

GLM-4.6 è l'ultima importante versione della famiglia GLM di Z.ai (precedentemente Zhipu AI): una quarta generazione di linguaggio di grandi dimensioni Modello MoE (Mixture-of-Experts) sintonizzato per flussi di lavoro agentici, ragionamento a lungo contesto e codifica del mondo realeIl comunicato sottolinea l'integrazione pratica tra agente e strumento, un aspetto molto importante finestra contestualee disponibilità open-weight per la distribuzione locale.
Funzionalità principali
- Contesto lungo — nativo Token da 200K finestra di contesto (ampliata da 128K). ()
- Capacità di codifica e agentica — miglioramenti commercializzati nelle attività di codifica del mondo reale e migliore invocazione degli strumenti per gli agenti.
- EFFICIENZA — segnalato Consumo di token inferiore del ~30% vs GLM-4.5 nei test di Z.ai.
- Distribuzione e quantizzazione — prima integrazione FP8 e Int4 annunciata per i chip Cambricon; supporto FP8 nativo su Moore Threads tramite vLLM.
- Dimensioni del modello e tipo di tensore — gli artefatti pubblicati indicano un ~357B-parametro modello (tensori BF16 / F32) su Hugging Face.
Dettagli tecnici
Modalità e formati. GLM-4.6 è un solo testo LLM (modalità di input e output: testo). Lunghezza del contesto = 200K token; output massimo = 128K token.
Quantizzazione e supporto hardware. Il team riferisce Quantizzazione FP8/Int4 su chip Cambricon e FP8 nativo esecuzione su GPU Moore Threads utilizzando vLLM per l'inferenza, importante per ridurre i costi di inferenza e consentire distribuzioni cloud locali e nazionali.
Strumenti e integrazioni. GLM-4.6 viene distribuito tramite l'API di Z.ai, reti di provider terzi (ad esempio, CometAPI) e integrato negli agenti di codifica (Claude Code, Cline, Roo Code, Kilo Code).
Dettagli tecnici
Modalità e formati. GLM-4.6 è un solo testo LLM (modalità di input e output: testo). Lunghezza del contesto = 200K token; output massimo = 128K token.
Quantizzazione e supporto hardware. Il team riferisce Quantizzazione FP8/Int4 su chip Cambricon e FP8 nativo esecuzione su GPU Moore Threads utilizzando vLLM per l'inferenza, importante per ridurre i costi di inferenza e consentire distribuzioni cloud locali e nazionali.
Strumenti e integrazioni. GLM-4.6 viene distribuito tramite l'API di Z.ai, reti di provider terzi (ad esempio, CometAPI) e integrato negli agenti di codifica (Claude Code, Cline, Roo Code, Kilo Code).
Prestazioni di riferimento
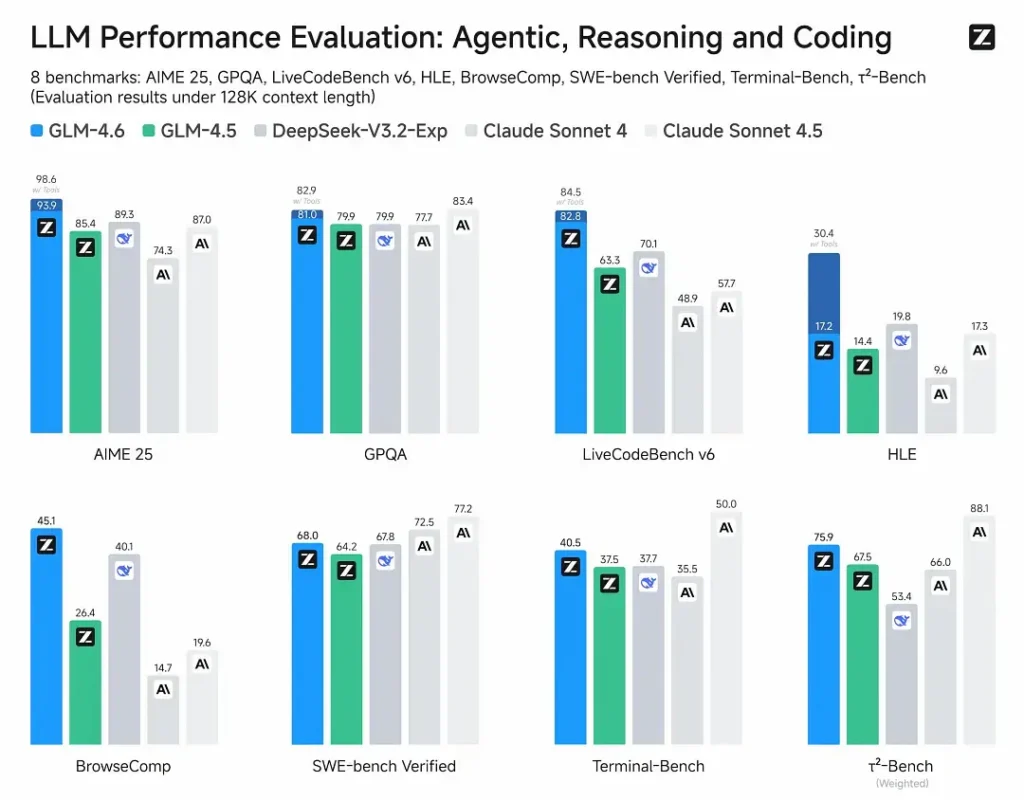
- Valutazioni pubblicate: GLM-4.6 è stato testato su otto benchmark pubblici che coprono agenti, ragionamento e codifica e mostra netti guadagni rispetto a GLM-4.5Nei test di codifica reali valutati dall'uomo (CC-Bench esteso), GLM-4.6 utilizza ~15% di token in meno vs GLM-4.5 e pubblica un Percentuale di vincita ~48.6% contro Anthropic Sonetto 4 di Claude (quasi parità in molte classifiche).
- Posizionamento: i risultati affermano che GLM-4.6 è competitivo con i principali modelli nazionali e internazionali (gli esempi citati includono DeepSeek-V3.1 e Claude Sonnet 4).
Limitazioni e rischi
- Allucinazioni ed errori: Come tutti gli LLM attuali, anche GLM-4.6 può commettere errori di fatto: la documentazione di Z.ai avverte esplicitamente che gli output potrebbero contenere errori. Gli utenti dovrebbero applicare la verifica e il recupero/RAG per i contenuti critici.
- Complessità del modello e costo del servizio: Un contesto da 200K e output molto grandi aumentano notevolmente le richieste di memoria e latenza e possono aumentare i costi di inferenza; per funzionare su larga scala è necessaria un'ingegneria quantizzata/inferenza.
- Lacune di dominio: mentre GLM-4.6 riporta forti prestazioni di agente/codifica, alcuni rapporti pubblici notano che è ancora ritardi in alcune versioni di modelli concorrenti in microbenchmark specifici (ad esempio, alcune metriche di codifica rispetto a Sonnet 4.5). Valutare per attività prima di sostituire i modelli di produzione.
- Sicurezza e politica: i pesi aperti aumentano l'accessibilità ma sollevano anche questioni di gestione (mitigazioni, guardrail e red-teaming restano responsabilità dell'utente).
Utilizzo Tipico
- Sistemi agenti e orchestrazione degli strumenti: lunghe tracce di agenti, pianificazione multi-strumento, invocazione dinamica di strumenti; la messa a punto agentica del modello è un punto di forza fondamentale.
- Assistenti di programmazione nel mondo reale: generazione di codice multi-turn, revisione del codice e assistenti IDE interattivi (integrati in Claude Code, Cline, Roo Code—per Z.ai). Miglioramenti dell'efficienza dei token renderlo attraente per i piani di sviluppo ad uso intensivo.
- Flussi di lavoro di documenti lunghi: riassunti, sintesi multi-documento, lunghe revisioni legali/tecniche dovute alla finestra da 200K.
- Creazione di contenuti e personaggi virtuali: dialoghi estesi, mantenimento coerente della personalità in scenari multi-turn.
Confronto tra GLM-4.6 e altri modelli
- GLM-4.5 → GLM-4.6: cambiamento di passo in dimensione del contesto (128K → 200K) e al efficienza dei token (~15% di token in meno su CC-Bench); utilizzo migliorato dell'agente/strumento.
- GLM-4.6 contro Claude Sonetto 4 / Sonetto 4.5: Rapporti di Z.ai quasi parità in diverse classifiche e un tasso di successo di circa il 48.6% nei compiti di codifica reali di CC-Bench (ovvero, una concorrenza serrata, con alcuni microbenchmark in cui Sonnet è ancora in testa). Per molti team di ingegneria, GLM-4.6 è considerato un'alternativa conveniente.
- GLM-4.6 rispetto ad altri modelli a contesto lungo (DeepSeek, varianti Gemini, famiglia GPT-4): GLM-4.6 enfatizza i flussi di lavoro di codifica ampi e di tipo agentico; i punti di forza relativi dipendono dalla metrica (efficienza del token/integrazione dell'agente rispetto all'accuratezza della sintesi del codice grezzo o alle pipeline di sicurezza). La selezione empirica dovrebbe essere guidata dalle attività.
Rilasciato l'ultimo modello di punta di Zhipu AI, il GLM-4.6: 355 miliardi di parametri totali, 32 miliardi attivi. Supera il GLM-4.5 in tutte le funzionalità principali.
- Codifica: si allinea con Sonetto 4 di Claude, il migliore in Cina.
- Contesto: esteso a 200K (da 128K).
- Ragionamento: migliorato, supporta la chiamata dello strumento durante l'inferenza.
- Ricerca: Miglioramento delle prestazioni degli agenti e delle chiamate degli strumenti.
- Scrittura: si allinea meglio alle preferenze umane in termini di stile, leggibilità e gioco di ruolo.
- Multilingue: traduzione interlingue potenziata.
Come chiamare GLM-**4.**6 API di CometAPI
GLM‑4.6 Prezzi API in CometAPI: sconto del 20% sul prezzo ufficiale:
- Token di input: $ 0.64 milioni di token
- Token di output: $2.56/M di token
Passi richiesti
- Accedere cometapi.comSe non sei ancora un nostro utente, ti preghiamo di registrarti prima.
- Accedi al tuo Console CometAPI.
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.

Usa il metodo
- Selezionare l'opzione "
glm-4.6"endpoint" per inviare la richiesta API e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per vostra comodità. - Sostituire con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo contenuto: il modello risponderà a questa domanda.
- Elaborare la risposta API per ottenere la risposta generata.
CometAPI fornisce un'API REST completamente compatibile, per una migrazione senza interruzioni. Dettagli chiave per Documento API:
- URL di base: https://api.cometapi.com/v1/chat/completions
- Nomi dei modelli: "
glm-4.6" - Autenticazione:
Bearer YOUR_CometAPI_API_KEYtestata - Tipo di contenuto:
application/json.
Integrazione API ed esempi
Di seguito è riportato un Python frammento che dimostra come richiamare GLM‑4.6 tramite l'API di CometAPI. Sostituisci <API_KEY> e al <PROMPT> di conseguenza:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Parametri chiave:
- modello: Specifica la variante GLM‑4.6
- max_token: Controlla la lunghezza dell'output
- temperatura: Regola la creatività rispetto al determinismo
Vedi anche Sonetto 4.5 di Claude