
grok-code-fast-1 è xAI modello di codifica agentica incentrato sulla velocità e conveniente progettato per alimentare integrazioni IDE e agenti di codifica automatizzati. Sottolinea bassa latenza, comportamenti agentivi (chiamate di strumenti, tracce di ragionamento graduale) e un profilo dei costi compatto per i flussi di lavoro quotidiani degli sviluppatori.
Caratteristiche principali (a colpo d'occhio)
- Elevata produttività/bassa latenza: focalizzato su un output di token molto veloce e completamenti rapidi per l'uso IDE.
- Chiamata di funzioni agentive e strumenti: supporta chiamate di funzioni e orchestrazione di strumenti esterni (esecuzione di test, linter, recupero di file) per abilitare agenti di codifica multi-step.
- Ampia finestra di contesto: progettato per gestire ampie basi di codice e contesti multi-file (i provider elencano finestre di contesto da 256k negli adattatori del marketplace).
- Ragionamento visibile / tracce: le risposte possono includere tracce di ragionamento graduale volte a rendere le decisioni dell'agente ispezionabili e sottoponibili a debug.
Dettagli tecnici
Architettura e formazione: xAI afferma che grok-code-fast-1 è stato sviluppato da zero con una nuova architettura e un corpus di pre-addestramento ricco di contenuti di programmazione; il modello è stato poi sottoposto a una selezione post-addestramento su set di dati di pull request/codice reali di alta qualità. Questa pipeline di progettazione è mirata a rendere il modello pratico all'interno dei flussi di lavoro agentici (utilizzo di IDE + strumenti).
Servizio e contesto: grok-code-fast-1 e i modelli di utilizzo tipici presuppongono output in streaming, chiamate di funzione e iniezione di contesto avanzato (caricamenti/raccolte di file). Diversi marketplace cloud e adattatori di piattaforma lo elencano già con un ampio supporto di contesto (256k contesti in alcuni adattatori).
Caratteristiche di usabilità: Visibile tracce di ragionamento (il modello illustra l'utilizzo della pianificazione/degli strumenti), la guida di progettazione rapida e le integrazioni di esempio, nonché le integrazioni dei partner di lancio anticipato (ad esempio, GitHub Copilot, Cursor).
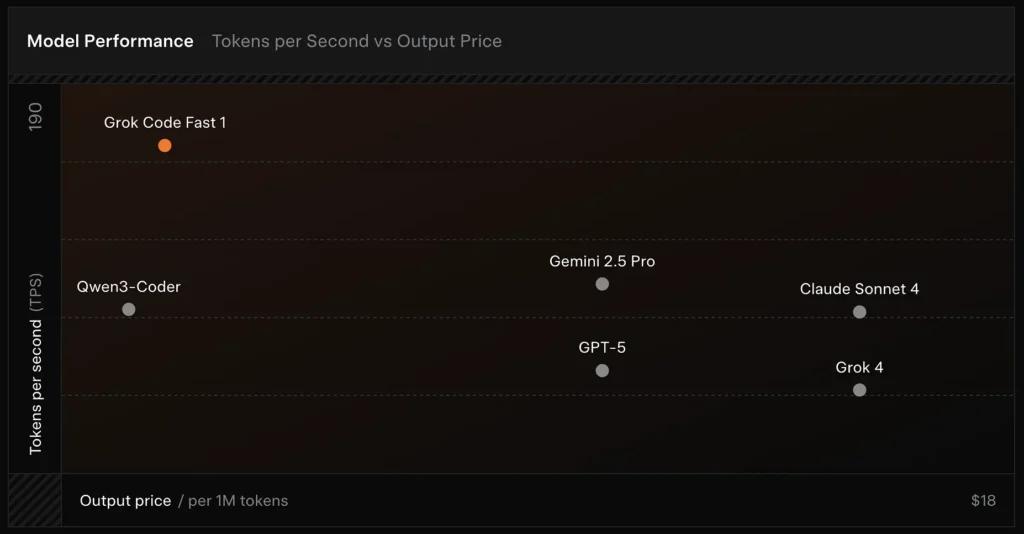
Prestazioni di riferimento (su quale punteggio si basa)
SWE-Bench-Verificato: xAI segnala un 70.8% punteggio sul loro cablaggio interno rispetto al sottoinsieme SWE-Bench-Verified, un benchmark comunemente utilizzato per i confronti dei modelli di ingegneria del software. Una recente valutazione pratica ha riportato un valutazione umana media ≈ 7.6 su una suite di codifica mista, competitiva con alcuni modelli di alto valore (ad esempio, Gemini 2.5 Pro), ma in ritardo rispetto a modelli multimodali/"best-reasoner" più grandi come Claude Opus 4 e Grok 4 di xAI su compiti di ragionamento ad alta difficoltà. I benchmark mostrano anche una varianza per compito: eccellente per la correzione di bug comuni e la generazione di codice conciso, più debole su alcuni problemi di nicchia o specifici della libreria (esempio Tailwind CSS).
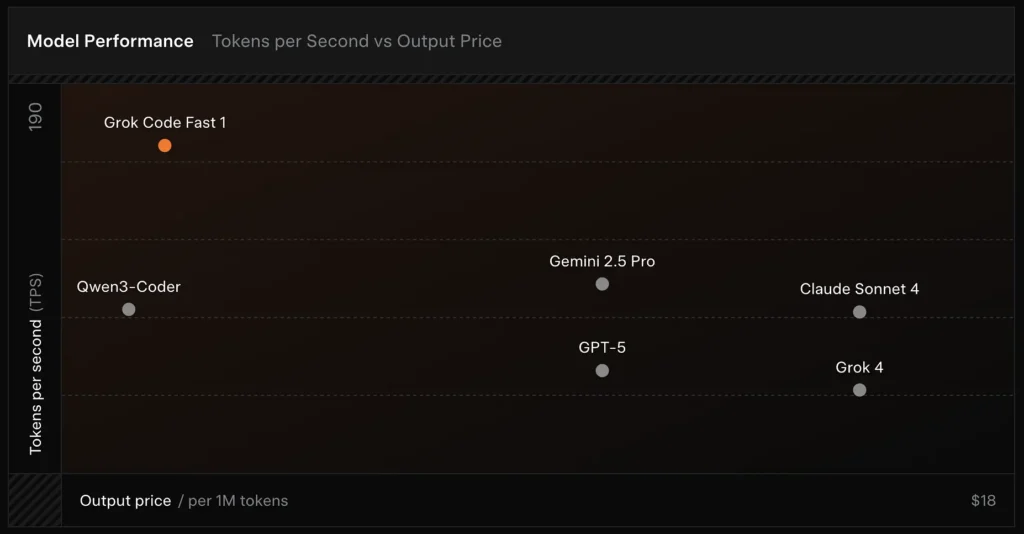
Confronto:
- contro Grok 4: Grok-code-fast-1 scambia una certa correttezza assoluta e un ragionamento più profondo per costi molto più bassi e produttività più rapida; Grok 4 rimane l'opzione con capacità più elevate.
- vs Claude Opus / classe GPT: Questi modelli spesso sono indicati per compiti complessi, creativi o di ragionamento difficile; Grok-code-fast-1 compete bene per compiti di sviluppo di routine e ad alto volume, in cui la latenza e i costi sono importanti.
Limitazioni e rischi
Limitazioni pratiche osservate finora:
- Lacune di dominio: cali di prestazioni su librerie di nicchia o problemi insoliti (ad esempio casi limite di Tailwind CSS).
- Compromesso tra costi del token di ragionamento: poiché il modello può emettere token di ragionamento interno, un ragionamento altamente agentivo/prolisso può aumentare la lunghezza (e il costo) dell'output di inferenza.
- Precisione / casi limite: pur essendo efficace nelle attività di routine, Grok-code-fast-1 può allucinazioni o produrre codice errato per nuovi algoritmi o dichiarazioni di problemi avversari; potrebbe avere prestazioni inferiori rispetto ai modelli incentrati sul ragionamento più avanzati su benchmark algoritmici impegnativi.
casi d'uso tipici
- Assistenza IDE e prototipazione rapida: completamenti rapidi, scritture di codice incrementali e debug interattivo.
- Agenti automatizzati/flussi di lavoro del codice: agenti che orchestrano i test, eseguono comandi e modificano i file (ad esempio, helper CI, revisori bot).
- Attività ingegneristiche quotidiane: generazione di scheletri di codice, refactoring, suggerimenti per la selezione dei bug e impalcature di progetti multi-file in cui la bassa latenza migliora notevolmente il flusso degli sviluppatori.
Come chiamare l'API grok-code-fast-1 da CometAPI
grok-code-fast-1 Prezzi API in CometAPI: sconto del 20% sul prezzo ufficiale:
- Token di input: $0.16/M token
- Token di output: $2.0/M di token
Passi richiesti
- Accedere cometapi.comSe non sei ancora un nostro utente, registrati prima
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.
Usa il metodo
- Selezionare l'opzione "
grok-code-fast-1"endpoint" per inviare la richiesta API e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per vostra comodità. - Sostituire con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo contenuto: il modello risponderà a questa domanda.
- Elaborare la risposta API per ottenere la risposta generata.
CometAPI fornisce un'API REST completamente compatibile, per una migrazione senza interruzioni. Dettagli chiave per Documento API:
- URL di base: https://api.cometapi.com/v1/chat/completions
- Nomi dei modelli: "
grok-code-fast-1" - Autenticazione: Token portatore tramite
Authorization: Bearer YOUR_CometAPI_API_KEYtestata - Tipo di contenuto:
application/json.
Integrazione API ed esempi
Frammento di Python per un Completamento chat chiamata tramite CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Vedere anche Grok4