

Google DeepMind ha annunciato oggi significative espansioni della sua famiglia Gemini 2.5, svelando le versioni stabili di Gemini 2.5 Pro e Gemini 2.5 Flash, insieme a un'anteprima del nuovissimo modello Gemini 2.5 Flash-Lite. Questi aggiornamenti riflettono il continuo impegno di Google nell'offrire una gamma di modelli di intelligenza artificiale che bilanciano costi, velocità e prestazioni per carichi di lavoro diversificati.
Versioni stabili: Gemini 2.5 Pro e Flash
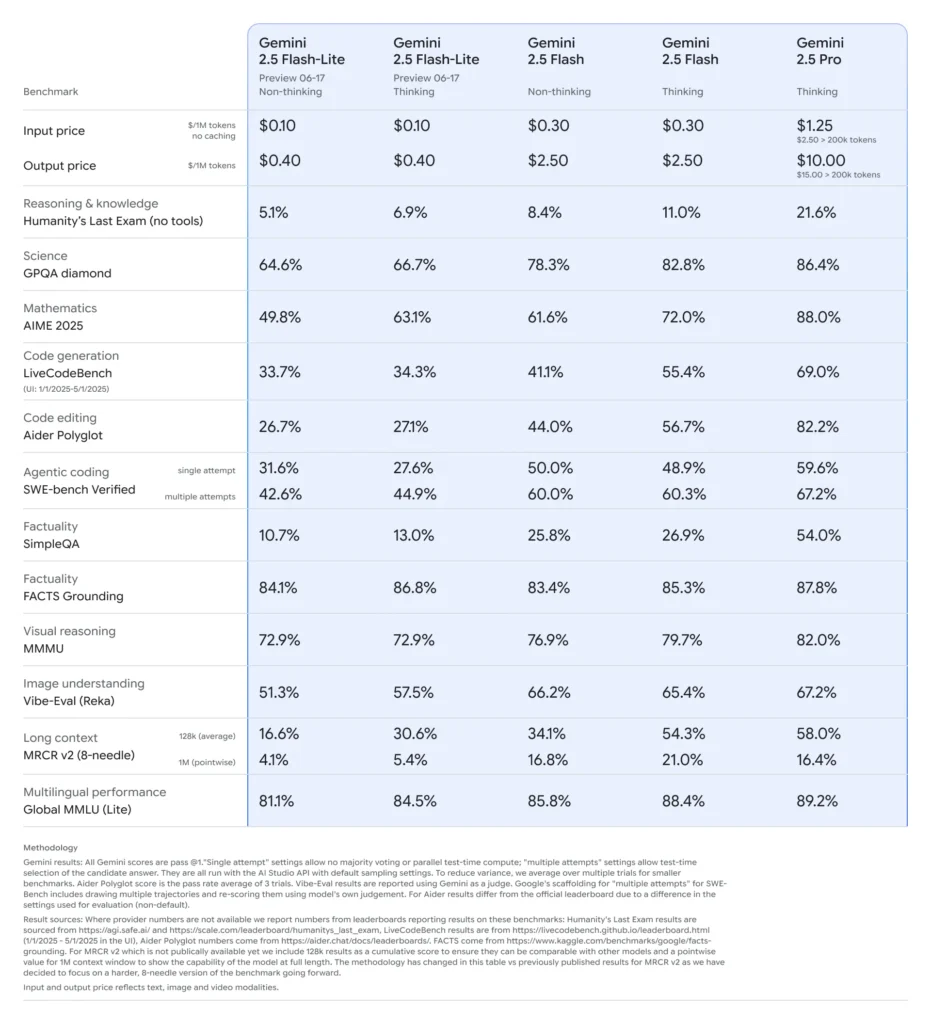
Il 17 giugno 2025, Google ha annunciato la disponibilità generale di Gemini 2.5 Pro e Gemini 2.5 Flash. La versione Pro offre la massima potenza di ragionamento ed è pensata per attività ad alta complessità come la generazione di codice avanzata, l'analisi scientifica e la sintesi di dati su larga scala. Al contrario, Gemini 2.5 Flash offre un'opzione di livello intermedio ottimizzata per gli usi quotidiani che richiedono bassa latenza, ideale per chatbot, riepiloghi e creazione di contenuti su larga scala.
Panoramica: tre modelli della famiglia Gemini -2.5
| Modello | Stato | Punti di forza | Casi d'uso ideali |
|---|---|---|---|
| Gemini 2.5 Flash-Lite (anteprima) | Anteprima | Il più veloce e il più economico; multimodale; ragionamento controllabile; abilitato dagli strumenti | Attività ad alto volume come chatbot, riepilogo, ricerca |
| Gemini 2.5 Flash | Stabile | Bilanciato: bassa latenza, buon ragionamento, multimodale | Conversazioni in tempo reale, assistenza clienti |
| Gemini 2.5 Pro | Stabile | Più capace: ragionamento profondo, contesto ampio, multimodale | Ricerca, codifica complessa, compiti scientifici |
Gemini 2.5 Flash‑Lite: Caratteristiche principali dell'anteprima
Latenza ultra-bassa e risparmio sui costiProgettato per applicazioni ad alto volume e in tempo reale come traduzione, classificazione e riepilogo. Offre inferenza più rapida e costi per chiamata inferiori rispetto sia alla versione Flash-Lite 2.0 che alla versione Flash completa.
Prestazioni fondamentali migliorate: Supera i precedenti modelli Flash-Lite nei benchmark di generazione di codice, logica, matematica, ragionamento multimodale e scienza.
Costo ed efficienza: Prezzi di Flash-Lite (anteprima): ~$0.10 per 1 milione di token di input e ~$0.40 per 1 milione di token di output, notevolmente più economici di Flash ($0.30/$2.50) e Pro ($1.25/$10).
Funzionalità complete di Gemini -2.5:
- Pensiero controllabile:Gli utenti possono impostare "budget di riflessione" (limiti dei token) per barattare la velocità con la profondità: Flash-Lite può attivare questa funzione in base alle esigenze.
- Ingresso multimodale: Supporta testo, immagini, audio e video (incluse clip della durata di un'ora), con capacità di analizzare grafici, interfacce utente, scene e riepiloghi di eventi.
- Integrazione degli strumenti: Include la ricerca Google, l'esecuzione di codice e una finestra di contesto da un milione di token, che corrisponde alle capacità di Flash e Pro.
Posizionamento sulla curva prezzo-prestazioni
Google posiziona l'alta velocità e il basso costo di Flash-Lite al primo posto Frontiera di Pareto, il che significa che è tra i modelli più convenienti e al contempo più capaci al mondo (). Nelle valutazioni comparative, Flash‑Lite rappresenta il miglior rapporto qualità-prezzo: intelligente ma conveniente.
Informazioni su Flash e Pro
- Gemini 2.5 Flash: Modello di pensiero multimodale stabile e a bassa latenza. Posizionato al di sotto di Pro, ma pressoché alla pari con GPT-4 in termini di capacità, con velocità ed efficienza dei costi superiori ().
- Gemini 2.5 Pro: Il modello più avanzato di Google. Rinomato per la gestione di video/audio di lunga durata, codice e calcoli complessi e ragionamenti ad ampio contesto. Introduce inoltre "budget di pensiero" selettivi e una migliore qualità del codice per fungere da IA di punta stabile a lungo termine.
Distribuzione e prezzi
- Disponibilità: Tutti e tre i modelli sono accessibili tramite Studio sull'intelligenza artificiale di Google, IA di Google Cloud Vertex App Gemelli .
- Struttura dei costi (Prezzi di Vertex AI dal 16 giugno 2025):
- Pro: $1.25/1M input, $10/1M output (più alto oltre i 200K token)
- Cromatografia: $0.15/1M input, $3.50/1M output in modalità "pensiero" e include 1,500 prompt gratuiti basati sui dati al giorno ()
- Flash-Lite (anteprima): ~$0.10/$0.40 per 1 milione di token
Iniziamo
CometAPI fornisce un'interfaccia REST unificata che aggrega centinaia di modelli di intelligenza artificiale, sotto un endpoint coerente, con gestione integrata delle chiavi API, quote di utilizzo e dashboard di fatturazione. Invece di dover gestire URL e credenziali di più fornitori.
Gli sviluppatori possono accedere API Gemini 2.5 Flash-Lite (anteprima) attraverso CometaAPI, gli ultimi modelli elencati sono quelli aggiornati alla data di pubblicazione dell'articolo. Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.