

Grok-4-Fast è di xAI nuovo modello di ragionamento economicamente efficiente progettato per rendere il ragionamento di alta qualità e le capacità di ricerca sul web più economiche e veloci sia per l'uso da parte dei consumatori che degli sviluppatori. xAI lo posiziona come un frontiera offerta che preserva le prestazioni di riferimento di Grok-4 migliorando al contempo l'efficienza del token e spedisce due varianti ottimizzate per entrambi ragionamento or non ragionamento carichi di lavoro.
Caratteristiche principali (elenco rapido)
- Due varianti del modello:
grok-4-fast-reasoninge algrok-4-fast-non-reasoning(regolabile per profondità vs. velocità). - Finestra di contesto molto ampia: fino all Token 2,000,000, consentendo documenti estremamente lunghi / trascrizioni di più ore / flussi di lavoro multi-documento.
- Efficienza del token / focus sui costi: Rapporti xAI ~40% in meno di token pensanti in media rispetto a Grok-4 e un affermato Riduzione del ~98% dei costi per raggiungere le stesse prestazioni di riferimento (sui report delle metriche xAI).
- Integrazione di strumenti nativi/navigazione: addestrato end-to-end con RL basato sull'uso di strumenti per la navigazione web/X, l'esecuzione di codice e i comportamenti di ricerca agenti.
- Chiamata multimodale e di funzione: supporta immagini e output strutturati; nell'API sono supportati formati di chiamata di funzione e di risposta strutturata.
Dettagli tecnici
Architettura di ragionamento unificato: Grok-4-Fast utilizza un base di peso del modello singolo che può essere indirizzato verso ragionamento (lunga catena di pensiero) o non ragionamento (risposte rapide) tramite prompt di sistema o selezione di varianti, anziché distribuire due modelli di backbone completamente separati. Ciò riduce la latenza di commutazione e il costo dei token per carichi di lavoro misti.
Apprendimento per rinforzo per la densità di intelligenza: xAI segnala l'utilizzo apprendimento per rinforzo su larga scala focalizzata sulla densità di intelligenza (massimizzazione delle prestazioni per token), che è la base per i guadagni di efficienza dei token dichiarati.
Condizionamento degli strumenti e ricerca agentica: Grok-4-Fast è stato addestrato e valutato su attività che richiedono l'invocazione di strumenti (navigazione web, ricerca X, esecuzione di codice). Il modello è presentato come abile in la scelta quando chiamare gli strumenti e come trasformare le prove di navigazione in risposte.
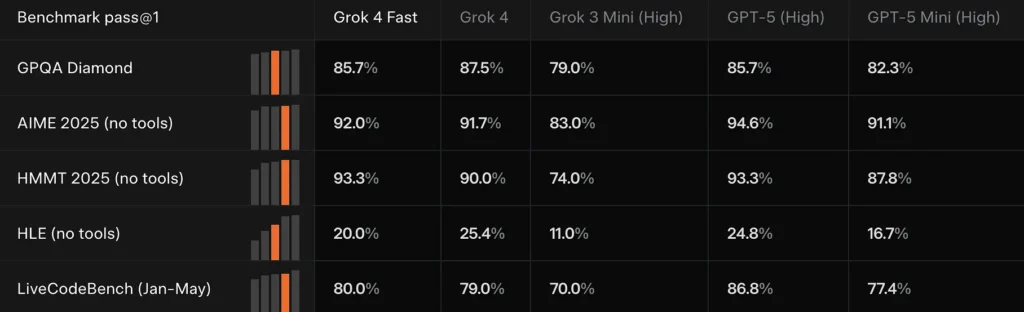
Prestazioni di riferimento
Imiglioramenti in BrowseComp (44.9% pass@1 contro 43.0% per Grok-4), **SimpleQA (95.0% contro 94.0%)**e grandi guadagni in alcune arene di navigazione/ricerca in lingua cinese. xAI segnala anche un posizionamento di vertice nella Search Arena di LMArena per un grok-4-fast-search variante.
Versioni e denominazione del modello
Nomi pubblici annunciati da xAI: grok-4-fast-reasoning e al **grok-4-fast-non-reasoning**Ogni variante riporta lo stesso gettone da 2 milioni limite di contesto. La piattaforma continua anche a ospitare il precedente Grok-4 ammiraglia (ad esempio, grok-4-0709 varianti utilizzate in precedenza).
Limitazioni e considerazioni sulla sicurezza
- Problemi di sicurezza dei contenuti: Le segnalazioni provenienti da fonti investigative indicano che la famiglia Grok di xAI (e alcune funzionalità di Grok) è stata sviluppata con opzioni di contenuto permissive e che alcuni flussi di lavoro interni hanno esposto gli annotatori a materiale altamente inquietante. Vi sono esplicite preoccupazioni circa la robustezza della moderazione e la segnalazione alle autorità di contenuti illegali. Questi problemi di sicurezza e conformità sono rilevanti quando si implementa qualsiasi variante di Grok in produzione.
- Verifica indipendente: Molte delle affermazioni di xAI in termini di prestazioni/risparmio energetico sono auto-dichiarate; benchmark indipendenti e revisioni tra pari sono ancora in fase di pubblicazione. Considerate le affermazioni sull'efficienza dei costi come fornite dal fornitore finché non sarà disponibile una replica di terze parti.
- Rischi operativi: poiché Grok-4-Fast è concepito per la navigazione agentica, gli utenti dovrebbero tenerne conto allucinazione, limiti di freschezza dei dati (nonostante la capacità di navigazione), e Privacy considerazioni quando il modello viene utilizzato con strumenti esterni o query web live.
Casi d'uso tipici e consigliati
- Ricerca e recupero ad alta produttività — agenti di ricerca che necessitano di un ragionamento web multi-hop veloce.
- Assistenti e bot agentici — agenti che combinano navigazione, esecuzione di codice e chiamate di strumenti asincroni (ove consentito).
- Distribuzioni di produzione sensibili ai costi — servizi che richiedono molte chiamate e richiedono un'economia token-to-utility migliorata rispetto a un modello base più pesante.
- Sperimentazione degli sviluppatori — prototipazione di flussi multimodali o web-augmented che si basano su query rapide e ripetute.
Come chiamare grok-4-fast API di CometAPI
grok-code-fast-1 Prezzi API in CometAPI: sconto del 20% sul prezzo ufficiale:
| grok-4-fast-non-ragionamento | Token di input: $0.16/M token Token di output: $0.40/M di token |
| ragionamento grok-4-fast | Token di input: $0.16/M token Token di output: $0.40/M di token |
Passi richiesti
- Accedere cometapi.comSe non sei ancora un nostro utente, registrati prima
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.
Usa il metodo
- Selezionare l'opzione "
grok-4-fast-reasoning"/"grok-4-fast-reasoning"endpoint" per inviare la richiesta API e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per vostra comodità. - Sostituire con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo contenuto: il modello risponderà a questa domanda.
- Elaborare la risposta API per ottenere la risposta generata.
CometAPI fornisce un'API REST completamente compatibile, per una migrazione senza interruzioni. Dettagli chiave per Documento API:
- URL di base: https://api.cometapi.com/v1/chat/completions
- Nomi dei modelli:"
grok-4-fast-reasoning"/"grok-4-fast-reasoning" - Autenticazione: Token portatore tramite
Authorization: Bearer YOUR_CometAPI_API_KEYtestata - Tipo di contenuto:
application/json.
Integrazione API ed esempi
Frammento di Python per un Completamento chat chiamata tramite CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-4-fast's main features."}
]
response = openai.ChatCompletion.create(
model="grok-4-fast-reasoning",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Vedere anche Grok4