Luma AI è diventato uno degli strumenti più discussi nella creazione di contenuti per consumatori e prosumer: un'app e un servizio cloud che converte foto e video dello smartphone in NeRF 3D fotorealistici e, tramite i suoi modelli Dream Machine / Ray2, genera immagini e brevi video da prompt di testo o immagini. Ma la velocità è una delle prime domande pratiche che i creatori si pongono: quanto tempo richiederà effettivamente un'acquisizione, un rendering o la generazione di un video?
Quanto tempo impiega Luma AI a generare una clip Dream Machine (testo → video)?
Tempi di riferimento ufficiali
Le pagine prodotto e l'hub di apprendimento di Luma forniscono tempi di base rapidi per le pipeline di generazione di immagini e video brevi: i batch di immagini vengono misurati in decine di secondi e i processi di video brevi in pochi secondi o minuti, in condizioni normali per utenti a pagamento e benchmark interni. Queste metriche ufficiali riflettono esecuzioni di modelli ottimizzate sull'infrastruttura di Luma (stack Ray2 / Dream Machine) e rappresentano i valori ottimali per clip di piccole dimensioni e di breve durata.
Intervalli reali che dovresti aspettarti
Casi limite / livello libero o carico di picco: gli utenti gratuiti o i periodi di forte richiesta hanno prodotto attese di ore o lavori "bloccati in coda" finché non si libera capacità; i thread della community documentano attese di diverse ore durante i periodi di punta o le interruzioni. Se la bassa latenza è fondamentale, considerate questa variabilità e valutate opzioni a pagamento/prioritarie.
Brevi clip social (5–15 sec): in molti casi, il solo passaggio di generazione può essere completato in da meno di un minuto a pochi minuti per gli utenti paganti durante il carico normale, ma il tempo totale di elaborazione può essere più lungo se si includono le fasi di messa in coda, pre-elaborazione e streaming/esportazione.
Clip più dettagliate o più lunghe (20–60 sec): questi possono prendere da diversi minuti a decine di minuti, in particolare se si richiede una risoluzione più elevata, movimenti di telecamera complessi o perfezionamenti iterativi. Recensioni di terze parti e account utente segnalano tempi tipici nel 5-30 minuti banda per video brevi più complessi.
Quanto tempo impiega Luma AI per produrre una cattura 3D (cattura NeRF / Genie / Telefono)?
Flussi di lavoro tipici di acquisizione 3D e relativi profili temporali
Gli strumenti di acquisizione 3D di Luma (l'app di acquisizione mobile + funzionalità simili a Genie) trasformano una serie di foto o un video registrato in un modello 3D o in una mesh texturizzata simile a NeRF. A differenza delle brevi clip di Dream Machine, la ricostruzione 3D è più complessa: deve acquisire molti fotogrammi, stimare le pose della telecamera, ottimizzare la geometria volumetrica e sintetizzare le texture. Tutorial pubblici e guide pratiche ne parlano. tempi di elaborazione reali da diversi minuti fino a diverse ore, a seconda della lunghezza e della qualità della cattura. Un esempio di tutorial comunemente citato ha mostrato 30 minuti a un'ora per una cattura moderata; altri tipi di cattura (lunghe passeggiate, fotogrammi ad alta risoluzione) possono richiedere più tempo.
Intervalli rappresentativi
- Scansioni rapide di oggetti/prodotti (20–80 foto, acquisizione breve): da pochi minuti a ~30 minuti.
- Catture a livello di stanza o walk-through (da centinaia a migliaia di fotogrammi): 30 minuti a diverse ore, a seconda delle dimensioni dell'input e della fedeltà dell'esportazione finale.
- Esportazioni ad alta fedeltà per motori di gioco (mesh, texture ad alta risoluzione): aggiungere tempo extra per la generazione della mesh, la retopologia e la cottura: questo può spingere i lavori nel ore.
Perché il 3D richiede più tempo dei video brevi
La ricostruzione 3D è iterativa e richiede un'ottimizzazione intensiva: il modello perfeziona i campi volumetrici e le previsioni delle texture su più fotogrammi, il che richiede un elevato impegno computazionale. Il backend di Luma parallelizza gran parte di questo lavoro, ma la scala di calcolo per ogni processo rimane superiore a quella di una singola generazione di un breve video.
Quali sono i principali fattori che influenzano il tempo di elaborazione di Luma AI?
Scelta del modello e della pipeline (Ray2, Photon, Genie, Modify Video)
Diversi modelli e funzionalità di Luma sono progettati per raggiungere compromessi diversi: Ray2 e Dream Machine danno priorità alla generazione di video fotorealistici con feedback interattivo a bassa latenza, mentre Photon e Genie sono ottimizzati per il miglioramento delle immagini o la ricostruzione 3D e potrebbero essere più pesanti per progettazione. La scelta di un modello con impostazioni di fedeltà più elevate aumenterà il tempo di elaborazione. La documentazione ufficiale e l'API descrivono diversi endpoint del modello e flag di qualità che influiscono sul runtime.
Dimensione e complessità dell'input
- Numero di fotogrammi/foto: più input = più passaggi di ottimizzazione.
- Risoluzione: risoluzioni di output e input ad alta risoluzione aumentano i tempi di elaborazione.
- Lunghezza della clip richiesta: le clip più lunghe richiedono più controlli di rendering e coerenza del movimento.
Livello dell'account, coda e priorità
Gli abbonamenti a pagamento e i clienti aziendali/API spesso ricevono priorità o limiti di tariffazione più elevati. Gli utenti del piano gratuito riscontrano solitamente tempi di attesa più lunghi quando il sistema è sotto sforzo. I report della community lo confermano: i piani a pagamento generalmente riducono i tempi di attesa e migliorano la produttività.
Carico di sistema e ora del giorno
I thread degli utenti reali mostrano che i tempi di generazione possono aumentare durante le ore di punta o quando il lancio di funzionalità importanti innesca picchi di richieste. Il team di Luma aggiorna costantemente l'infrastruttura (vedere i changelog) per gestire la capacità, ma si verificano comunque ritardi temporanei.
Tempo di caricamento/rete e dispositivo client
Per i flussi di lavoro di acquisizione, la velocità di caricamento e le prestazioni del dispositivo sono importanti: i caricamenti di grandi dimensioni, che richiedono molti gigabyte, aumentano i tempi di elaborazione prima ancora che inizi. La documentazione di Luma indica le dimensioni massime dei file e consiglia le migliori pratiche di acquisizione per ridurre al minimo il trasferimento di dati non necessari.
Come posso stimare in anticipo i tempi di lavoro e ridurre l'attesa?
Lista di controllo per una stima rapida
- Classifica il tuo lavoro: immagine, video breve (<15 s), video più lungo (>15 s) o acquisizione 3D.
- Conta gli input: numero di foto / durata del video (secondi) / dimensione del file di acquisizione.
- Decidi la qualità: bassa, standard o alta fedeltà — maggiore fedeltà = elaborazione più lunga.
- Controlla il livello dell'account: gratuito vs a pagamento vs aziendale; considerare la probabile coda.
- Esegui un breve test: creare un lavoro di test di 5-10 secondi per raccogliere una base di riferimento reale.
Consigli pratici per accelerare la produttività
- Utilizzare i modelli di cattura consigliati (movimento fluido della telecamera, illuminazione uniforme) per una ricostruzione più rapida. L'hub di apprendimento e le pagine dell'app mobile di Luma forniscono le migliori pratiche di acquisizione.
- Ridurre le dimensioni di input dove accettabile: ritagliare, ridurre il campionamento o rifinire il filmato prima del caricamento per ridurre i tempi e i costi di elaborazione.
- Scegli preset di qualità inferiore per le bozze, quindi finalizza ad alta qualità solo quando sei soddisfatto della composizione.
- Pianifica corse intense fuori orario di punta se possibile; i resoconti della comunità indicano che le code diminuiscono al di fuori degli orari di punta.
- Considerare le opzioni API/aziendali Se hai bisogno di scalabilità e SLA prevedibili, l'API e il registro delle modifiche di Luma mostrano investimenti continui nelle prestazioni e nuovi endpoint come Modify Video per semplificare i flussi di lavoro.
Come si confrontano i numeri di temporizzazione di Luma con quelli di altri strumenti?
Confrontare servizi di immagini/video generativi o servizi NeRF è complesso perché ogni fornitore ottimizza per diversi compromessi (qualità vs velocità vs costo). Per la generazione di immagini e video molto brevi, la Dream Machine di Luma, in particolare con Ray2 Flash, compete con una latenza interattiva inferiore al minuto, in linea con i principali servizi generativi rivolti al consumatore. Per l'acquisizione NeRF di scene complete e la creazione di modelli 3D ad alta fedeltà, le esigenze di cloud computing e i tempi di coda sono superiori rispetto ai generatori di immagini rapidi: aspettatevi una maggiore varianza e pianificate di conseguenza. La documentazione dei partner e le descrizioni di terze parti indicano comunemente minuti per rendering brevi e semplici e ore (o imprevedibilmente più lunghe) per pipeline 3D complesse.
Verdetto finale: quanto tempo ci vorrà? andrete a Luma prende per my lavoro?
Non esiste un numero unico che si adatti a ogni utente o a ogni lavoro. Utilizza questi punti di riferimento pratici per stimare:
- Generazione di immagini (Dream Machine): ~20–30 secondi per piccolo lotto con carico normale.
- Generazione di brevi video (Dream Machine / Ray2): da decine di secondi a pochi minuti per clip brevi; Ray2 Flash può essere significativamente più veloce sui flussi supportati.
- Cattura 3D → NeRF: altamente variabile. Caso migliore: minuti per un piccolo oggetto e calcolo leggero; caso peggiore (segnalato): Da molte ore a giorni interi in caso di forte domanda o per acquisizioni di grandi dimensioni. Se hai bisogno di tempistiche precise, acquista piani prioritari/aziendali o esegui test pilota di pre-produzione e inserisci un buffer time pianificato nella tua pianificazione.
Iniziamo
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
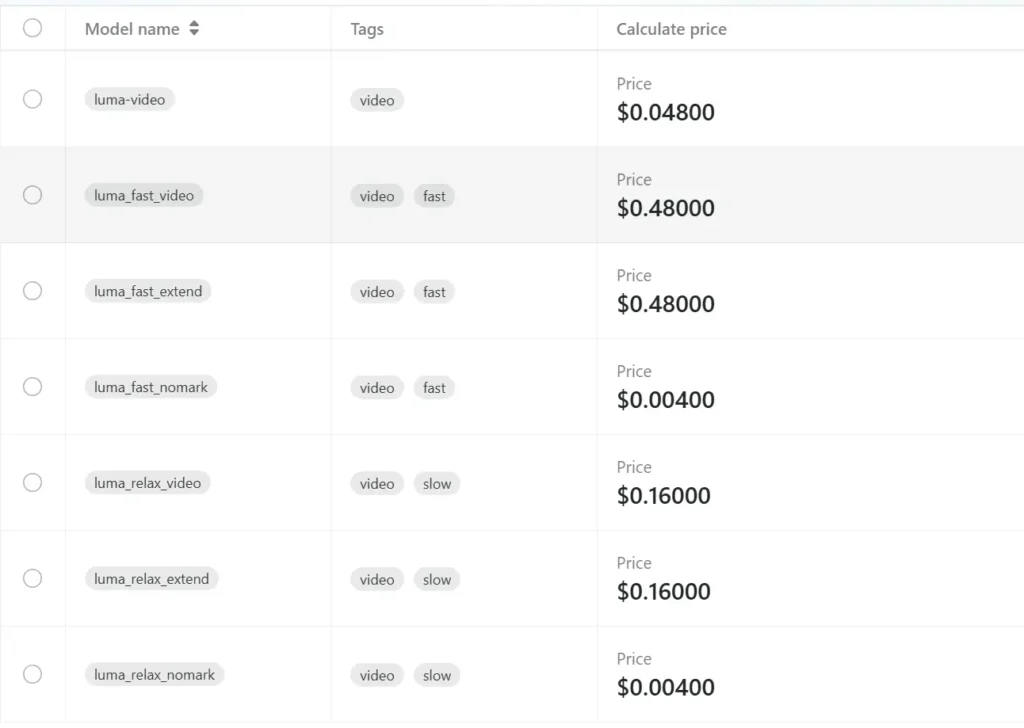
Gli sviluppatori possono accedere API di Luma attraverso CometaAPI, le ultime versioni dei modelli elencate sono quelle aggiornate alla data di pubblicazione dell'articolo. Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrare: