

OpenAI ha pubblicato un'anteprima della ricerca gpt-oss-safeguard, una famiglia di modelli di inferenza open-weight progettata per consentire agli sviluppatori di applicare proprio politiche di sicurezza al momento dell'inferenza. Invece di spedire un classificatore fisso o un motore di moderazione black-box, i nuovi modelli sono ottimizzati per motivo derivante da una politica fornita dallo sviluppatore, emettono una catena di pensiero (CoT) che spiega il loro ragionamento e producono output di classificazione strutturati. Annunciato come anteprima della ricerca, gpt-oss-safeguard è presentato come una coppia di modelli di ragionamento:gpt-oss-safeguard-120b e al gpt-oss-safeguard-20b—ottimizzato dalla famiglia gpt-oss e progettato esplicitamente per eseguire attività di classificazione della sicurezza e di applicazione delle policy durante l'inferenza.
Che cos'è gpt-oss-safeguard?
gpt-oss-safeguard è una coppia di modelli di ragionamento open-weight e solo testo che sono stati post-addestrati dalla famiglia gpt-oss per interpretare una policy scritta in linguaggio naturale ed etichettare il testo in base a tale policyLa caratteristica distintiva è che la politica è fornito al momento dell'inferenza (policy-as-input), non integrati nei pesi dei classificatori statici. I modelli sono progettati principalmente per attività di classificazione della sicurezza, ad esempio moderazione multi-policy, classificazione dei contenuti in più regimi normativi o controlli di conformità alle policy.
Perché questo importa
I sistemi di moderazione tradizionali si basano in genere su (a) set di regole fisse mappate su classificatori addestrati su esempi etichettati, oppure (b) euristiche/regex per il rilevamento delle parole chiave. gpt-oss-safeguard tenta di cambiare il paradigma: invece di riaddestrare i classificatori ogni volta che cambiano le policy, si fornisce un testo di policy (ad esempio, la policy di utilizzo accettabile della propria azienda, i TOS della piattaforma o le linee guida di un ente regolatore) e il modello valuta se un determinato contenuto viola tale policy. Questo promette agilità (le policy cambiano senza riaddestrare) e interpretabilità (il modello produce la sua catena di ragionamento).
Questa è la sua filosofia fondamentale: "Sostituire la memorizzazione con il ragionamento e le supposizioni con la spiegazione".
Ciò rappresenta una nuova fase nella sicurezza dei contenuti, passando dall'“apprendimento passivo delle regole” alla “comprensione attiva delle regole”.
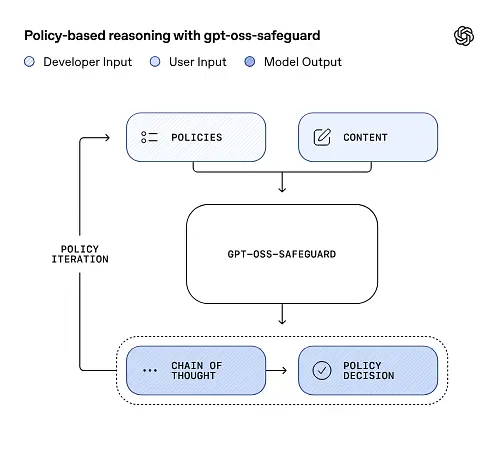
gpt-oss-safeguard può leggere direttamente le policy di sicurezza definite dagli sviluppatori e seguirle per formulare giudizi durante l'inferenza.
Come funziona gpt-oss-safeguard?
Ragionamento basato sulla politica come input
Al momento dell'inferenza, fornisci due cose: testo della politica e la contenuto del candidato da etichettare. Il modello considera la policy come istruzione primaria e quindi esegue un ragionamento passo dopo passo per determinare se il contenuto è consentito, non consentito o richiede ulteriori passaggi di moderazione. In fase di inferenza, il modello:
- produce un output strutturato che include una conclusione (etichetta, categoria, affidabilità) e una traccia di ragionamento leggibile dall'uomo che spiega perché si è giunti a quella conclusione.
- ingerisce la politica e il contenuto da classificare,
- ragiona internamente attraverso le clausole della politica utilizzando passaggi simili a una catena di pensiero, e
Per esempio:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Risponderà:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Catena di pensiero (CoT) e output strutturati
gpt-oss-safeguard può generare una traccia CoT completa come parte di ogni inferenza. La traccia CoT è progettata per essere ispezionabile: i team di conformità possono leggere perché il modello è giunto a una determinata conclusione e gli ingegneri possono utilizzare la traccia per diagnosticare l'ambiguità delle policy o le modalità di errore del modello. Il modello supporta anche risultati strutturati—ad esempio, un JSON che contiene un verdetto, sezioni di policy violate, punteggio di gravità e azioni correttive suggerite—rendendolo semplice da integrare nelle pipeline di moderazione.
Livelli di “sforzo di ragionamento” sintonizzabili
Per bilanciare latenza, costi e completezza, i modelli supportano uno sforzo di ragionamento configurabile: basso / medio / altoUn impegno maggiore aumenta la profondità della catena di pensiero e generalmente produce inferenze più robuste, ma più lente e costose. Questo consente agli sviluppatori di smistare i carichi di lavoro: utilizzare un impegno basso per i contenuti di routine e uno sforzo elevato per i casi limite o i contenuti ad alto rischio.
Qual è la struttura del modello e quali versioni esistono?
Famiglia modello e lignaggio
gpt-oss-safeguard sono post-addestrato varianti delle precedenti di OpenAI gpt-oss modelli aperti. La famiglia di prodotti di salvaguardia include attualmente due dimensioni rilasciate:
- gpt-oss-safeguard-120b — un modello da 120 miliardi di parametri pensato per attività di ragionamento ad alta precisione che funziona comunque su una singola GPU da 80 GB in tempi di esecuzione ottimizzati.
- gpt-oss-safeguard-20b — un modello da 20 miliardi di parametri ottimizzato per inferenza a basso costo e ambienti edge o on-prem (può essere eseguito su dispositivi VRAM da 16 GB in alcune configurazioni).
Note sull'architettura e caratteristiche di runtime (cosa aspettarsi)
- Parametri attivi per token: L'architettura gpt-oss sottostante utilizza tecniche che riducono il numero di parametri attivati per token (un mix di attenzione densa e sparsa / stile di progettazione misto di esperti nel gpt-oss padre).
- in pratica, la classe 120B si adatta a singoli acceleratori di grandi dimensioni, mentre la classe 20B è progettata per funzionare su configurazioni VRAM da 16 GB in tempi di esecuzione ottimizzati.
I modelli di salvaguardia erano non addestrato con dati biologici o di sicurezza informatica aggiuntivie che le analisi degli scenari di abuso peggiori eseguite per la versione gpt-oss si applicano in modo approssimativo alle varianti di salvaguardia. I modelli sono destinati alla classificazione piuttosto che alla generazione di contenuti per gli utenti finali.
Quali sono gli obiettivi di gpt-oss-safeguard
Obiettivi
- Flessibilità politica: consentire agli sviluppatori di definire qualsiasi policy in linguaggio naturale e di far sì che il modello la applichi senza dover raccogliere etichette personalizzate.
- Spiegabilità: esporre il ragionamento in modo che le decisioni possano essere verificate e le politiche iterate.
- Accessibilità: fornire un'alternativa open-weight in modo che le organizzazioni possano eseguire il ragionamento sulla sicurezza a livello locale e ispezionare gli interni del modello.
Confronto con i classificatori classici
Pro vs. classificatori tradizionali
- Nessuna riqualificazione per le modifiche alle policy: Se la tua politica di moderazione cambia, aggiorna il documento della politica anziché raccogliere etichette e riaddestrare un classificatore.
- Ragionamento più ricco: I risultati del CoT possono rivelare sottili interazioni politiche e fornire una giustificazione narrativa utile ai revisori umani.
- Personalizzazione: Un singolo modello può applicare simultaneamente molte politiche diverse durante l'inferenza.
Classificatori tradizionali vs. classificatori contro
- Limiti di prestazione per alcune attività: La valutazione di OpenAI rileva che classificatori di alta qualità addestrati su decine di migliaia di esempi etichettati possono superare gpt-oss-safeguard su attività di classificazione specializzate. Quando l'obiettivo è l'accuratezza della classificazione grezza e si hanno dati etichettati, un classificatore dedicato, addestrato su quella distribuzione, può essere più efficace.
- Latenza e costo: Il ragionamento con CoT richiede un'elaborazione intensiva ed è più lento rispetto a un classificatore leggero; questo può rendere costose su larga scala le pipeline basate esclusivamente sulla salvaguardia.
In breve: gpt-oss-safeguard è meglio utilizzato dove agilità e verificabilità delle politiche sono prioritari o quando i dati etichettati sono scarsi, e come componente complementare in pipeline ibride, non necessariamente come sostituto immediato di un classificatore ottimizzato su scala.
Come si è comportato gpt-oss-safeguard nelle valutazioni di OpenAI?
OpenAI ha pubblicato i risultati di base in un rapporto tecnico di 10 pagine che riassume le valutazioni interne ed esterne. Punti chiave (metriche selezionate e rilevanti):
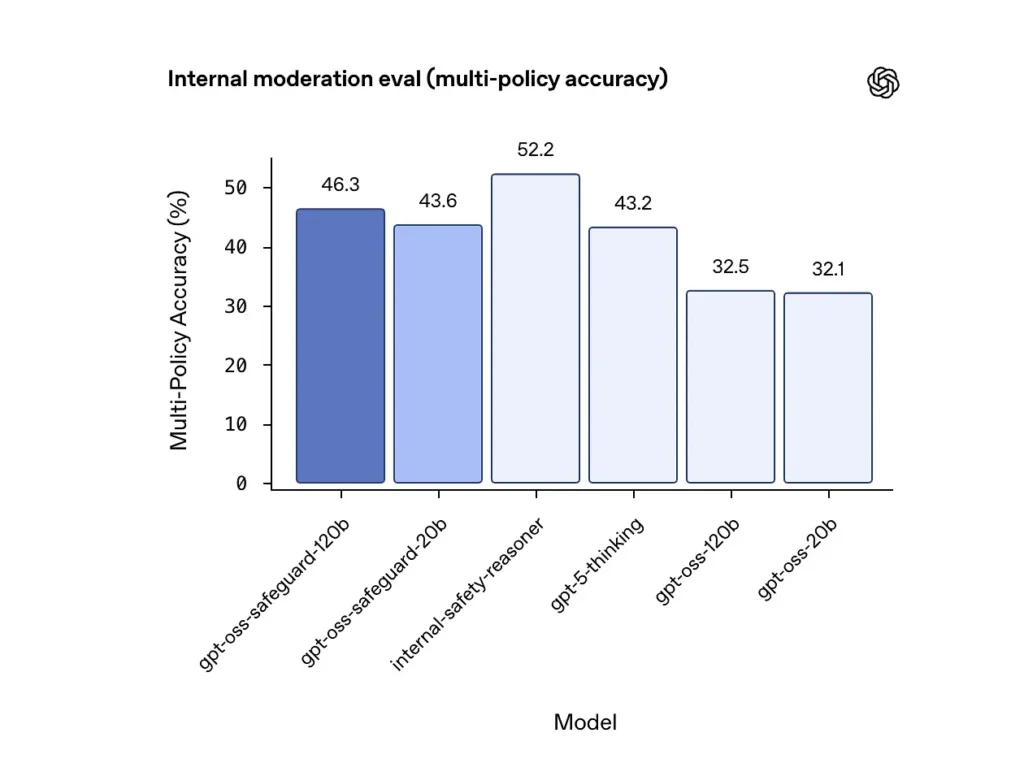
Precisione multi-policy (valutazione interna)
OpenAI ha valutato l'accuratezza multi-policy fornendo il modello multiplo politiche simultaneamente e contando una previsione come corretta solo se corrisponde alle etichette dorate contro tutti i politiche. Risultati:
- gpt-oss-safeguard-120b: 46.3% precisione multi-polizza
- gpt-oss-safeguard-20b: 43.6%
- Per confronto: gpt-5-pensiero: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
L'insieme interno "safety-reasoner" di OpenAI ha ottenuto un punteggio del 52.2% nello stesso test. Questi numeri mostrano che i modelli di salvaguardia superano notevolmente i loro modelli base gpt-oss nel compito multi-policy, e hanno persino superato la più ampia base di pensiero gpt-5 nella metrica interna multi-policy.
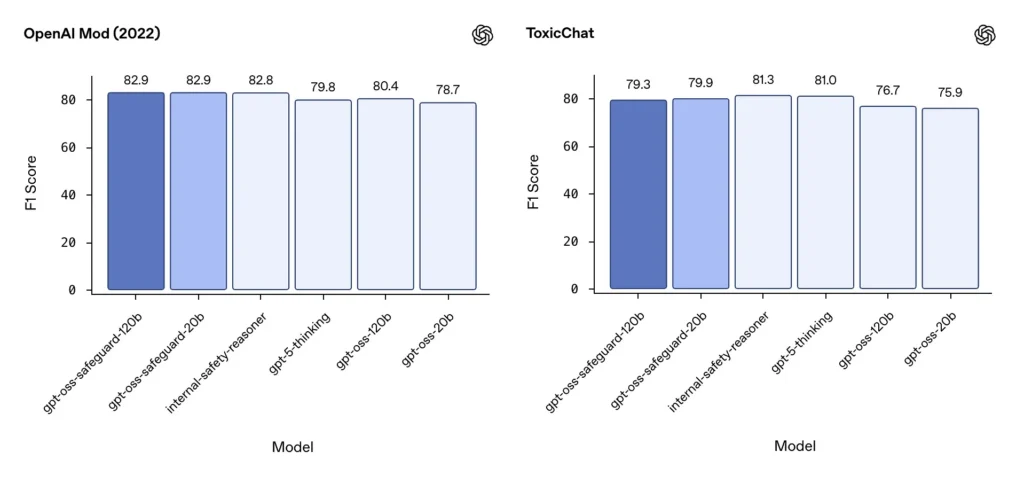
Moderazione F1 (benchmark esterni)
Nel set di dati di moderazione di OpenAI del 2022 e nel benchmark pubblico ToxicChat, i modelli gpt-oss-safeguard hanno ottenuto solidi punteggi F1:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Questi punteggi posizionano gpt-oss-safeguard vicino o leggermente dietro ai sistemi interni specializzati di OpenAI in alcuni benchmark e generalmente davanti alle controparti gpt-oss non ottimizzate.
Limitazioni osservate
OpenAI segnala due limitazioni pratiche:
- I classificatori addestrati su grandi set di dati etichettati e specifici per attività possono comunque superare i modelli di salvaguardia quando l'unico obiettivo è l'accuratezza della classificazione.
- Costi di elaborazione e latenza: Il ragionamento CoT aumenta il tempo di inferenza e il consumo di elaborazione, il che complica il ridimensionamento del traffico a livello di piattaforma, a meno che non venga abbinato a classificatori di triage e pipeline asincrone.
Parità multilingue
gpt-oss-safeguard ha prestazioni pari a quelle dei modelli gpt-oss sottostanti in molti linguaggi nei test in stile MMMLU, indicando che le varianti di salvaguardia ottimizzate mantengono un'ampia capacità di ragionamento.
In che modo i team possono accedere e distribuire gpt-oss-safeguard?
OpenAI fornisce i pesi per Apache 2.0 e collega i modelli per il download (Hugging Face). Poiché gpt-oss-safeguard è un modello open-weight, è consigliabile un deployment locale e autogestito (consigliato per privacy e personalizzazione).
- Scarica i pesi del modello (da OpenAI / Hugging Face) e ospitarli sui propri server o su VM cloud. Apache 2.0 consente modifiche e utilizzo commerciale.
- Runtime: Utilizza runtime di inferenza standard che supportano modelli di trasformatori di grandi dimensioni (ONNX Runtime, Triton o runtime di fornitori ottimizzati). Runtime della community come Ollama e LM Studio stanno già aggiungendo il supporto per le famiglie gpt-oss.
- Hardware: 120B richiede in genere GPU con elevata capacità di memoria (ad esempio, A100/H100 da 80 GB o sharding multi-GPU), mentre 20B può essere gestito a costi più bassi e offre opzioni ottimizzate per configurazioni VRAM da 16 GB. Pianificare la capacità in base al throughput di picco e ai costi di valutazione multi-policy.
Runtime gestiti e di terze parti
Se non è pratico gestire il proprio hardware, CometaAPI sta rapidamente aggiungendo il supporto per i modelli gpt-oss. Queste piattaforme possono offrire una scalabilità più semplice, ma reintroducono compromessi in termini di esposizione dei dati di terze parti. Valutare privacy, SLA e controlli di accesso prima di scegliere runtime gestiti.
Strategie di moderazione efficaci con gpt-oss-safeguard
1) Utilizzare una pipeline ibrida (triage → ragione → aggiudicazione)
- Livello di triage: Classificatori (o regole) piccoli e veloci filtrano i casi banali. Questo riduce il carico sul costoso modello di salvaguardia.
- Livello di salvaguardia: eseguire gpt-oss-safeguard per controlli ambigui, ad alto rischio o multi-policy in cui le sfumature della policy sono importanti.
- Giudizio umano: Escalare i casi limite e i ricorsi, archiviando i dati CoT come prova di trasparenza. Questo design ibrido bilancia produttività e precisione.
2) Ingegneria delle politiche (non ingegneria dei prompt)
- Tratta le policy come artefatti software: creane delle versioni, testale su set di dati e mantienile esplicite e gerarchiche.
- Redigi policy con esempi e controesempi. Quando possibile, includi istruzioni disambiguanti (ad esempio, "Se l'intento dell'utente è chiaramente esplorativo e storico, etichetta come X; se l'intento è operativo e in tempo reale, etichetta come Y").
3) Configurare dinamicamente lo sforzo di ragionamento
- Usa il poco sforzo per l'elaborazione in serie e grande sforzo per contenuti segnalati, ricorsi o settori verticali ad alto impatto (legale, medico, finanziario).
- Regola le soglie con il feedback delle recensioni umane per trovare il giusto rapporto costo/qualità.
4) Convalidare CoT e osservare il ragionamento allucinato
La CoT è preziosa, ma può creare allucinazioni: la traccia è una logica generata da un modello, non una verità di base. Verificate regolarmente i risultati della CoT; strumentate rilevatori per citazioni allucinate o ragionamenti non corrispondenti. OpenAI documenta le catene di pensiero allucinate come una sfida osservata e suggerisce strategie di mitigazione.
5) Creare set di dati dal funzionamento del sistema
Registrare le decisioni del modello e le correzioni umane per creare set di dati etichettati che possono migliorare i classificatori di triage o informare la riscrittura delle policy. Nel tempo, un set di dati etichettato piccolo e di alta qualità, unito a un classificatore efficiente, spesso riduce la dipendenza dall'inferenza CoT completa per i contenuti di routine.
6) Monitorare i calcoli e i costi; utilizzare flussi asincroni
Per le applicazioni a bassa latenza rivolte al consumatore, si consiglia di prendere in considerazione controlli di sicurezza asincroni con un'esperienza utente conservativa a breve termine (ad esempio, nascondere temporaneamente i contenuti in attesa di revisione) anziché eseguire CoT ad alto impegno in modo sincrono. OpenAI sottolinea che Safety Reasoner utilizza flussi asincroni internamente per gestire la latenza per i servizi di produzione.
7) Considerare la privacy e il luogo di distribuzione
Poiché i pesi sono aperti, è possibile eseguire l'inferenza interamente in locale per conformarsi a una rigorosa governance dei dati o ridurre l'esposizione ad API di terze parti, il che è prezioso per i settori regolamentati.
Conclusione:
gpt-oss-safeguard è uno strumento pratico, trasparente e flessibile per ragionamento sulla sicurezza basato sulle politicheBrilla quando ne hai bisogno decisioni verificabili legate a politiche esplicite, quando le tue politiche cambiano frequentemente o quando vuoi mantenere i controlli di sicurezza in sede. È non è un Una soluzione miracolosa che sostituirà automaticamente i classificatori specializzati ad alto volume: le valutazioni di OpenAI mostrano che i classificatori dedicati, addestrati su grandi corpora etichettati, possono superare questi modelli in termini di accuratezza grezza per compiti specifici. È invece opportuno considerare gpt-oss-safeguard come un componente strategico: il motore di ragionamento spiegabile al centro di un'architettura di sicurezza a più livelli (triage rapido → ragionamento spiegabile → supervisione umana).
Iniziamo
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
L'ultima integrazione gpt-oss-safeguard apparirà presto su CometAPI, quindi rimanete sintonizzati! Mentre finalizziamo il caricamento del modello gpt-oss-safeguard, gli sviluppatori possono accedere API GPT-OSS-20B e al API GPT-OSS-120B tramite CometAPI, l'ultima versione del modello è sempre aggiornato con il sito ufficiale. Per iniziare, esplora le capacità del modello nel Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!