

Il 3 marzo 2026, Google ha introdotto Gemini 3.1 Flash-Lite, il più recente membro della famiglia Gemini 3 progettato specificamente come motore ad alto throughput, bassa latenza e conveniente in termini di costi per carichi di lavoro di sviluppatori e aziende. Google posiziona Flash-Lite come il modello “più veloce e più conveniente” della linea Gemini 3: una variante leggera che punta a fornire interazioni in streaming, elaborazione in background su larga scala e attività di produzione ad alta frequenza (ad esempio, traduzione, estrazione, generazione di UI e classificazione ad alto volume) a un prezzo molto più basso rispetto alle controparti Pro.
Di seguito analizziamo cos’è Flash-Lite.
Che cos’è Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite è un membro della famiglia Gemini 3 che scambia intenzionalmente parte della massima profondità di ragionamento per velocità ed efficienza dei costi. È nativamente multimodale nella linea Gemini (in grado di accettare testo, immagini e altre modalità come input), ma è messo a punto e distribuito specificamente per offrire il massimo throughput di token al secondo e una fatturazione per token sostanzialmente inferiore per carichi di lavoro che richiedono inferenza rapida e ripetuta piuttosto che la massima profondità cognitiva. Il modello è descritto come derivato dall’architettura 3.1 Pro ma ottimizzato per throughput, latenza e costo.
Principali compromessi progettuali
Il suffisso "Lite" segnala l’enfasi ingegneristica del modello:
- Throughput rispetto al ragionamento “pesante”: Flash-Lite riduce intenzionalmente il compute per token per offrire un Time-to-First-Token (TTFT) più rapido e una velocità di output continua. Ciò lo rende ideale per pipeline in cui ogni richiesta deve essere servita rapidamente e su larga scala (ad es., filtri di sicurezza, assistenti in tempo reale, generazione ad alto volume).
- Efficienza dei costi per alti volumi: Riducendo il compute per token, il modello può essere offerto a prezzi più bassi per milione di token, il che riduce il costo marginale nelle applicazioni su larga scala (ad es., da milioni a miliardi di token al mese). Il pricing in anteprima di Google mostra un delta significativo rispetto al livello Pro.
- Qualità calibrata per compiti pragmatici: Secondo i primi riepiloghi di punteggio, Flash-Lite mantiene risultati solidi su classificazione standard, multilingua e molte attività multimodali, ma non è posizionato per superare Pro sui benchmark più complessi di ragionamento multi-step o generazione di codice dove la profondità conta.
Questi carichi di lavoro richiedono output affidabili e alto throughput, ma non sempre richiedono le capacità di ragionamento multi-step complesse dei modelli di punta.
Caratteristiche principali di Gemini 3.1 Flash-Lite
1. Bassa latenza e tempo al primo token rapido
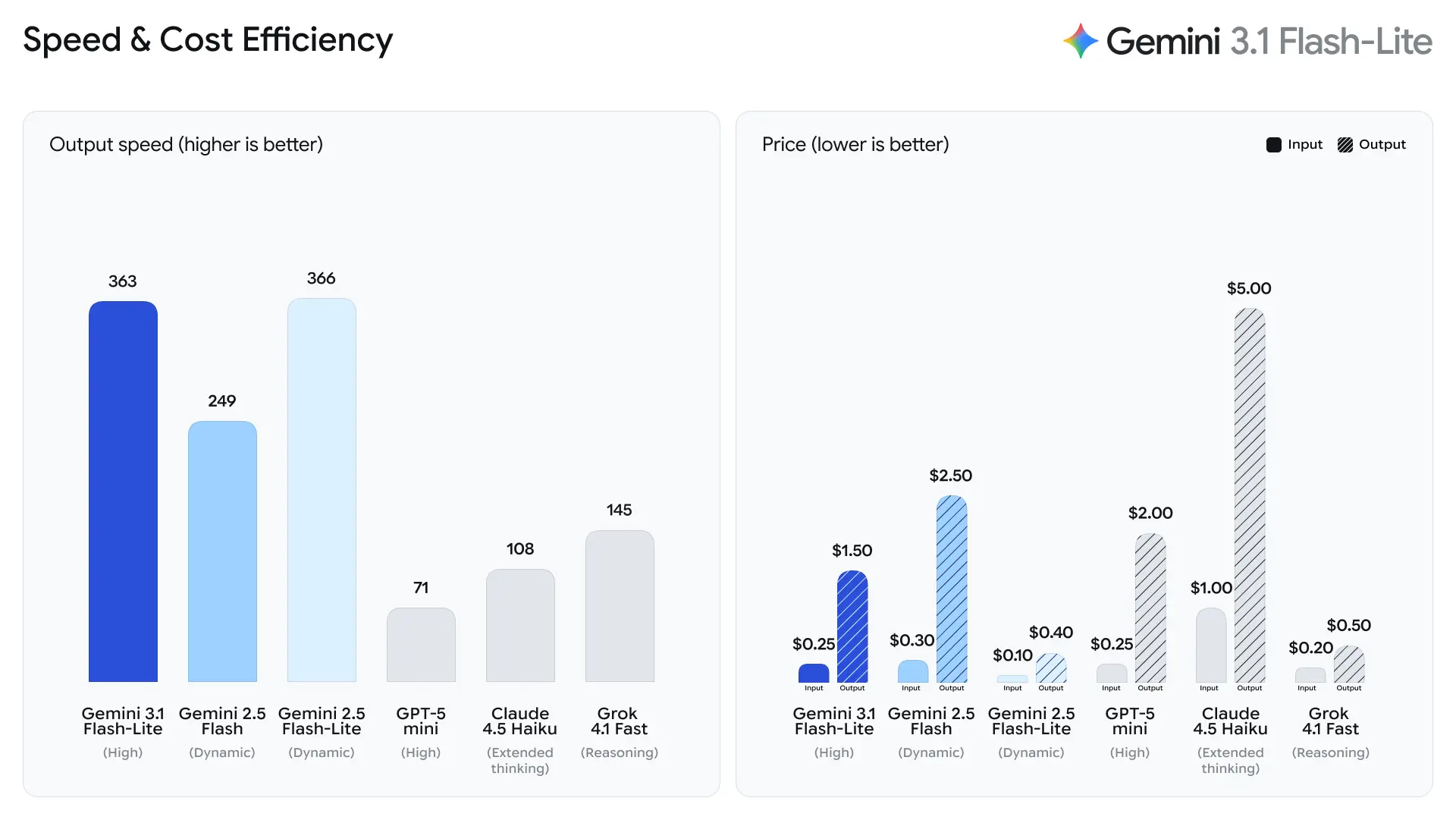
Google sottolinea il tempo al primo token di risposta come metrica primaria per Flash-Lite. L’azienda riporta un ~2,5× tempo al primo token più veloce rispetto a Gemini 2.5 Flash e fino al 45% più veloce nella generazione dell’output — miglioramenti che incidono direttamente sulla reattività percepita dagli utenti finali e sui costi di throughput per i sistemi back-end. Questi vantaggi rendono Flash-Lite adatto a funzionalità interattive (ad es., chatbot incorporati nelle app) e pipeline ad alto QPS dove i microsecondi contano.
Questo miglioramento potenzia in modo significativo le applicazioni in tempo reale quali:
- IA conversazionale
- assistenti di ricerca alimentati da IA
- chatbot interattivi
- servizi di traduzione in tempo reale
La minore latenza migliora l’esperienza utente riducendo i tempi di attesa e consentendo interazioni più fluide.
2. Prezzi dei token convenienti
I costi di inferenza dell’IA sono spesso calcolati per token, rendendo il prezzo un fattore critico per le implementazioni su larga scala.
Gemini 3.1 Flash-Lite introduce una struttura di prezzi altamente competitiva:
| Tipo di token | Prezzo |
|---|---|
| Token di input | $0.25 per 1M di token |
| Token di output | $1.50 per 1M di token |
Questo rappresenta una riduzione rispetto ai precedenti modelli Flash, rendendo il modello interessante per le organizzazioni che eseguono carichi di lavoro grandi.
A titolo di confronto:
| Modello | Prezzo input | Prezzo output |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Questa strategia di pricing consente agli sviluppatori di eseguire l’IA su larga scala senza aumentare drasticamente i costi operativi.
Se cerchi un prezzo ancora migliore, allora Gemini Flash-Lite offre uno sconto del 20% su CometAPI.
3. “Thinking levels” (profondità di inferenza controllabile)
Gemini 3.1 Flash-Lite include la funzionalità “thinking levels” — un parametro configurabile dagli sviluppatori che istruisce il modello a preferire un’elaborazione più veloce e superficiale per i compiti banali e un ragionamento più profondo per quelli più complessi. Questo è importante nella pratica perché consente compromessi dinamici tra costo e latenza per richiesta senza cambiare modello.
Gli sviluppatori possono configurare la profondità di ragionamento del modello per adattarla alla complessità dell’attività. Thinking levels: supporta quattro livelli: Minimo, Basso, Medio e Alto.
Questo approccio dinamico consente alle applicazioni di ottimizzare l’uso delle risorse mantenendo la qualità dove serve. La strategia pratica è grosso modo la seguente:
- Minimo/Basso: adatto a compiti ad alta concorrenza ma logicamente semplici come traduzione, classificazione e analisi del sentiment, privilegiando la massima velocità e il costo minimo.
- Medio: adatto alla maggior parte dei compiti in produzione, bilanciando qualità ed efficienza.
- Alto: adatto a compiti che richiedono ragionamento profondo, come generazione di interfacce utente, creazione di simulazioni ed esecuzione di istruzioni complesse.
4. Capacità multimodale con impronta leggera
Sebbene Flash-Lite sia ottimizzato per velocità e costo, mantiene le fondamenta multimodali della linea Gemini 3: può accettare input di immagini per classificazione o leggero ragionamento multimodale quando il caso d’uso lo richiede — ma gli sviluppatori dovrebbero aspettarsi che il design economico favorisca operazioni multimodali più brevi e limitate rispetto a workflow molto ampi e ricchi di immagini. Come altri modelli Gemini, Gemini 3.1 Flash-Lite supporta input multimodali, consentendo agli sviluppatori di elaborare diversi tipi di dati.
Gli input supportati includono:
- Testo
- Immagini
- Video
- Audio
La capacità del modello di analizzare più tipi di informazioni abilita nuovi casi d’uso, come:
- elaborazione automatizzata di documenti
- estrazione di dati visivi
- sintesi multimediale
I modelli Gemini precedenti hanno inoltre dimostrato forti capacità di ragionamento multimodale su benchmark visivi e di conoscenza.
Benchmark delle prestazioni — numeri reali e cosa significano
L’annuncio e la documentazione di prodotto di Google presentano diversi punti di benchmark volti ad aiutare i clienti a capire dove si colloca Flash-Lite nell’ecosistema.
Metriche di velocità orientate agli sviluppatori
- 2,5× più veloce nel Time to First Answer Token rispetto a Gemini 2.5 Flash (confronto interno dichiarato da Google).
- 45% più veloce nella generazione dell’output rispetto a Gemini 2.5 Flash.
Si tratta di metriche di ingegneria delle prestazioni piuttosto che di metriche di qualità giudicate da esseri umani; riflettono miglioramenti nella microarchitettura runtime, nel batching e nelle ottimizzazioni dello stack di inferenza che riducono la latenza per risposte brevi. Tempi più rapidi al primo token riducono il ritardo percepito nelle applicazioni interattive e aumentano il throughput per server, il che può ridurre i costi di calcolo totali per lo stesso QPS.
Token al secondo (t/s) e throughput
Secondo i dati di test di Artificial Analysis, 3.1 Flash-Lite ha raggiunto una velocità di output di 388.8 token al secondo (la mediana per i modelli nella stessa fascia di prezzo è solo 96.7 token/secondo). Questa velocità è di livello massimo tra i modelli della sua classe.
Tuttavia, Artificial Analysis ha anche evidenziato un problema: la latenza del primo token (TTFT) di 3.1 Flash-Lite è di 5.18 secondi, relativamente alta per i modelli di inferenza nella stessa fascia di prezzo (la mediana è 1.82 secondi). Inoltre, il modello ha generato 53 milioni di token durante il processo di valutazione, un valore relativamente alto rispetto alla media di 20 milioni. Ciò significa che, se il tuo scenario è molto sensibile alla latenza del primo token o ha requisiti rigorosi per la concisione dell’output, potrebbe essere necessario ottimizzare il livello di ragionamento e i prompt.
Punteggi di benchmark per ragionamento e factualità
Google ha incluso confronti cross-modello che mostrano Gemini 3.1 Flash-Lite con prestazioni solide rispetto ai pari e alle precedenti varianti Gemini su attività aggregate di ragionamento/fattualità:
- Arena.ai Elo score: Gemini 3.1 Flash-Lite ha raggiunto un Elo di 1432 nella leaderboard di valutazione di Arena — una classifica composita testa a testa che mostra prestazioni relative competitive negli scenari di confronto diretto.
- GPQA Diamond: 86.9% (una misura della robustezza nel question answering).
- MMMU Pro: 76.8% (una metrica multimodale/multi-task usata internamente/esternamente da alcuni laboratori).
- LiveCodeBench (Capacità di coding): 72.0%
- CharXiv Reasoning (Ragionamento grafico): 73.2%
- Video-MMMU (Comprensione video): 84.8%
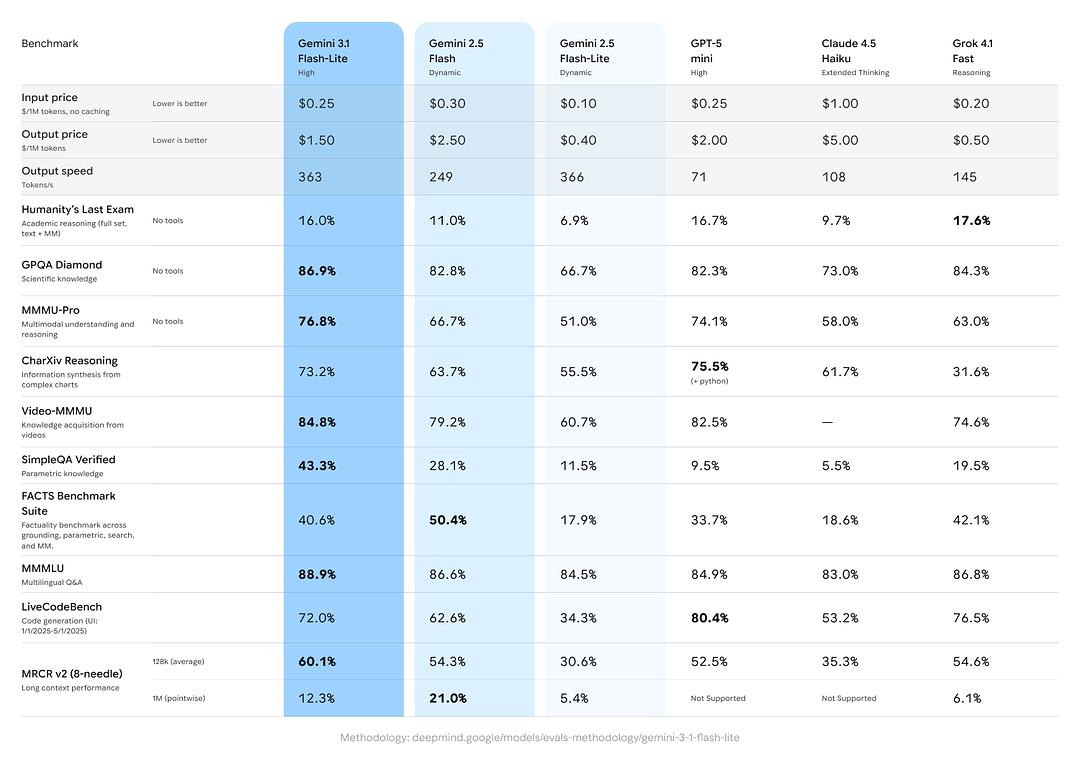
Gemini 3.1 Flash-Lite supera il vecchio Gemini 2.5 Flash in diversi di questi metriche offrendo al contempo velocità/costo nettamente migliori.
Casi d’uso adatti a Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite è progettato attorno a un set chiaro di carichi di lavoro pratici in cui alto throughput e costo per token inferiore sono decisivi:
Agenti conversazionali ad alta frequenza e UI in streaming
Chatbot in tempo reale, stream di trascrizione + traduzione live e interfacce collaborative che mostrano risposte parziali mentre il modello genera beneficiano dell’output di token in streaming e del basso tempo al primo token di Flash-Lite.
Elaborazione dati massiva (RAG, pipeline di trasformazione)
Ingestione massiva di documenti: estrazione di entità, tagging dei metadati, classificazione e traduzione eseguite su milioni di documenti — Gemini 3.1 Flash-Lite riduce il costo di inferenza fornendo al contempo un’accuratezza accettabile per output basati su template o regole.
Elaborazione in stile edge o in background
Carichi di lavoro che elaborano continuamente telemetria in entrata o dati non strutturati (ad es., pipeline di classificazione per la moderazione dei contenuti, generazione automatica di report) sono adatti perché Gemini 3.1 Flash-Lite minimizza il costo per unità.
Strumenti per sviluppatori e completamento di codice in batch
Per funzionalità come scaffolding multi-file, linting del codice su larga scala e generazione di template su larga scala, i vantaggi di velocità di Gemini 3.1 Flash-Lite riducono latenza e costo per strumenti di developer experience laddove non è richiesta la massima profondità di ragionamento assoluta.
Confronto tra Gemini 3.1 Flash-Lite e altri modelli Gemini e concorrenti
All’interno della famiglia Gemini
- Gemini 3.1 Pro: massima capacità su ragionamento complesso e pianificazione multi-step; significativamente più costoso e lento per token ma migliore per compiti profondi e sfumati.
- Gemini 3.1 Flash (non-Lite): si colloca a metà strada tra throughput puro e capacità — Flash-Lite ottimizza ulteriormente lo stack di calcolo per il throughput.
Rispetto ai modelli “rapidi” concorrenti
Gemini 3.1 Flash-Lite eguaglia o supera diversi modelli fast/mini su molte metriche di throughput e qualità — tuttavia analisti indipendenti avvertono che confronti diretti sono sensibili alla metodologia di valutazione e alla selezione dei dataset. Aspettati che Gemini 3.1 Flash-Lite sia altamente competitivo in throughput e costo, rimanendo vicino a metà classifica nelle metriche di ragionamento più elevate.
Conclusioni — dove si colloca Flash-Lite nello stack di IA
Gemini 3.1 Flash-Lite è un’offerta progettata con intenzionalità: un membro efficiente e orientato al throughput della famiglia Gemini 3 che consente ai team di scambiare parte del compute per esempio con miglioramenti notevoli in latenza e costo. Per aziende e sviluppatori che costruiscono pipeline ad alto volume — traduzioni, elaborazione in batch, UI in streaming e attività agentiche a complessità moderata — Flash-Lite rappresenta un motore di base sensato. Per le organizzazioni che richiedono la massima fedeltà di ragionamento, i modelli Pro restano la scelta appropriata.
Se il tuo carico di lavoro è dominato da molte inferenze brevi e ripetibili o necessiti di output in streaming rapido su larga scala, vale la pena provare Flash-Lite. Se il tuo carico di lavoro dipende da ragionamento profondo multi-hop, pianifica un approccio ibrido: instrada il traffico di throughput su Flash-Lite ed eleva le query complesse e di alto valore ai modelli Pro.
Gli sviluppatori possono accedere a Gemini 3.1 Flash Lite tramite CometAPI già da ora. Per iniziare, esplora le capacità del modello nel Playground e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore a quello ufficiale per aiutarti a integrare.
Pronto a iniziare?→ Iscriviti a Gemini 3.1 Flash-Lite oggi !
Se vuoi conoscere altri consigli, guide e novità sull’IA seguici su VK, X e Discord!