

al 15 dicembre 2025 i fatti pubblici mostrano che Gemini 3 Pro (anteprima) di Google e GPT-5.2 di OpenAI hanno entrambi fissato nuove frontiere nel ragionamento, nella multimodalità e nel lavoro su contesti lunghi — ma seguono strade ingegneristiche diverse (Gemini → MoE sparso + contesto enorme; GPT-5.2 → design densi/di “routing”, compattazione e modalità di ragionamento x-high) e quindi scambiano vittorie di picco nei benchmark vs. prevedibilità ingegneristica, tooling ed ecosistema. Quale sia “migliore” dipende dall’esigenza primaria: applicazioni agentiche multimodali a contesto estremo tendono verso Gemini 3 Pro; strumentazione stabile per sviluppatori enterprise, costi prevedibili e disponibilità API immediata favoriscono GPT-5.2.
Che cos’è GPT-5.2 e quali sono le sue caratteristiche principali?
GPT-5.2 è la release dell’11 dicembre 2025 di OpenAI nella famiglia GPT-5 (varianti: Instant, Thinking, Pro). È posizionato come il modello più capace dell’azienda per il “lavoro professionale della conoscenza” — ottimizzato per fogli di calcolo, presentazioni, ragionamento su contesti lunghi, tool calling, generazione di codice e attività di visione. OpenAI ha reso GPT-5.2 disponibile agli utenti ChatGPT a pagamento e via OpenAI API (Responses API / Chat Completions) con nomi modello come gpt-5.2, gpt-5.2-chat-latest e gpt-5.2-pro.
Varianti del modello e uso previsto
- gpt-5.2 / GPT-5.2 (Thinking) — il migliore per ragionamento complesso e multi-step (la variante “Thinking” predefinita usata nella Responses API).
- gpt-5.2-chat-latest / Instant — assistente e chat quotidiani a bassa latenza.
- gpt-5.2-pro / Pro — massima fedeltà/affidabilità per i problemi più difficili (compute extra, supporta
reasoning_effort: "xhigh").
Caratteristiche tecniche principali (lato utente)
- Miglioramenti Vision & multimodali — migliore ragionamento spaziale sulle immagini e comprensione video migliorata quando abbinata a tool di codice (strumento Python), oltre al supporto per strumenti in stile code-interpreter per eseguire snippet.
- Sforzo di ragionamento configurabile (
reasoning_effort: none|minimal|low|medium|high|xhigh) per scambiare latenza/costo vs profondità.xhighè nuovo in GPT-5.2 (e supportato su Pro). - Gestione del contesto lungo migliorata e funzioni di compattazione per ragionare su centinaia di migliaia di token (OpenAI riporta forti metriche MRCRv2 / long-context).
- Tool calling avanzato e workflow agentici — coordinamento multi-turn più robusto, migliore orchestrazione degli strumenti in un’architettura da “mega-agente” unico (OpenAI evidenzia le prestazioni sugli strumenti Tau2-bench).
Che cos’è Gemini 3 Pro Preview?
Gemini 3 Pro Preview è il modello di IA generativa più avanzato di Google, rilasciato come parte della famiglia Gemini 3 nel novembre 2025. Il modello è costruito con un’enfasi sulla comprensione multimodale—capace di comprendere e sintetizzare testo, immagini, video e audio—e dispone di una grande finestra di contesto (~1 milione di token) per gestire documenti o codebase estese.
Google posiziona Gemini 3 Pro come lo stato dell’arte in termini di profondità e finezza del ragionamento, e funge da motore principale per molteplici strumenti per sviluppatori ed enterprise, inclusi Google AI Studio, Vertex AI e piattaforme di sviluppo agentiche come Google Antigravity.
Ad oggi, Gemini 3 Pro è in anteprima—il che significa che funzionalità e accesso sono ancora in espansione, ma il modello già ottiene alti punteggi in logica, comprensione multimodale e workflow agentici.
Caratteristiche tecniche e di prodotto principali
- Finestra di contesto: Gemini 3 Pro Preview supporta un input di 1,000,000 token (e fino a 64k token in output), un vantaggio pratico rilevante per acquisire documenti estremamente grandi, libri o trascrizioni video in una singola richiesta.
- Funzionalità API: parametro
thinking_level(low/high) per scambiare latenza e profondità di ragionamento; impostazionimedia_resolutionper controllare la fedeltà multimodale e l’uso di token; sono supportati grounding di ricerca, contesto file/URL, esecuzione di codice e function calling. Le thought signatures e il caching del contesto aiutano a mantenere lo stato attraverso workflow multi-call. - Modalità Deep Think / ragionamento più elevato: un’opzione “Deep Think” fornisce una passata di ragionamento extra per spingere i punteggi nei benchmark difficili. Google pubblica Deep Think come un percorso ad alte prestazioni separato per problemi complessi.;
- Supporto nativo multimodale: input di testo, immagini, audio e video con solidi agganci a search e integrazioni di prodotto (vengono evidenziati i punteggi a Video-MMMU e altri benchmark multimodali).
Anteprima rapida — GPT-5.2 vs Gemini 3 Pro
Tabella comparativa compatta con i fatti più importanti (con fonti citate).
| Aspetto | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Fornitore / posizionamento | OpenAI — upgrade di punta GPT-5.x focalizzato su lavoro professionale della conoscenza, coding e workflow agentici. | Google DeepMind / Google AI — generazione Gemini di punta focalizzata su ragionamento multimodale a contesto ultralungo e integrazione strumenti. |
| Principali varianti del modello | Instant, Thinking, Pro (e Auto che commuta tra esse). Pro aggiunge maggiore sforzo di ragionamento. | Famiglia Gemini 3 che include Gemini 3 Pro e modalità Deep-Think; focus multimodale/agentico. |
| Finestra di contesto (input / output) | ~400,000 token di capacità totale in input; fino a 128,000 token di output/ragionamento (progettato per documenti e codebase molto lunghi). | Fino a ~1,000,000 token in input/finestra di contesto (1M) con output fino a 64K token |
| Punti di forza / focus | Ragionamento su contesto lungo, tool-calling agentico, coding, attività strutturate d’ufficio (fogli, presentazioni); aggiornamenti di safety/system-card enfatizzano l’affidabilità. | Comprensione multimodale su larga scala, ragionamento + composizione immagini, contesto molto ampio + modalità di ragionamento “Deep Think”, forti integrazioni di strumenti/agent nell’ecosistema Google. |
| Capacità multimodali & immagine | Visione e grounding multimodale migliorati; ottimizzato per l’uso di strumenti e l’analisi documentale. | Generazione d’immagini ad alta fedeltà + composizione potenziata dal ragionamento, editing con immagini multi-referenza e resa di testo leggibile. |
| Latenza / interattività | Il fornitore enfatizza inferenza più rapida e reattività del prompt (latenza inferiore rispetto ai precedenti GPT-5.x); più livelli (Instant / Thinking / Pro). | Google enfatizza “Flash”/serving ottimizzato e velocità interattive comparabili in molti flussi; la modalità Deep Think scambia latenza per ragionamento più profondo. |
| Caratteristiche / differenziatori | Livelli di sforzo di ragionamento (medium/high/xhigh), tool-calling migliorato, generazione di codice di alta qualità, alta efficienza di token per workflow enterprise. | Contesto da 1M token, ingest multimodale nativa (video/audio) robusta, modalità di ragionamento “Deep Think”, integrazioni strette con prodotti Google (Docs/Drive/NotebookLM). |
| Usi tipici (sintesi) | Analisi di documenti lunghi, workflow agentici, progetti di coding complessi, automazione enterprise (fogli/report). | Progetti multimodali estremamente ampi, workflow agentici di lungo orizzonte che necessitano di contesto da 1M token, pipeline avanzate immagine + ragionamento. |
Come si confrontano GPT-5.2 e Gemini 3 Pro dal punto di vista architetturale?
Architettura di base
- Benchmark / valutazioni sul lavoro reale: GPT-5.2 Thinking ha ottenuto 70,9% di vittorie/pareggi su GDPval (valutazione sul lavoro della conoscenza in 44 occupazioni) e grandi incrementi su benchmark di ingegneria e matematica rispetto alle precedenti varianti GPT-5. Miglioramenti significativi nel coding (SWE-Bench Pro) e nella QA scientifica di dominio (GPQA Diamond).
- Tooling & agent: Solido supporto nativo per tool calling, esecuzione Python e workflow agentici (ricerca documenti, analisi file, agent per data science). 11x velocità / <1% costo rispetto agli esperti umani per alcuni task GDPval (misura del potenziale valore economico, 70,9% vs ~38,8% precedente), e mostra miglioramenti concreti nel modeling su fogli (ad es., +9,3% in un task da junior investment banking vs GPT-5.1).
- Gemini 3 Pro: Transformer a Mixture-of-Experts sparso (MoE). Il modello attiva un piccolo set di esperti per token, abilitando una capacità di parametri totale estremamente grande con compute per token sublineare. Google pubblica una scheda del modello che chiarisce come il design MoE sparso sia un contributore chiave al profilo prestazionale migliorato. Questa architettura rende fattibile spingere la capacità del modello molto più in alto senza costo di inferenza lineare.
- GPT-5.2 (OpenAI): OpenAI continua a usare architetture basate su Transformer con strategie di routing/compaction nella famiglia GPT-5 (un “router” attiva modalità diverse — Instant vs Thinking — e l’azienda documenta tecniche di compattazione e gestione dei token per contesti lunghi). GPT-5.2 enfatizza l’addestramento e la valutazione per “pensare prima di rispondere” e la compattazione per task di lungo orizzonte piuttosto che annunciare un classico sparse-MoE su larga scala.
Implicazioni delle architetture
- Tradeoff di latenza e costo: modelli MoE come Gemini 3 Pro possono offrire maggiore capacità di picco per token mantenendo il costo d’inferenza più basso per molti task perché solo un sottoinsieme di esperti viene eseguito. Possono tuttavia aggiungere complessità al serving e allo scheduling (cold-start, bilanciamento degli esperti, IO). L’approccio di GPT-5.2 (denso/instradato con compattazione) favorisce latenza prevedibile ed ergonomia per sviluppatori — specialmente quando integrato con il tooling consolidato di OpenAI come Responses, Realtime, Assistants e API batch.
- Scalare il contesto lungo: la capacità di input da 1M token di Gemini consente di fornire nativamente documenti estremamente lunghi e stream multimodali. La finestra combinata di GPT-5.2 (~400k tra input+output) è comunque enorme e copre la maggior parte delle esigenze enterprise, ma è inferiore alla specifica da 1M di Gemini. Per corpora molto grandi o trascrizioni video di molte ore, la specifica di Gemini offre un chiaro vantaggio tecnico.
Strumenti, agent e integrazione multimodale
- OpenAI: integrazione profonda per tool calling, esecuzione Python, modalità di ragionamento “Pro” e ecosistemi agent a pagamento (ChatGPT Agents / integrazioni aziendali). Forte focus su workflow incentrati sul codice e generazione di fogli/slide come output di prima classe.
- Google / Gemini: grounding integrato su Google Search (feature opzionale a pagamento), esecuzione di codice, contesto URL e file, e controlli espliciti della risoluzione dei media per scambiare token con fedeltà visiva. L’API offre
thinking_levele altre leve per ottimizzare costo/latenza/qualità.
Come si confrontano i numeri dei benchmark
Finestre di contesto e gestione dei token
- Gemini 3 Pro Preview: 1,000,000 token in input / 64k token in output (scheda del modello Pro preview). Knowledge cutoff: gennaio 2025 (Google).
- GPT-5.2: OpenAI dimostra solide prestazioni su contesti lunghi (punteggi MRCRv2 su needle task 4k–256k con range >85–95% in molte impostazioni) e utilizza funzionalità di compattazione; gli esempi pubblici di contesto mostrano prestazioni robuste anche su contesti molto ampi ma OpenAI elenca finestre specifiche per variante (ed enfatizza la compattazione piuttosto che un unico numero 1M). Per l’uso via API, i nomi modello sono
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Benchmark di ragionamento e agentici
- OpenAI (selezione): Tau2-bench Telecom 98,7% (GPT-5.2 Thinking), forti incrementi nell’uso multi-step degli strumenti e nei task agentici (OpenAI evidenzia il collasso di sistemi multi-agente in un “mega-agente”). GPQA Diamond e ARC-AGI mostrano salti rispetto a GPT-5.1.
- Google (selezione): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87,6%, elevati punteggi in GPQA e Humanity’s Last Exam; Google dimostra anche forti capacità di pianificazione di lungo orizzonte tramite esempi agentici.
Tooling e agenti:
GPT-5.2: Solido supporto nativo per tool calling, esecuzione Python e workflow agentici (ricerca documenti, analisi file, agent per data science). 11x velocità / <1% costo rispetto agli esperti umani per alcuni task GDPval (misura del potenziale valore economico, 70,9% vs ~38,8% precedente), e mostra miglioramenti concreti nel modeling su fogli (ad es., +9,3% in un task da junior investment banking vs GPT-5.1).
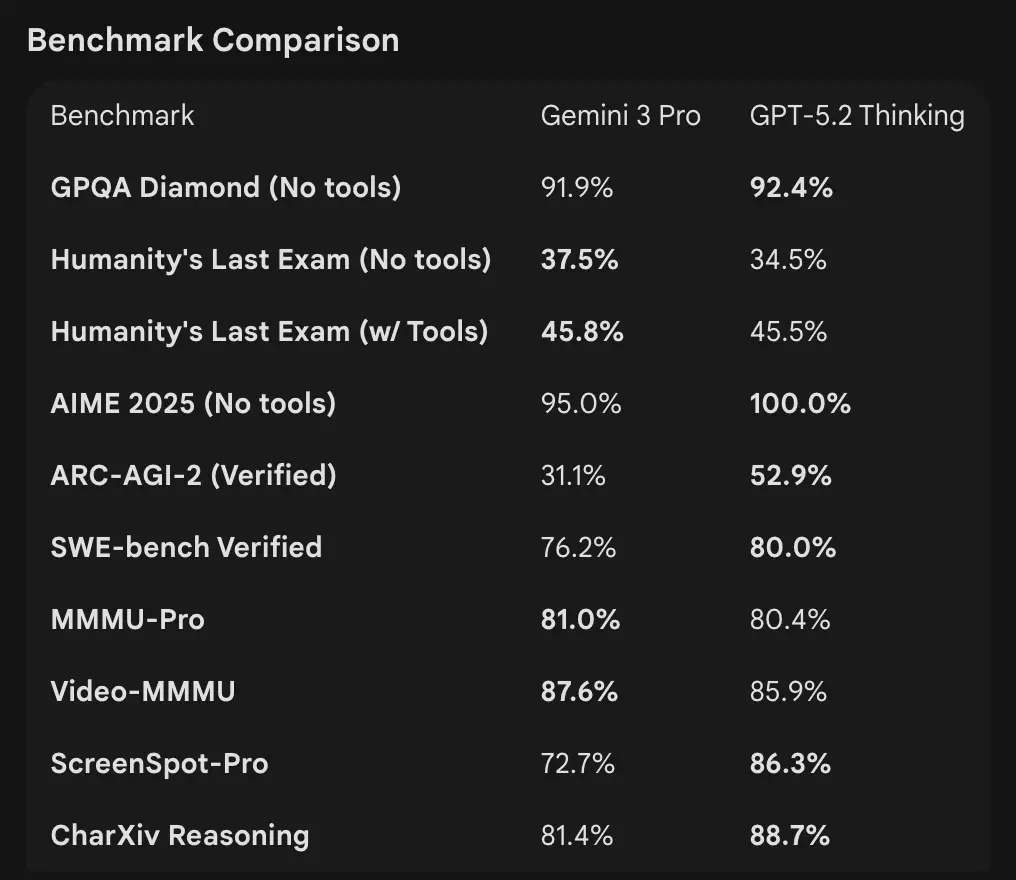
Interpretazione: i benchmark sono complementari — OpenAI enfatizza i benchmark di lavoro reale della conoscenza (GDPval) mostrando che GPT-5.2 eccelle in task di produzione come fogli di calcolo, slide e lunghe sequenze agentiche. Google enfatizza classifiche di ragionamento grezzo e finestre di contesto a singola richiesta estremamente grandi. Quale conti di più dipende dal carico: pipeline enterprise agentiche e su documenti lunghi favoriscono le prestazioni comprovate di GPT-5.2 su GDPval; l’ingestione di contesti enormi (ad es., interi corpora video/libri in un solo passaggio) favorisce la finestra di input da 1M di Gemini.
Come si confrontano le capacità multimodali?
Input e output
- Gemini 3 Pro Preview: supporta input testo, immagine, video, audio, PDF e output testuali; Google fornisce controlli granulari
media_resolutione un parametrothinking_levelper sintonizzare costo vs fedeltà nel lavoro multimodale. Limite di output 64k token; input fino a 1M token. - GPT-5.2: supporta workflow vision e multimodali ricchi; OpenAI evidenzia ragionamento spaziale migliorato (etichette stimate dei bounding component nelle immagini), comprensione video (punteggi Video MMMU) e vision abilitata da strumenti (lo strumento Python su task di visione migliora i punteggi). GPT-5.2 sottolinea che i task complessi visione + codice beneficiano molto quando è abilitato il supporto agli strumenti (esecuzione di codice Python).
Differenze pratiche
Granularità vs ampiezza: Gemini espone una suite di manopole multimodali (media_resolution, thinking_level) pensate per consentire agli sviluppatori di regolare i tradeoff per tipo di media. GPT-5.2 enfatizza l’uso integrato degli strumenti (eseguire Python nel loop) per combinare visione, codice e trasformazioni dati. Se il tuo caso d’uso si basa molto su analisi video + immagine con contesti estremamente ampi, la finestra da 1M di Gemini è convincente; se i tuoi workflow richiedono l’esecuzione di codice nel loop (trasformazioni dati, generazione di fogli), il tooling e la predisposizione agli agent di GPT-5.2 possono essere più comodi.
E per accesso API, SDK e prezzi?
OpenAI GPT-5.2 (API e prezzi)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provia Responses API / Chat Completions. SDK consolidati (Python/JS), guide “cookbook” e un ecosistema maturo. - Prezzi (pubblici): $1.75 / 1M token in input e $14 / 1M token in output; sconti di caching (90% per input in cache) riducono il costo effettivo per dati ripetuti. OpenAI enfatizza l’efficienza per token (prezzo per token più alto ma minor costo totale per raggiungere la soglia di qualità).
Gemini 3 Pro Preview (API e prezzi)
- API:
gemini-3-pro-previewvia Google GenAI SDK e endpoint Vertex AI/GenerativeLanguage. Nuovi parametri (thinking_level,media_resolution) e integrazione con grounding Google e strumenti. - Prezzi (anteprima pubblica): Circa $2 / 1M token in input e $12 / 1M token in output per tier di anteprima sotto i 200k token; potrebbero applicarsi costi aggiuntivi per Search grounding, Maps o altri servizi Google (fatturazione per Search grounding a partire dal 5 gennaio 2026).
Usa GPT-5.2 e Gemini 3 tramite CometAPI
CometAPI è una gateway / aggregator API: un singolo endpoint REST in stile OpenAI che offre accesso unificato a centinaia di modelli di molti fornitori (LLM, modelli di immagine/video, embedding, ecc.). Invece di integrare molti SDK dei vendor, CometAPI permette di chiamare endpoint in formato OpenAI familiari (chat/completions/embeddings/images) mentre si commutano modelli o fornitori sotto il cofano.
Gli sviluppatori possono utilizzare contemporaneamente modelli flagship di due aziende diverse tramite CometAPI senza cambiare fornitore, e i prezzi dell’API sono più convenienti, di solito con uno sconto del 20%.
Esempio: snippet API rapidi (copia-incolla per provare)
Di seguito esempi minimi eseguibili. Riflettono i quickstart pubblicati dai vendor (OpenAI Responses API + client Google GenAI). Sostituisci $OPENAI_API_KEY / $GEMINI_API_KEY con le tue chiavi.
GPT-5.2 — Python (OpenAI Responses API, ragionamento impostato su xhigh per problemi complessi)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Note: reasoning.effort ti consente di scambiare costo vs profondità. Usa gpt-5.2-chat-latest per lo stile chat Instant. La documentazione OpenAI mostra esempi per responses.create.
GPT-5.2 — curl (semplice)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(Controlla il JSON per output_text o output strutturati.)
Gemini 3 Pro Preview — Python (client Google GenAI)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Note: thinking_level controlla la deliberazione interna del modello; media_resolution può essere impostato per immagini/video. Esempi REST e JS sono nella guida per sviluppatori di Gemini di Google.;
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
La documentazione di Google include esempi multimodali (dati immagine inline, media_resolution).
Qual è il modello “migliore” — guida pratica
Non esiste un “vincitore” valido per tutti; la scelta va fatta in base a caso d’uso e vincoli. Di seguito una breve matrice decisionale.
Scegli GPT-5.2 se:
- Hai bisogno di integrazione stretta con strumenti di esecuzione del codice (ecosistema interpreter/tool di OpenAI) per pipeline dati programmatiche, generazione di fogli, o workflow agentici di codice. OpenAI evidenzia miglioramenti allo strumento Python e l’uso del mega-agente agentico.
- Dai priorità all’efficienza dei token come dichiarato dal fornitore e vuoi prezzi per token OpenAI espliciti e prevedibili con grandi sconti sugli input in cache (utile per workflow batch/produzione).
- Vuoi l’ecosistema OpenAI (integrazione prodotto ChatGPT, partnership Azure/Microsoft, e tooling attorno a Responses API e Codex).
Scegli Gemini 3 Pro se:
- Hai bisogno di input multimodale estremo (video + immagini + audio + pdf) e vuoi un singolo modello che accetti nativamente tutti questi input con una finestra di input da 1,000,000 token. Google promuove esplicitamente questo per video lunghi, pipeline di documenti + video di grandi dimensioni e casi d’uso con Search/AI Mode interattivo.&
- Stai costruendo su Google Cloud / Vertex AI e desideri integrazione stretta con il grounding di Google Search, il provisioning Vertex e le GenAI client API. Beneficerai delle integrazioni con i prodotti Google (Search AI Mode, AI Studio, Antigravity per strumenti agentici).
Conclusione: quale è migliore nel 2026?
Nello scontro GPT-5.2 vs. Gemini 3 Pro Preview, la risposta è dipende dal contesto:
- GPT-5.2 è in testa per il lavoro professionale della conoscenza, la profondità analitica e i workflow strutturati.
- Gemini 3 Pro Preview eccelle nella comprensione multimodale, negli ecosistemi integrati e nei task a contesto ampio.
Nessun modello è universalmente “migliore”—le rispettive forze rispondono a esigenze reali diverse. Gli adottanti più smart dovrebbero allineare la scelta del modello a casi d’uso specifici, vincoli di budget e allineamento di ecosistema.
Quello che è chiaro nel 2026 è che il fronte dell’IA è avanzato significativamente, e sia GPT-5.2 sia Gemini 3 Pro stanno spingendo i confini di ciò che i sistemi intelligenti possono fare nell’impresa e oltre.
Se vuoi provare subito, esplora le capacità di GPT-5.2 e Gemini 3 Pro su CometAPI nel Playground e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo ben inferiore a quello ufficiale per aiutarti nell’integrazione.
Pronti a iniziare?→ Prova gratuita di GPT-5.2 e Gemini 3 Pro !
Se vuoi