es. $4/$18 per 1M) per contesti molto grandi. (Vedi la tabella dei prezzi della Gemini API per dettagli completi e prezzi per batch.)
- Se usi Gemini 3.1 Pro tramite CometAPI:
| Prezzo Comet (USD / M Tokens) | Prezzo ufficiale (USD / M Tokens) |
|---|---|
| Input:$1.6/M; Output:$9.6/M | Input:$2/M; Output:$12/M |
Prezzi degli abbonamenti consumer (app Gemini)
Per i piani destinati agli utenti finali dentro l’app Gemini, Google struttura tier che regolano l’accesso alle varianti di modello e a funzionalità aggiuntive: Google AI Pro e Google AI Ultra. I prezzi variano per mercato e valuta; esempi pubblicati mostrano Google AI Pro a $19.99/mese (con prove promozionali disponibili) e prezzi in valuta differenziati sulla pagina del prodotto (incluse offerte di prova e tariffe ridotte a breve termine). AI Ultra include un accesso più ampio (ad es. accesso prioritario a nuove innovazioni, crediti più alti per la generazione video) a un canone mensile maggiore. Questi piani consumer sono competitivi rispetto ad altri abbonamenti AI di fascia alta e sono pensati per dare a power user individuali o piccoli team accesso alle funzionalità di 3.1 Pro senza integrazione API.
Suggerimenti pratici per prompt e utilizzo (cosa farei)
Usali per ottenere risultati affidabili e ripetibili:
- Pianificazione dei passi esplicita
Pattern di prompt:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Questo sfrutta la più forte esecuzione per passi di 3.1 Pro e ti fornisce checkpoint. - Output strutturato con schemi
Richiedi JSON con uno schema estrict: true. Poiché 3.1 Pro produce output lunghi e aderenti allo schema in modo più affidabile, otterrai risposte singole più grandi che puoi analizzare a valle. - Verifica a sandwich degli strumenti
Quando invochi strumenti esterni (API, esecutori di codice), fai produrre al modello: piano → chiamata esatta dello strumento (copy/paste friendly) → passaggi di validazione. Quindi verifica i passaggi di validazione fuori dal modello prima di continuare. - Attenzione alla fiducia a singolo passo
Anche se il modello scrive codice o comandi dall’aspetto perfetto, esegui una validazione indipendente (test, linter, esecuzione in sandbox) — soprattutto per azioni agentiche/autonome.
Prova pratica con Gemini 3.1 Pro
Caso di prova 1: Assistente di ricerca a contesto lungo (NotebookLM / Deep Research)
Obiettivo: Valutare la capacità del modello di sintetizzare 10–50 documenti lunghi (ad es. report, whitepaper) in un executive summary multi-pagina con citazioni e action item.
Configurazione: Fornire un corpus totale di 200k–800k token; chiedere al modello di produrre un sommario di 2–4 pagine con citazioni esplicite e raccomandazioni “next step”. Usare un template di prompt ripetibile e misurare tempo, uso dei token (costo) e accuratezza fattuale.
Risultati: Sintesi end-to-end più veloce con meno artefatti da chunking rispetto a modelli più vecchi, maggiore fedeltà delle citazioni nel sommario e coerenza migliorata su larga scala — al costo di un uso significativo di token (quindi pianifica il budget). Benchmark e test pratici mostrano che Gemini 3.1 Pro eccelle nella sintesi multi-documento grazie alla finestra da 1M token.
Caso di prova 2: Assistente di coding basato su agenti (Antigravity + GitHub Copilot)
Obiettivo: Misurare la riduzione del tempo di completamento per compiti sviluppatore multi-step (ad es. implementare una feature su diversi file, eseguire test, correggere test falliti).
Configurazione: Usare Antigravity o GitHub Copilot in preview con Gemini 3.1 Pro selezionato. Definire compiti riproducibili (creazione issue → implementazione → esecuzione test), registrare passaggi e artefatti degli agenti e confrontare con un baseline umano-only.
Risultati: Migliore orchestrazione di compiti multi-step (registrazione degli artefatti, suggerimenti automatici di patch candidate), ragionamento multi-file migliorato rispetto a Gemini 3 Pro precedenti e risparmi misurabili di tempo sul lavoro routinario di feature. Compiti specialistici di debug di sistemi a basso livello possono ancora favorire modelli specializzati focalizzati sul codice (risultati della community mostrano un gap rispetto ad alcune varianti GPT-Codex su specifici benchmark di terminale).
Caso di prova 3: Revisione multimodale di documenti legali/medici
Obiettivo: Usare il modello per ingerire un corpus misto (PDF scansionati, immagini, trascrizioni audio), estrarre fatti chiave e produrre una matrice dei rischi e azioni prioritarie.
Configurazione: Fornire un dataset con immagini scansionate e testo OCR, più audio di supporto. Misurare la precisione nell’estrazione di entità nominate, il tasso di falsi positivi e la capacità del modello di fare riferimento ad artefatti sorgente.
Risultati: Ragionamento integrato più forte tra le modalità e output più tracciabili (capacità di indicare l’immagine / pagina / timestamp audio che supporta un’affermazione). La finestra di contesto lunga riduce la necessità di chunking e cross-referencing manuale. Tuttavia, in domini regolamentati, gli output dovrebbero essere validati da esperti di dominio e dovrebbe essere usata una pipeline di grounding/verifica.
Prime impressioni (cosa sembra diverso)
- Ragionamento per passi più profondo. Compiti che in passato richiedevano più scambi — ad es. sintesi multi-documento, matematica/logica multi-step — tendono a completarsi in meno passaggi e con output in stile catena di pensiero più chiari (senza esporre testo di istruzioni interne). Questo è il titolo sottolineato da Google.
- Output strutturati più lunghi e di maggiore qualità. JSON e automazioni long-form sono più coerenti e spesso molto più lunghi (alcuni utenti hanno segnalato dimensioni di output di gran lunga superiori rispetto a 3.0). È ottimo per lavori di generazione in cui si desidera un payload singolo e ampio. Aspettati di gestire output più grandi e streaming.
- Maggiore efficienza di token / gestione del contesto. Miglior efficienza dei token e comportamento più “grounded, coerente con i fatti” negli scenari di uso di strumenti. Si manifesta in meno allucinazioni su lookup fattuali brevi.
Analisi finale: Vale la pena adottare Gemini 3.1 Pro ora?
Gemini 3.1 Pro rappresenta un passo avanti significativo nella famiglia Gemini con miglioramenti dimostrabili su benchmark di ragionamento, coding e agentica — supportati dalla scheda del modello pubblicata da Google e da tracker indipendenti che citano grandi salti in alcune leaderboard selezionate. Per i team che necessitano di ragionamento avanzato, coordinamento di strumenti agentici o capacità multimodali a contesto lungo, 3.1 Pro è un candidato convincente.
Gli sviluppatori possono accedere a Gemini 3.1 Pro tramite CometAPI già ora. Per iniziare, esplora le capacità del modello nel Playground e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore a quello ufficiale per aiutarti a integrare.
Pronto a partire?→ Iscriviti a Gemini 3.1 Pro oggi !
Se vuoi conoscere altri suggerimenti, guide e novità sull’AI seguici su VK, X e Discord!