

Annunciato xAI Grok 4 Fast, una variante ottimizzata in termini di costi della sua famiglia Grok che, secondo l'azienda, offre prestazioni di riferimento quasi da ammiraglia, riducendo al contempo il prezzo per raggiungere tali prestazioni 98% rispetto a Grok 4. Il nuovo modello è progettato per la ricerca ad alto rendimento e l'uso di strumenti agenti e include una finestra di contesto da 2 milioni di token e varianti separate di "ragionamento" e "non ragionamento" per consentire agli sviluppatori di adattare il calcolo alle proprie esigenze.
Caratteristiche e vantaggi principali
Modello di inferenza conveniente: Grok 4 Fast è basato sulla famiglia Grok 4, con particolare attenzione all'efficienza dei token e all'utilizzo degli strumenti in tempo reale. xAI segnala che il modello richiede circa 40% in meno di token "pensanti" in media. L'analisi artificiale, che monitora la latenza, la velocità di output e il rapporto prezzo/prestazioni su molti modelli pubblici, colloca Grok 4 Fast in una posizione elevata nel confronto tra intelligenza e costi e conferma le rapide velocità di output del modello e il favorevole rapporto costi nei primi test.
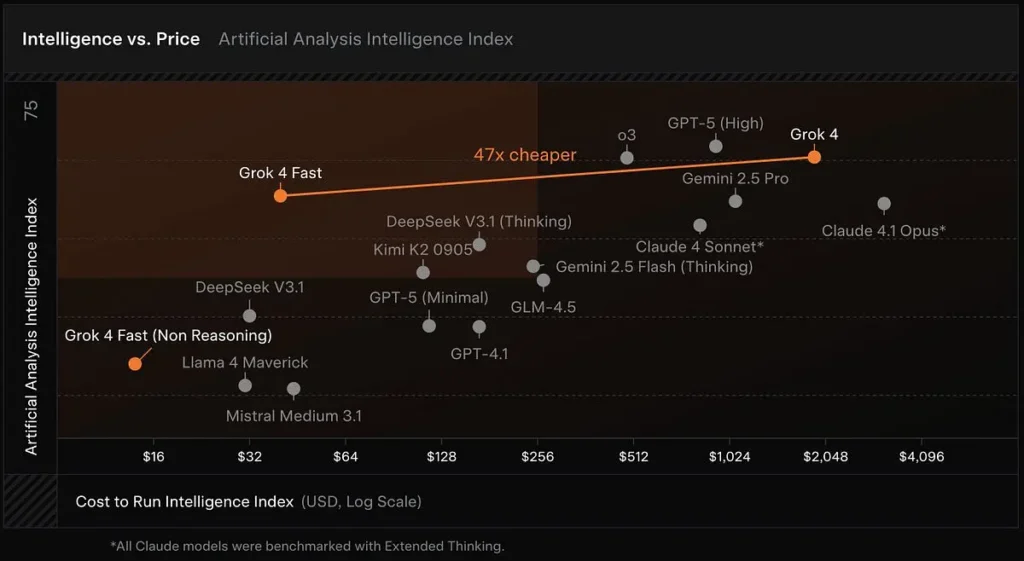
Grandi finestre di contesto: Grok 4 Fast è progettato per la ricerca ad alto rendimento e l'uso di strumenti agentici e include una finestra di contesto da 2 milioni di token e varianti separate di "ragionamento" e "non ragionamento" per consentire agli sviluppatori di adattare il calcolo alle proprie esigenze.
Capacità di utilizzo degli strumenti nativi: Grok 4 Fast fornisce "capacità di ricerca web e X all'avanguardia" che migliorano il recupero, la navigazione e la sintesi dei contenuti web durante i flussi di lavoro agentici, posizionando Grok 4 Fast come uno strumento di ricerca pratico per applicazioni che richiedono la raccolta di informazioni in tempo reale e il ragionamento su documenti lunghi, con prestazioni leader su più benchmark di ricerca, tra cui:
- SfogliaComp (zh): 51.2% (rispetto al 45.0% di Grok 4)
- X Bench Deepsearch (zh): 74.0% (contro il 66.0% di Grok 4)
Architettura unificata: Lo stesso modello supporta sia la modalità inferenziale che quella non inferenziale, eliminando la necessità di cambiare modello separatamente. La latenza e i costi ridotti lo rendono adatto ad applicazioni in tempo reale (come ricerca, risposte a domande e assistenza alla ricerca).
Confronto delle prestazioni (principali benchmark)
Nei test privati LMArena condivisi da xAI, il grok-4-fast-search (nome in codice Menlo) la variante è in cima alla Search Arena con un punteggio Elo di 1,163, mentre la variante di testo (tahoe) si colloca tra i primi dieci risultati della Text Arena, ovvero i risultati che xAI utilizza per supportare le sue affermazioni sulle prestazioni di ricerca.
Grok 4 Corrispondenza rapida o da vicino Grok 4 su più benchmark di frontiera (ad esempio: GPQA Diamond, AIME 2025 e HMMT 2025), superando al contempo i precedenti modelli più piccoli nei compiti di ragionamento: prova che xAI usa per giustificare l'affermazione di "prestazioni comparabili".
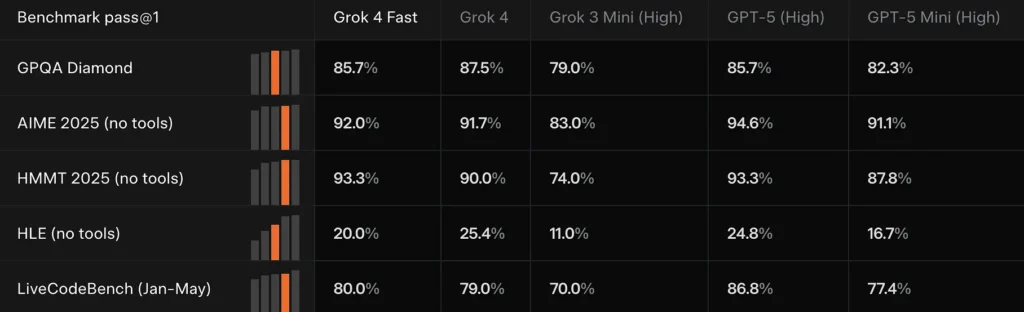
Confronta i risultati
Rispetto a Grok 4: più economico e meno impegnativo dal punto di vista computazionale, ma con prestazioni simili.
Rispetto a Grok 3 Mini: più potente, capace di ragionamenti complessi e ricerche in tempo reale.
Rispetto a GPT-5/Gemini/Claude: grazie alla sua elevatissima efficienza dei token e alle sue capacità di tooling, è leader in termini di economicità e di alcune attività di ricerca.
Prezzi e disponibilità
Contesto e token: Due modelli disponibili: grok-4-fast-reasoning e al grok-4-fast-non-reasoning, ciascuno con 2M di contesto.
Prezzi pubblicati (elenco) nel post di lancio (livelli di esempio):
- Token di input: $0.20 / 1 milione (<128k) — $0.40 / 1 milione (≥128k)
- Token di output: $0.50 / 1 milione (<128k) — $1.00 / 1 milione (≥128k)
- Token di input memorizzati nella cache: $0.05 / 1 milione.
(Per le regole di fatturazione precise e le promozioni a tempo limitato, vedere l'annuncio xAI.)
Disponibilità del fornitore: xAI elenca la disponibilità gratuita a breve termine tramite OpenRouter e Vercel AI Gateway e la disponibilità generale tramite l'API di xAI.
Cosa significa per gli utenti e i team
- Grandi risparmi sui costi per l'uso produttivo — la combinazione di prezzi per token più bassi e di un minor numero di token "pensanti" consente ai team di eseguire più query o flussi di lavoro di contesto più ampio a una piccola frazione del costo di Grok 4, il che riduce significativamente le barriere alla sperimentazione e alle distribuzioni su larga scala. (Affermazione supportata dalle informative sui costi/prestazioni di xAI e dalle analisi dei costi di terze parti.)
- Funziona con documenti molto lunghi e ragionamenti multi-step — I token da 2 milioni rendono pratico l'inserimento di interi libri, grandi basi di codice o lunghi dossier legali/tecnici in un'unica sessione, migliorando l'accuratezza e la coerenza per le attività che richiedono un contesto a lungo termine (ricerca di documenti, riepilogo, generazione di codice di lunga durata, assistenti di ricerca).
- Output più rapidi e a bassa latenza per applicazioni interattive — essendo una variante "Fast", è progettata per un throughput di token più rapido e una latenza inferiore, a vantaggio delle interfacce utente delle chat, degli assistenti di programmazione e dei cicli degli agenti in tempo reale, dove la reattività è importante. (L'analisi artificiale e i benchmark dei provider sottolineano la velocità di output come fattore di differenziazione.)
- Buon rapporto prezzo/prestazioni per attività di ragionamento di riferimento — per i team che valutano i modelli in base a parametri di riferimento accademici di frontiera, Grok 4 Fast offre un solido compromesso: precisione quasi di frontiera a costi notevolmente inferiori, il che lo rende interessante per i laboratori di ricerca e le aziende che eseguono frequentemente costose suite di benchmark.
Conclusione:
Grok 4 Fast posiziona xAI in una posizione competitiva in termini di rapporto prezzo/prestazioni e per le applicazioni basate su agenti incentrate sulla ricerca. Se le affermazioni dell'azienda in termini di efficienza e verifica saranno confermate da test indipendenti e specifici per dominio, Grok 4 Fast potrebbe ridefinire le aspettative di costo per le implementazioni LLM ad alta capacità e basate su strumenti, in particolare per le applicazioni che si basano sul recupero web in tempo reale e sull'utilizzo di strumenti multi-step.
Iniziamo
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Gli sviluppatori possono accedere Grok-4-fast (modello: grok-4-fast-reasoning” / “grok-4-fast-reasoning) tramite CometAPI, l'ultima versione del modello è sempre aggiornato con il sito ufficiale. Per iniziare, esplora le capacità del modello nel Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !