

Sonetto 4.5 di Claude di Anthropic (spesso abbreviato in Sonnet 4.5) è arrivato come successore incentrato sulle prestazioni nella famiglia Claude di Anthropic. Per i team che decidono se adottare Claude Sonnet 4.5 per chatbot, assistenti di programmazione o agenti autonomi di lunga durata, il costo è un fattore chiave, e non è solo il prezzo di listino per token a fare la differenza, ma anche come si implementa il modello, quali funzionalità di risparmio si utilizzano e con quali modelli della concorrenza lo si confronta.
Che cos'è Claude Sonnet 4.5 e perché utilizzarlo?
Claude Sonnet 4.5 è l'ultimo modello di punta della famiglia Sonnet di Anthropic, ottimizzato per flussi di lavoro agentici a lungo termine, programmazione e ragionamento complesso multi-step. Anthropic posiziona Claude Sonnet 4.5 come un modello "di frontiera" con un'ampia finestra di contesto e miglioramenti nell'esecuzione prolungata delle attività, nell'editing del codice e nel ragionamento di dominio rispetto alle precedenti versioni di Sonnet.
Caratteristiche tecniche e di utilizzo notevoli
- Prestazioni estese a lungo contesto — progettato per mantenere un lavoro coerente in più fasi (Anthropic cita casi di utilizzo di lavoro continuo di più ore).
- Primitive di modifica e di esecuzione del codice migliorate — funzionalità per i checkpoint, esecuzione del codice in alcune integrazioni e migliore precisione di modifica rispetto ai precedenti modelli Sonnet/Opu.
- Miglioramento del ragionamento, della codifica e delle prestazioni agentiche: Anthropic evidenzia esecuzioni autonome continue più lunghe e un comportamento più affidabile per flussi di lavoro multifase.
- Progettato per un utilizzo in contesti prolungati (le varianti di Sonnet sono solitamente destinate a grandi finestre di contesto applicabili a basi di codice e flussi di lavoro multi-documento), con miglioramenti a livello di sistema e misure di sicurezza.
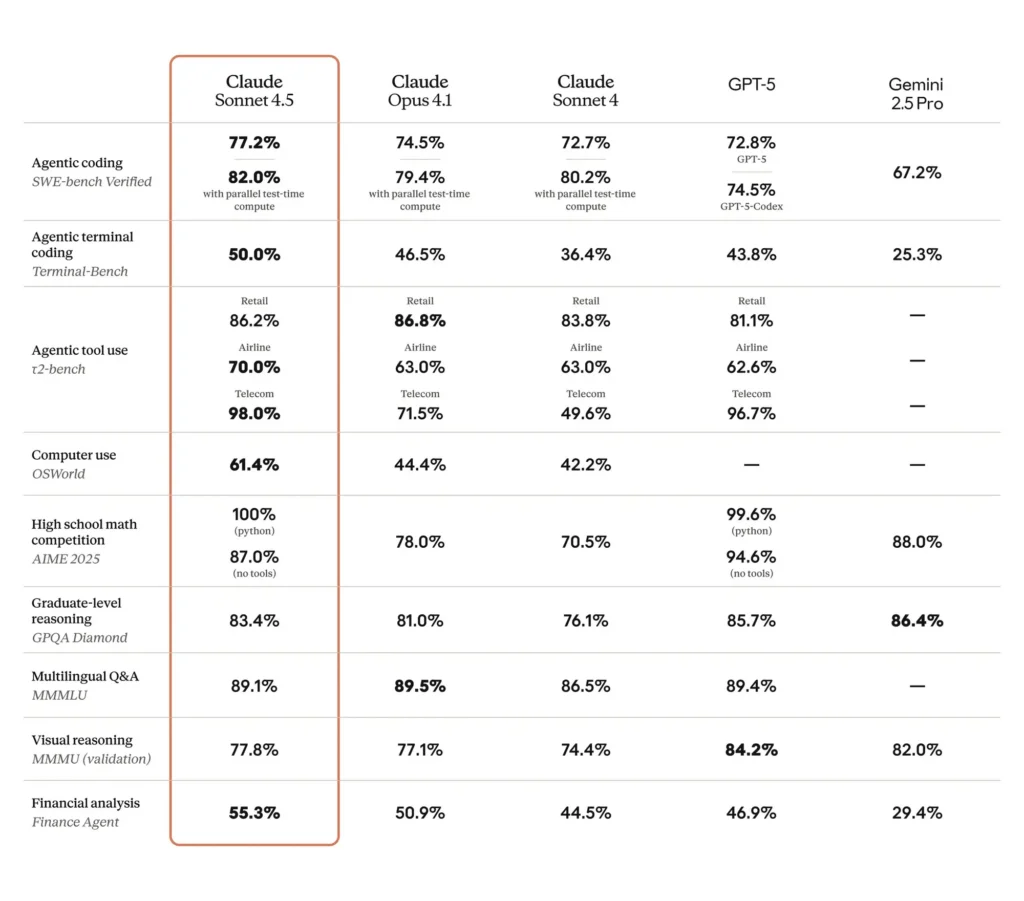
*Miglioramento delle prestazioni di “utilizzo del computer” e di codifica
Se il tuo prodotto o il tuo team necessita di uno o più dei seguenti elementi, Claude Sonnet 4.5 è specificamente progettato per essere avvincente:
- Esecuzioni lunghe e con stato dell'agente (creatori di app autonomi, sintesi di codice di più ore o test automatizzati).
- Modifica e refactoring del codice di alta qualità — Anthropic segnala miglioramenti diretti nei tassi di errore di modifica del codice interno rispetto alle versioni precedenti di Sonnet.
- Ragionamento complesso e lavoro di dominio in finanza, diritto, medicina e STEM, dove un contesto più lungo e un minor numero di “promemoria” aumentano la produttività e riducono l’orchestrazione manuale.
Qual è il prezzo per utilizzare Claude 4.5 tramite l'app Claude?
Quali sono i livelli di abbonamento per i consumatori (web/mobile)?
I livelli consumer di Anthropic sono ancora così strutturati (pagine dei prezzi pubblici e documentazione back-end):
- Gratis — utile per un uso occasionale; capacità di elaborazione dei messaggi/utilizzo limitata.
- Pro — $ 20/mese con fatturazione mensile (scontati a circa $ 17/mese con fatturazione annuale), pensati per utenti esperti e con funzionalità di produttività avanzate. La versione Pro aumenta i limiti di sessione/utilizzo (circa ~5 volte gratuito durante le fasce orarie di punta).
- Piano massimo — Anthropic ha annunciato i piani "Max" con un utilizzo più elevato (100 $/mese per un utilizzo di circa 5 volte superiore a Pro, 200 $/mese per un utilizzo di circa 20 volte superiore a Pro) per utenti esperti/professionali che necessitano di un utilizzo intenso e prolungato senza ricorrere a soluzioni di acquisizione aziendali. Questi piani sono espressamente pensati per chi altrimenti raggiungerebbe il limite massimo di sessioni di Pro.
Quante ore/messaggi si acquistano con un abbonamento?
Pro gli utenti possono aspettarsi qualcosa di simile ~45 messaggi ogni cinque ore o ~40–80 ore di utilizzo settimanale di Sonnet a seconda del carico di lavoro; Max I livelli aumentano notevolmente (Max 5x e 20x danno incrementi proporzionali). Si tratta di bande di approssimazione: il consumo effettivo dipende dalla lunghezza del prompt, dalle dimensioni degli allegati, dalle scelte del modello (Sonnet vs Opus vs Haiku) e da funzionalità come Claude Code.
Quali sono i dettagli sui prezzi dell'API per Claude Sonnet 4.5?
Come viene misurata la fatturazione API?
Utilizzo API fatture antropiche da parte di token e separa token di input (ciò che invii) da token di output (ciò che restituisce il modello). Per Claude Sonnet 4.5 i tassi di base pubblicati da Anthropic sono:
- Input (API standard): $ 3.00 per 1,000,000 di token di input.
- Output (API standard): $ 15.00 per 1,000,000 di token di output.
Quali sconti o modalità alternative esistono?
- API batch (elaborazione asincrona in massa) comporta un ~50% di sconto nei documenti di Anthropic — comunemente rappresentato come $ 1.50 / M di input e al $7.50 / M di produzione per modelli Sonnet in modalità batch. Batch è ideale per grandi carichi di lavoro offline come l'analisi della base di codice o la sintesi in blocco.
- Memorizzazione nella cache dei prompt può produrre fino a risparmi effettivi molto grandi quando si richiamano ripetutamente prompt identici. Utilizzare la memorizzazione nella cache per prompt ripetitivi dell'assistente o piani agente in cui si ripete lo stesso prompt iniziale.
- canali di terze parti: CometaAPI offre uno sconto del 20% sull'API ufficiale e dispone di una versione API del cursore appositamente adattata: Token di input (prompt) is $ 2.4 per 1,000,000 (1 milione) di token di input; Token di output (generazione): $ 12 per 1,000,000 (1 milione) di token in uscita.
Nota: "memorizzazione nella cache dei prompt" ed "elaborazione batch" sono modelli di implementazione che riducono l'elaborazione ripetuta su prompt identici e ammortizzano il lavoro su più chiamate. L'entità del risparmio dipende interamente dai modelli di carico di lavoro dell'applicazione.
Come si confrontano i costi delle opzioni di abbonamento e API?
Dipende interamente da profilo di utilizzo:
- Da produttività umana interattiva (scrittura, ricerca, assistenza occasionale al codice) Pro or Max Gli abbonamenti spesso offrono il miglior rapporto qualità/prezzo perché combinano capacità, funzionalità dell'app e limiti di sessione più elevati a un canone mensile prevedibile. La versione Pro di Anthropic è pensata per scrittori e piccoli team; la versione Max si rivolge ai professionisti che necessitano di molte più ore e richieste al mese.
- Da programmatico, ad alto volume o per transazione utilizzo (webhook, funzionalità del prodotto che richiamano il modello migliaia/milioni di volte al giorno), API Il pagamento in base al consumo è solitamente la scelta corretta: i costi aumentano con i token e puoi utilizzare prezzi in batch e memorizzazione nella cache per ridurre i token fatturabili.
Regola pratica empirica
Se la tua fattura API mensile prevista (a $ 3/$ 15 per M) sarebbe sostanzialmente più costoso rispetto allo slot Pro/Max di cui hai bisogno (dopo aver convertito le ore/messaggi previsti in token), acquista un abbonamento o un piano aziendale. Al contrario, se il tuo prodotto necessita di chiamate programmatiche dettagliate, l'API è l'unica opzione praticabile.
Claude Sonnet 4.5 — Costi stimati per scenario applicativo
Di seguito sono riportati alcuni esempi pratici, stime dei costi mensili praticabili per Claude Sonnet 4.5 in scenari applicativi tipici (generazione di testo, codice, RAG, agenti, riepilogo di documenti lunghi, ecc.). Ogni scenario mostra le ipotesi (token per chiamata e chiamate/mese), il base costo mensile utilizzando le tariffe pubblicate da Anthropic ($3 / 1 milione di token di input, $15 / 1 milione di token di output), e due viste di ottimizzazione comuni: a partita sconto (50% di sconto sulle tariffe simboliche) e memorizzazione nella cache dei prompt Esempi (70% di cache hit e 90% di cache hit). Questi sconti/vantaggi sono supportati dalla documentazione di Anthropic (risparmio di circa il 50% per la memorizzazione nella cache batch e prompt fino a circa il 90%).
Quali sono le regole di calcolo e le ipotesi?
- 1,000,000 di token è l'unità di fatturazione.
- Costo mensile = (totale_token_input / 1,000,000) × tasso_input + (totale_token_output / 1,000,000) × tasso_output.
- Riporto tre colonne di costo: Tavola XY, Lotto (sconto del 50%), Caching (due ipotesi rappresentative di cache hit: il 70% e il 90% delle chiamate servite dalla cache).
- È prodotto in modelli di stima — le fatture effettive varieranno in base alla qualità del cache hit, alle dimensioni esatte dei prompt, alla lunghezza delle risposte e a eventuali sconti negoziati o margini di partner/cloud.
Di seguito sono riportati 9 scenari. Per ciascuno di essi elenco: chiamate/mese, token di input medi (prompt/contesto) e token di output medi (risposta modello), quindi totali mensili e costi.
Guida approssimativa dal simbolo alla parola: 1,000 token ≈ 750–900 parole a seconda della lingua e della formattazione.
1) Contenuti brevi (schemi di blog, post sui social)
Ipotesi: 1,000 chiamate/mese; 200 token di input/chiamata; 1,200 token di output/chiamata.
Totale: 200,000 token di input; 1,200,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Base (senza sconti) | $18.60 |
| Batch (tasso token del 50%) | $9.30 |
| 70% di cache hit (fatturato solo il 30%) | $5.58 |
| 90% di cache hit (fatturato solo il 10%) | $1.86 |
Quando questo si adatta: Piccoli creatori e agenzie che generano molti pezzi brevi. Memorizzare nella cache prompt predefiniti (ad esempio, modelli con struttura fissa) ha un impatto elevato.
2) Generazione di articoli di formato lungo (output multipagina)
Ipotesi: 200 chiamate/mese; 500 token di input; 5,000 token di output.
Totale: 100,000 token di input; 1,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $15.30 |
| Partita | $7.65 |
| Cache 70% | $4.59 |
| Cache 90% | $1.53 |
Quando questo si adatta: punti vendita che producono articoli lunghi; utilizzare batch per la generazione di massa programmata e cache per i modelli ripetuti. Poiché i token di output prevalgono in questo caso, la velocità di output per token di Sonnet è importante, ma questi costi sono modesti per volumi di articoli da bassi a moderati. Per produzioni elevate (centinaia-migliaia di articoli lunghi al mese), la produzione in lotti e un'attenta troncatura riducono comunque significativamente i costi.
3) Chatbot di supporto clienti (implementazione di medie dimensioni)
Ipotesi: 30,000 sessioni/mese; 600 token di input; 800 token di output.
Totale: 18,000,000 token di input; 24,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $387.00 |
| Partita | $193.50 |
| Cache 70% | $116.10 |
| Cache 90% | $38.70 |
Quando questo si adatta: Supporto conversazionale per app di medie dimensioni: il recupero di informazioni/RAG e la memorizzazione nella cache delle risposte predefinite riducono drasticamente i costi. Per i chatbot, i token di output di solito determinano i costiRidurre la verbosità (risposte mirate) e utilizzare lo streaming/interruzione anticipata può essere d'aiuto. La memorizzazione nella cache è utile solo se le stesse richieste vengono ripetute.
4) Assistente al codice (integrazioni IDE, modifiche e correzioni)
Ipotesi: 10,000 chiamate/mese; 1,200 token di input; 800 token di output.
Totale: 12,000,000 token di input; 8,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $258.00 |
| Partita | $129.00 |
| Cache 70% | $77.40 |
| Cache 90% | $25.80 |
Quando questo si adatta: Assistenza per ogni modifica all'interno di un IDE. Valutare l'indirizzamento delle attività di lint/formattazione a modelli più leggeri e l'escalation a Claude Sonnet 4.5 per le modifiche al codice di maggiore valore. Riutilizzare prompt e modelli di sistema con memorizzazione nella cache quando si richiamano prompt simili per la generazione di codice, per ridurre i costi di input.
5) Riepilogo dei documenti: documenti lunghi (legali/finanziari)
Ipotesi: 200 chiamate/mese; 150,000 token di input (inclusi documenti/chunking di grandi dimensioni); 5,000 token di output.
Totale: 30,000,000 token di input; 1,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Base (≤200k input → tariffe standard) | $615.00 |
| Partita | $307.50 |
| Cache 70% | $184.50 |
| Cache 90% | $61.50 |
Importante: questo esempio mantiene l'input per chiamata ≤200k quindi si applicano le tariffe standardSe il tuo input per chiamata supera i 200k token, contesto lungo si applicano i prezzi (vedere lo scenario successivo).
6) Revisione di documenti molto lunghi (>200k token per richiesta → velocità di contesto lunghe)
Ipotesi: 20 chiamate/mese; 600,000 token di input / chiamata; 20,000 token di output / chiamata.
Totale: 12,000,000 token di input; 400,000 token di output.
Poiché l'input per richiesta è > 200k, si applicano le tariffe premium a lungo termine di Anthropic (ad esempio: $ 6/1M di input e $ 22.50/1M di output utilizzati qui).
| Vista dei costi (tariffe a lungo termine) | Costo mensile |
|---|---|
| Base di contesto lungo | $81.00 |
| (Per il confronto con le tariffe standard se il contesto lungo non è addebitato) | $42.00 |
Quando questo si adatta: Analisi a chiamata singola di set di prove o raccolte di dati estremamente estesi. Utilizzare tecniche di chunking + recupero e RAG per evitare, ove possibile, costi aggiuntivi per chiamata con contesto lungo.
7) RAG / Q&A aziendale (QPS molto elevato)
Ipotesi: 1,000,000 chiamate/mese; 400 token di input; 200 token di output.
Totale: 400,000,000 token di input; 200,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $3,300.00 |
| Partita | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
Quando questo si adatta: Controllo qualità di documenti di grandi volumi. RAG + prefiltraggio + cache locali riducono drasticamente le chiamate che devono raggiungere Claude Sonnet 4.5.
8) Automazione agentica (agenti continui, molti turni)
Ipotesi: 50,000 sessioni agente/mese; 2,000 token di input; 4,000 token di output.
Totale: 100,000,000 token di input; 200,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $3,300.00 |
| Partita | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
Quando questo si adatta: Agenti in background che eseguono molti passaggi. L'architettura è importante: comprimere lo stato, riassumere la cronologia e memorizzare nella cache i prompt secondari ripetuti per controllare i costi.
9) Traduzione in batch (lavori in batch di grandi dimensioni)
Ipotesi: 500 lavori batch/mese; 50,000 token di input; 50,000 token di output.
Totale: 25,000,000 token di input; 25,000,000 token di output.
| Vista dei costi | Costo mensile |
|---|---|
| Tavola XY | $450.00 |
| Partita | $225.00 |
| Cache 70% | $135.00 |
| Cache 90% | $45.00 |
Quando questo si adatta: elaborazione in blocco programmata: l'API batch è la leva più importante in questo caso.
Come si confronta il prezzo del Claude Sonnet 4.5 con quello degli altri modelli più diffusi?
Confronto prezzo token (visualizzazione semplice)
- Sonetto 4.5 di Claude: $3 / 1M di input, $15 / 1M di output (API standard).
- OpenAI GPT-4o (esempi segnalati): circa $2.50 / 1M di input, $10 / 1M di output.
- OpenAI GPT-5 (esempio di prezzo pubblico per la sua ammiraglia): circa $1.25 / 1M di input, $10 / 1M di output (Prezzi API pubblicati da OpenAI al momento del lancio di GPT-5).
Interpretazione: Il costo di output di Sonnet è sostanzialmente più alto rispetto ai prezzi di output di alcuni prodotti di punta di OpenAI, ma Sonnet mira a compensare questo con una migliore efficienza agentica (meno passaggi avanti e indietro perché può mantenere un contesto più lungo e fare di più internamente) e le opzioni di caching/batch di Anthropic possono ridurre significativamente i costi effettivi per i prompt ripetuti.
La capacità per dollaro è importante
Se Claude Sonnet 4.5 può completare un'attività di agente di più ore in meno chiamate API o generare output più compatti e corretti che non necessitano di post-elaborazione, costo reale (ore di progettazione + commissioni API) potrebbero essere inferiori nonostante un tasso di output per token più elevato. I costi di riferimento dovrebbero essere calcolati per flusso di lavoro, non per token.
Quali strategie di ottimizzazione dei costi funzionano meglio con Claude Sonnet 4.5?
1) Sfruttare in modo aggressivo la memorizzazione nella cache dei prompt
Anthropic pubblicizza fino a 90% Risparmio per prompt ripetuti. Se la tua app invia spesso gli stessi prompt di sistema o istruzioni ripetute, la memorizzazione nella cache riduce drasticamente l'elaborazione dei token. Implementa livelli di memorizzazione nella cache prima dell'API per evitare di inviare nuovamente prompt invariati. ()
2) Richieste in batch ove possibile
Per l'elaborazione dei dati o l'inferenza multi-elemento, raggruppa più elementi in un'unica chiamata API. Anthropic e altri fornitori segnalano risparmi sostanziali per le modalità batch: l'entità del risparmio dipende dal modo in cui il fornitore addebita il calcolo in batch. ()
3) Ridurre proattivamente il volume dei token di output
- Utilizzare impostazioni più rigorose per il numero massimo di token e chiedere ai modelli di essere concisi laddove accettabile.
- Per i flussi di interfaccia utente, inviate risposte parziali o riepiloghi anziché output completi e dettagliati. Poiché il prezzo dell'output di Sonnet è il fattore di costo maggiore, ridurre i token generati comporta risparmi considerevoli.
4) Selezione del modello e routing
- Indirizzare le attività di estrazione o di basso valore verso modelli più economici (o varianti Claude più piccole) e riservare Sonnet 4.5 per il lavoro di codice/agente di importanza critica.
- Per le attività in background, valutare varianti "mini" più piccole o modelli Claude più vecchi.
5) Memorizza nella cache gli output generati per le query ripetute
Se gli utenti richiedono spesso la stessa risposta (ad esempio, descrizioni di prodotti, frammenti di policy), memorizza nella cache l'output del modello e fornisci risposte memorizzate nella cache anziché rigenerarle.
6) Utilizzare incorporamenti + recupero per ridurre le dimensioni del prompt
Memorizza i documenti lunghi in un database vettoriale e recupera solo i frammenti più rilevanti da includere nei prompt: in questo modo si riducono i token di input e si mantiene il contesto preciso.
Come chiamare l'API di Claude Sonnet in modo più economico?
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Gli sviluppatori possono accedere Claude Sonetto 4.5 API tramite CometAPI, l'ultima versione del modello è sempre aggiornato con il sito ufficiale. Per iniziare, esplora le capacità del modello nel Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Conclusione
Claude Sonnet 4.5 è un modello ad alta capacità, ideale per attività lunghe, agentive e di codifica. Il prezzo di listino API pubblicato da Anthropic per Sonnet 4.5 è di circa $ 3 per milione di token di input e $ 15 per milione di token di output, con meccanismi di caching e batch che spesso dimezzano o più i costi effettivi per il carico di lavoro corretto. I livelli di abbonamento (Pro, Max) e le offerte aziendali offrono modi alternativi per acquistare capacità per carichi di lavoro interattivi o molto pesanti. Quando si pianifica l'adozione, è consigliabile misurare i token per flusso di lavoro, testare Sonnet sui flussi più complessi e utilizzare il caching rapido, l'elaborazione batch e la selezione del modello per ottimizzare il rapporto costi-efficacia.