

GLM-5 è il nuovo modello di base open-weight di Zhipu AI, incentrato sugli agenti, progettato per coding a lungo orizzonte e agenti multi-step. È disponibile tramite diverse API ospitate (inclusi CometAPI e endpoint dei provider) e come release di ricerca con codice e pesi; puoi integrarlo usando chiamate REST compatibili con OpenAI, streaming e SDK.
Che cos’è GLM-5 di Z.ai?
GLM-5 è il modello di base di punta di quinta generazione di Z.ai, progettato per l’ingegneria agentica: pianificazione a lungo orizzonte, uso di strumenti in più passaggi e progettazione di codice/sistemi su larga scala. Pubblicato pubblicamente a febbraio 2026, GLM-5 è un modello Mixture-of-Experts (MoE) con ~744 miliardi di parametri totali e un set di parametri attivi nell’ordine di 40B per passaggio in avanti; le scelte di architettura e addestramento danno priorità alla coerenza su contesti lunghi, al tool-calling e a un’inferenza a costi contenuti per carichi di produzione. Queste scelte consentono a GLM-5 di eseguire workflow agentici estesi (per esempio: browse → pianifica → scrivi/testa codice → itera) preservando il contesto su input molto lunghi.
Punti salienti tecnici:
- Architettura MoE a ~744B totali / ~40B parametri attivi; pretraining scalato (~28.5T token riportati) per ridurre il divario con i modelli chiusi di frontiera.
- Supporto per contesti lunghi e ottimizzazioni (deep sparse attention, DSA) per ridurre i costi di deploy rispetto al semplice scaling denso.
- Funzionalità agentiche integrate: tool/function calling, supporto a sessioni stateful e output integrati (capaci di generare artefatti
.docx,.xlsx,.pdfcome parte dei workflow agentici nelle UI dei vendor). - Disponibilità open-weights (pesi pubblicati sui model hub) e opzioni di accesso hosted (API dei vendor, microservizi di inferenza).
Quali sono i principali vantaggi di GLM-5?
Pianificazione agentica e memoria di lungo periodo
L’architettura e la calibrazione di GLM-5 danno priorità a un ragionamento multi-step coerente e alla memoria lungo il workflow — un vantaggio per:
- agenti autonomi (pipeline CI, orchestratori di task),
- generazione o refactoring di codice su più file, e
- document intelligence che necessita di mantenere storici estesi.
Finestre di contesto ampie
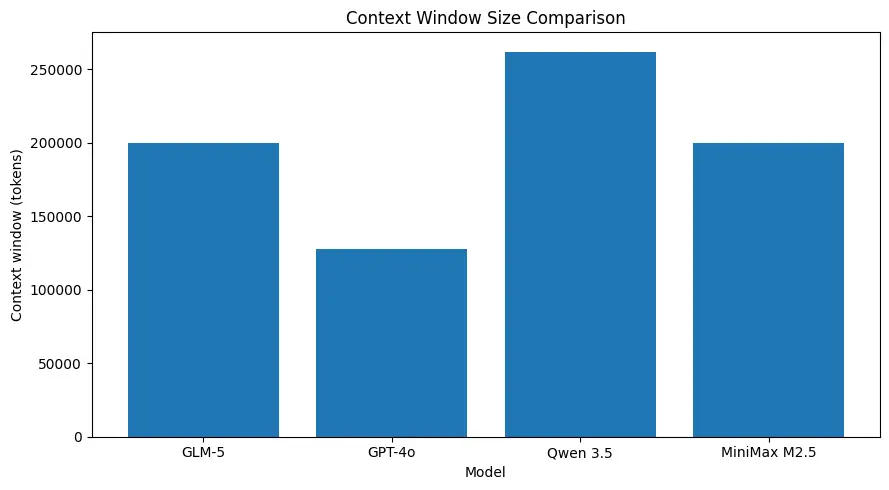
GLM-5 supporta dimensioni di contesto molto grandi (nell’ordine di ~200k token nelle specifiche pubblicate), consentendo di mantenere più contenuto di una sessione in una singola richiesta e riducendo la necessità di chunking aggressivo o memoria esterna in molti casi d’uso. (Vedi il grafico di confronto sotto.)
Prestazioni solide nel coding per compiti a livello di sistema
GLM-5 riporta prestazioni ai vertici tra gli open-source su benchmark di ingegneria del software (SWE-bench e suite di codice + agenti applicati). Su SWE-bench-Verified riporta ~77.8%; nei test di agenti stile coding/terminal (Terminal-Bench 2.0) i punteggi si attestano intorno alla metà dei 50 — evidenza di capacità di coding pratico che si avvicina ai modelli proprietari di frontiera. Queste metriche indicano che GLM-5 è adatto a attività come generazione di codice, refactoring automatizzato, ragionamento multi-file e scenari di assistenza CI/CD.
Compromessi tra costo ed efficienza
Poiché GLM-5 utilizza MoE e innovazioni di attenzione “sparsa”, mira a ridurre il costo di inferenza per unità di capacità rispetto allo scaling denso brutale. CometAPI offre prezzi competitivi che rendono GLM-5 interessante per carichi agentici ad alto throughput.
Come usare l’API di GLM-5 tramite CometAPI?
Risposta breve: tratta CometAPI come un gateway compatibile con OpenAI — imposta la URL di base e la API key, seleziona glm-5 come modello, quindi chiama l’endpoint di chat/completions. CometAPI fornisce una superficie REST in stile OpenAI (endpoint come /v1/chat/completions) oltre a SDK e progetti di esempio che rendono la migrazione banale.
Di seguito un vademecum pratico orientato alla produzione: autenticazione, chiamata chat di base, streaming, function/tool calling e gestione di costi/risposte.
I passaggi di base per accedere a GLM-5 via CometAPI sono:
- Registrati su CometAPI, ottieni una API key.
- Trova l’id di modello esatto per GLM-5 nel catalogo di CometAPI (
"glm-5"a seconda della lista). - Invia una richiesta POST autenticata all’endpoint chat/completions di CometAPI (stile OpenAI).
Dettagli base (pattern CometAPI): la piattaforma supporta percorsi in stile OpenAI come https://api.cometapi.com/v1/chat/completions, autenticazione Bearer, parametro model, messaggi system/user, streaming, e sia esempi curl sia python nella documentazione.
Esempio: chat completion rapida in Python (requests) con GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Esempio: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Risposte in streaming (pattern pratico)
CometAPI supporta lo streaming in stile OpenAI (SSE/chunked). L’approccio più semplice in Python è impostare "stream": true e iterare sui dati di risposta man mano che arrivano. Questo è importante quando servono output parziali a bassa latenza (assistant di sviluppo in tempo reale, UI in streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Riferimento: documentazione sullo streaming in stile OpenAI e sulla compatibilità di CometAPI.
Function / tool calling (come invocare uno strumento esterno)
GLM-5 supporta pattern di function/tool calling compatibili con le convenzioni OpenAI/aggregatori (il gateway passa chiamate di funzione strutturate nella risposta del modello). Esempio d’uso: chiedi a GLM-5 di chiamare lo strumento locale “run_tests”; il modello restituisce un’istruzione strutturata che puoi analizzare ed eseguire.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Quando il modello restituisce un payload function_call, esegui lo strumento lato server, quindi reinvia il risultato dello strumento come messaggio con ruolo "tool" e riprendi la conversazione. Questo pattern abilita invocazioni di strumenti sicure e flussi agentici stateful. Consulta la documentazione e gli esempi di CometAPI per helper SDK concreti.
Parametri pratici e tuning
function_call: usa per abilitare invocazioni strutturate degli strumenti e flussi di esecuzione più sicuri.
temperature: 0–0.3 per output deterministici a livello di sistema (codice, infrastruttura), più alto per ideazione.
max_tokens: imposta in base alla lunghezza attesa dell’output; GLM-5 supporta output molto lunghi quando ospitato (i limiti del vendor variano).
top_p / nucleus sampling: utile per limitare le code poco probabili.
stream: true per UI interattive.
Confronto tra GLM-5, Claude Opus di Anthropic e altri modelli di frontiera
Risposta breve: GLM-5 riduce il divario con i modelli chiusi di frontiera nei benchmark agentici e di coding, offrendo al contempo deployment open-weights e spesso un costo per token migliore quando è ospitato da aggregatori. La sfumatura: su alcuni benchmark di coding assoluto (SWE-bench, varianti di Terminal-Bench) Claude Opus (4.5/4.6) mantiene un vantaggio di pochi punti in molte classifiche pubblicate — ma GLM-5 è altamente competitivo e supera molti altri modelli open.
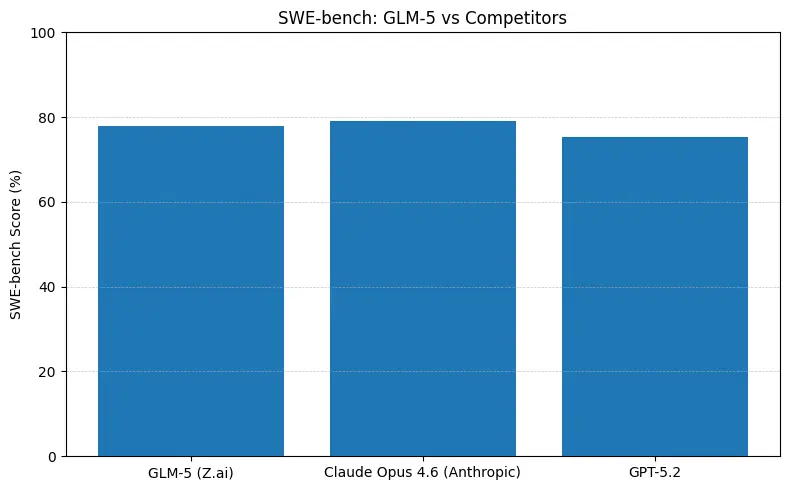
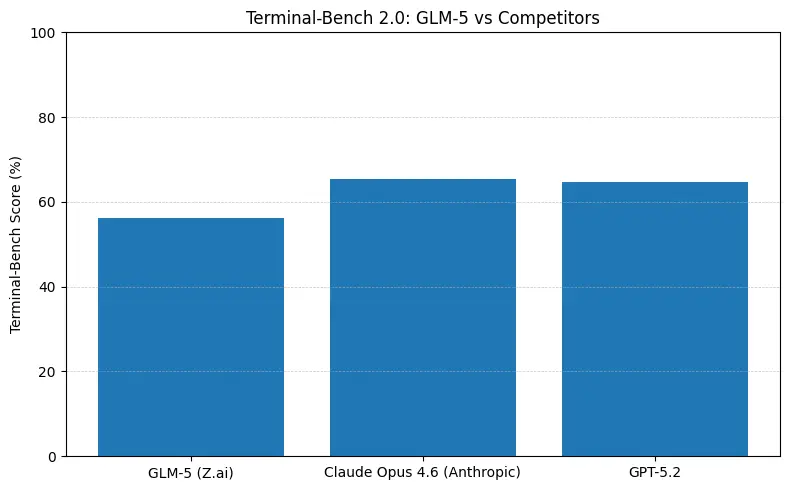
Cosa significano i numeri nella pratica
- SWE-bench (~correttezza del codice / ingegneria): Claude Opus mostra un vantaggio marginale (≈79% vs GLM-5 ≈77.8%) nelle classifiche pubblicate; per molti compiti reali quel divario si tradurrà in meno modifiche manuali, ma non necessariamente in una scelta architetturale diversa per prototipi o workflow agentici su scala.
- Terminal-Bench (task agentici da linea di comando): Opus 4.6 è in testa (≈65.4% vs GLM-5 ≈56.2%) — se ti serve un’automazione terminale robusta e la massima affidabilità su operazioni shell fuori distribuzione, Opus è spesso migliore al margine.
- Agentici e lungo orizzonte: GLM-5 performa molto bene nelle simulazioni di business a lungo orizzonte (Vending-Bench 2 saldo $4,432 riportato) e mostra forte coerenza di pianificazione per workflow multi-step. Se il tuo prodotto è un agente a lunga esecuzione (finanza, operations), GLM-5 è una scelta solida.
Come progettare prompt e sistemi per ottenere output affidabili da GLM-5?
Messaggi di sistema e vincoli espliciti
Assegna a GLM-5 un ruolo rigoroso e vincoli espliciti, specialmente per compiti di codice o tool-calling. Esempio:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Richiedi test e una breve motivazione per ogni modifica non banale.
Scomponi i task complessi
Invece di “scrivere l’intero prodotto”, chiedi:
- schema di progettazione,
- firme delle interfacce,
- implementazione e test,
- script di integrazione finale.
Questa scomposizione per fasi riduce le allucinazioni e fornisce checkpoint deterministici che puoi validare.
Usa temperature basse per codice deterministico
Quando richiedi codice, imposta temperature = 0–0.2 e max_tokens a un limite superiore prudente. Per scrittura creativa o brainstorming di design, aumenta la temperatura.
Best practice per integrare GLM-5 (tramite CometAPI o host diretti)
Prompt engineering e prompt di sistema
- Usa istruzioni di sistema esplicite che definiscano ruoli degli agenti, politiche di accesso agli strumenti e vincoli di sicurezza. Esempio: “Sei un system architect: proponi modifiche solo quando i test unitari passano localmente; elenca i comandi CLI esatti da eseguire.”
- Per compiti di coding, fornisci contesto del repository (lista file, snippet chiave) e allega output dei test unitari se disponibili. La gestione del contesto esteso di GLM-5 aiuta — ma mantieni sempre il contesto essenziale per primo (ruolo, task) poi gli artefatti di supporto.
Gestione di sessione e stato
- Usa ID di sessione per conversazioni agentiche lunghe e mantieni una “memoria” compatta dei passi precedenti (sommari) per evitare gonfiore del contesto. CometAPI e gateway simili offrono helper per sessione/stato — ma la compattazione dello stato a livello applicativo è essenziale per agenti di lunga durata.
Strumenti e function calls (sicurezza + affidabilità)
- Esponi un set di strumenti ristretto e verificabile. Non consentire esecuzione shell arbitraria senza supervisione umana. Usa definizioni di funzione strutturate e valida gli argomenti lato server.
- Registra sempre le chiamate agli strumenti e le risposte del modello per tracciabilità e debugging post-mortem.
Controllo dei costi e batching
- Per agenti ad alto volume, instrada l’elaborazione in background a varianti di modello più economiche quando i compromessi qualitativi sono accettabili (CometAPI permette di cambiare modello per nome). Esegui batch di richieste simili e riduci
max_tokensdove possibile. Monitora il rapporto token input vs output — i token di output sono spesso più costosi.
Engineering di latenza e throughput
- Usa lo streaming per sessioni interattive. Per job agentici in background, preferisci runtime asincroni, code di worker e rate-limiter. Se fai self-hosting (open weights), ottimizza la topologia degli acceleratori per l’architettura MoE — opzioni FPGA/Ascend/silicio specializzato possono portare vantaggi di costo.
Note finali
GLM-5 rappresenta un passo pratico, open-weight, verso l’ingegneria agentica: finestre di contesto ampie, capacità di pianificazione e solide prestazioni di coding lo rendono interessante per strumenti per sviluppatori, orchestrazione di agenti e automazione a livello di sistema. Usa CometAPI per un’integrazione rapida o un model garden cloud per hosting gestito; valida sempre sul tuo carico e strumenta in modo esteso per controllo di costi e allucinazioni.
Gli sviluppatori possono accedere a GLM-5 tramite CometAPI già ora. Per iniziare, esplora le capacità del modello nel Playground e consulta la API guide per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato il login su CometAPI e di aver ottenuto la API key. CometAPI offre un prezzo molto inferiore a quello ufficiale per aiutarti nell’integrazione.
Pronti a partire?→ Iscriviti a M2.5 oggi
Se vuoi conoscere altri suggerimenti, guide e novità sull’AI, seguici su VK, X e Discord!