

L'azienda cinese Z.ai (ex Zhipu AI) è tornata a far parlare di sé con il lancio della sua serie GLM 4.5 open source. Posizionata come un'alternativa economica e ad alte prestazioni ai grandi modelli linguistici esistenti, GLM-4.5 promette di rimodellare l'economia dei token e democratizzare l'accesso per startup, imprese e istituti di ricerca. Questo articolo completo esplora le origini, la struttura dei prezzi e il valore reale della serie GLM-4.5, rispondendo alle due domande chiave che ogni stakeholder si pone: quanto costa e ne vale la pena?
Che cos'è la serie GLM 4.5?
La serie GLM 4.5 di Z.ai si basa su un framework di intelligenza artificiale "agentica", il che significa che il modello può scomporre autonomamente attività complesse in sottoattività più piccole e sequenziali, migliorando la precisione e riducendo i calcoli ridondanti. Questo è in contrasto con i LLM più monolitici che gestiscono i prompt in un unico passaggio. Secondo Z.ai, GLM 4.5 integra nativamente il ragionamento e la pianificazione delle azioni nella sua architettura di base, consentendo flussi di lavoro multifase come la generazione di visualizzazioni di dati o l'elaborazione end-to-end di documenti senza orchestrazione esterna.
La serie GLM 4.5, sviluppata da Z.ai, rappresenta l'ultima generazione di modelli linguistici di grandi dimensioni open source, basati su Mixture-of-Experts (MoE), progettati per unificare ragionamento avanzato, generazione di codice e capacità agentiche in un'unica architettura. È disponibile in due versioni principali: la versione di punta GLM 4.5 (355 B parametri totali, 32 B attivi) e il più leggero GLM 4.5‑Air (106 B totali, 12 B attivi). Entrambe le varianti sfruttano un meccanismo di inferenza ibrido: "modalità di pensiero" per ragionamenti complessi basati su strumenti e "modalità non di pensiero" per completamenti rapidi e semplici, adattandosi a un ampio spettro di casi d'uso, dallo sviluppo full-stack ai flussi di lavoro degli agenti autonomi.
specifiche tecniche principali:
- Scheda Sintetica: GLM 4.5 è dotato di 355 miliardi di parametri, con un sottoinsieme attivo di 32 miliardi impegnato per inferenza per ottimizzare l'utilizzo dell'hardware e la produttività.
- Mix di esperti (MoE): La serie sfrutta l'architettura MoE, instradando i token verso sottoreti esperte in modo dinamico per garantire l'efficienza.
- Finestra di contesto: Esteso a 128 K token su piattaforme selezionate (ad esempio, SiliconFlow), per supportare documenti e basi di codice di grandi dimensioni.
- Velocità di generazione: Le varianti ad alta velocità superano i 100 token/sec, adatte per applicazioni in tempo reale.
- Modalità di inferenza ibrida: Gli utenti possono alternare tra la modalità "pensiero" (attivazione completa del MoE per un ragionamento approfondito) e la modalità "non pensiero" (attivazione minima per risposte rapide e immediate), garantendo agli sviluppatori un controllo preciso sulle prestazioni rispetto alla velocità.
Quali varianti esistono all'interno della serie?
- GLM 4.5 (Standard): 355 B totali / 32 B parametri attivi. Progettato principalmente per prestazioni bilanciate tra attività di ragionamento, codifica e agenti.
- GLM 4.5‑Air: Una versione leggera da 106 B totali / 12 B di parametri attivi, pensata per scenari con vincoli hardware o di latenza rigorosi, che offre una precisione competitiva nella sua categoria.
Quanto costa la serie GLM 4.5?
Quali sono i prezzi dei token di input e di output?
Secondo le informazioni pubbliche sui prezzi dell'API di Z.ai, il prezzo di GLM 4.5 è:
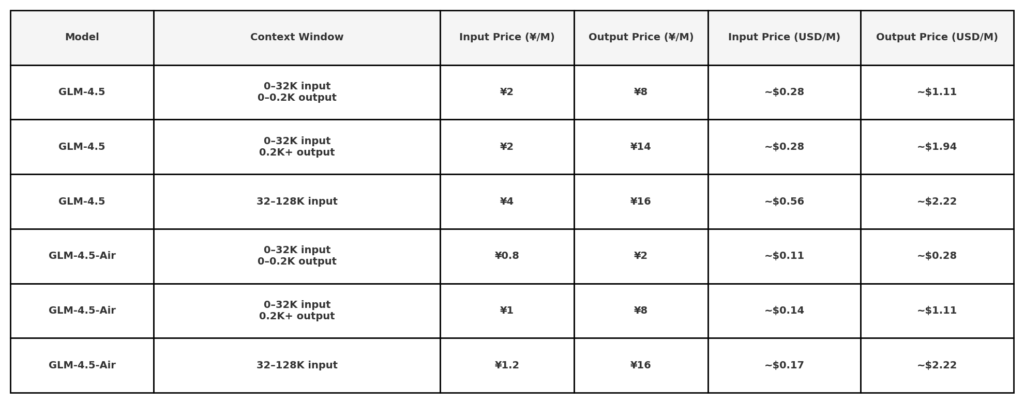
Nota: le tariffe molto basse ($ 0.11/$ 0.28) potrebbero essere limitate a piccole durate di token o promozioni specifiche. Sconto del 50% su tutti i modelli per un periodo limitato, valido fino al 31 agosto 2025. Altri modelli si riferiscono a pagina dei prezzi dell'ufficio.
Su CometAPI, la serie è offerta con prezzi a livelli leggermente diversi, fare riferimento a API GLM‑4.5:
| Modello | introdurre | Prezzo |
glm-4.5 | Il nostro modello di ragionamento più potente, con 355 miliardi di parametri | Gettoni di input $0.48 Gettoni di output $1.92 |
glm-4.5-air | Conveniente Leggero Prestazioni elevate | Gettoni di input $0.16 Gettoni di output $1.07 |
glm-4.5-x | Alte prestazioni, ragionamento forte, risposta ultraveloce | Gettoni di input $1.60 Gettoni di output $6.40 |
glm-4.5-airx | Leggero, potente, con risposta ultraveloce | Gettoni di input $0.02 Gettoni di output $0.06 |
glm-4.5-flash | Prestazioni elevate, eccellenti per ragionamento, codifica e agenti | Gettoni di input $3.20 Gettoni di output $12.80 |
Come si confrontano i prezzi di GLM 4.5 con quelli di DeepSeek e Western LLM?
Alla World AI Conference del 2025, Z.ai ha posizionato esplicitamente GLM 4.5 come sfidante di DeepSeek, il precedente leader di costo in Cina, promettendo "una frazione del costo del token" e la metà dell'ingombro hardware del modello R1 di DeepSeek.
- DeepSeek R1: Circa 0.14 USD in input, 0.60 USD in output per milione di token.
- GLM 4.5: Si sostiene che offra prestazioni inferiori a quelle di DeepSeek del 20-30% sia in input che in output.
- Punti di riferimento occidentali: GPT-4 di OpenAI e Gemini di Google variano da 3 a 15 USD per milione di token, posizionando GLM 4.5 come una riduzione dei costi di un ordine di grandezza.
Questa strategia di prezzo riflette il più ampio modello economico cinese basato sull'intelligenza artificiale: elaborazione più snella, modelli più piccoli e prezzi competitivi per conquistare quote di mercato.
La serie GLM 4.5 vale la pena?
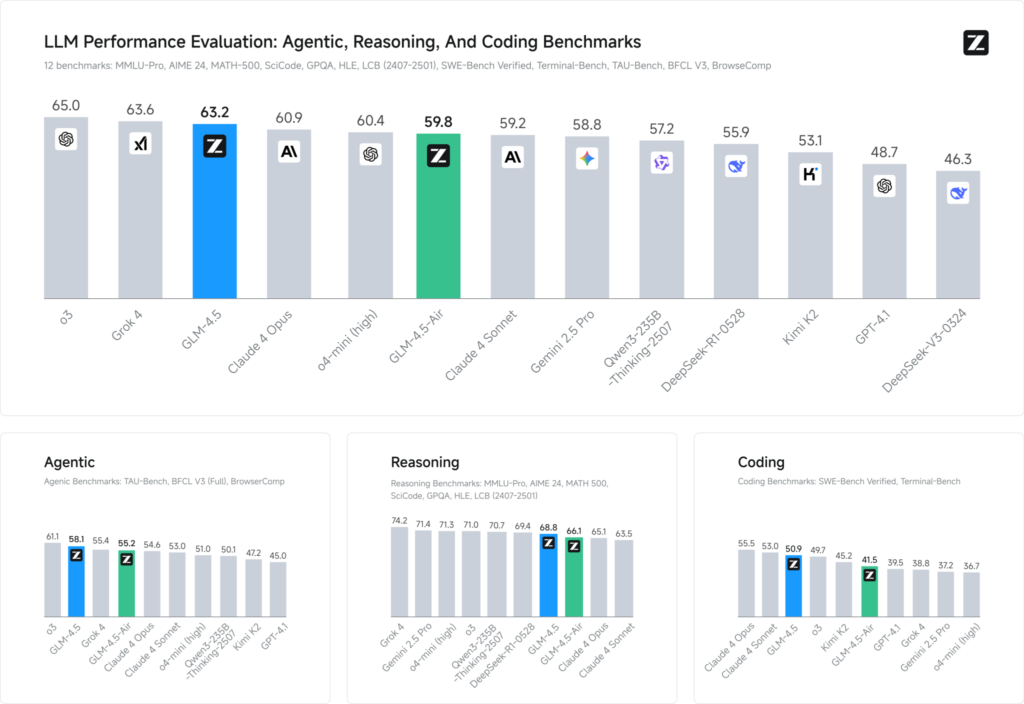
Le valutazioni di riferimento su 12 set di dati rappresentativi (che comprendono MMLU Pro, MATH 500, SciCode, Terminal-Bench e TAU-Bench) rivelano che GLM 4.5 si aggiudica il terzo posto a livello mondiale dietro Grok 3 di xAI e o4 di OpenAI, ma si classifica al primo posto tra le offerte open source.
Nelle attività di codifica (LiveCodeBench, SWE-Bench), il design Mixture-of-Experts di GLM 4.5 contribuisce a una qualità di generazione del codice di altissimo livello, mentre nel ragionamento (AIME 24, MMLU Pro) la sua pianificazione multi-step garantisce un'accuratezza robusta, paragonabile a quella delle controparti closed-source. La variante leggera Air mantiene punteggi competitivi all'interno della sua fascia di parametri (scala 100 B), rendendola una scelta allettante per implementazioni edge e sistemi embedded.
Benchmark delle prestazioni
- Indice di intelligenza: Punteggi GLM 4.5 66 su un indice di intelligenza composito (MMLU Pro, MATH 500, AIME 24), superando molti modelli open source e commerciali di fascia media.
- Latenza di inferenza: Medie del tempo per il primo token 0.89 secondi, competitivo per compiti di ragionamento complessi, sebbene leggermente più lento in termini di produttività (≈45.7 token/s) rispetto ad alcuni modelli closed-source ottimizzati.
- Flusso di lavoro agente: Dimostra una solida padronanza dell'uso di strumenti multi-step e della generazione dinamica di codice, con percentuali di vittoria testa a testa di ~54% contro Kimi K2 e al 81% contro Qwen3‑Coder nelle valutazioni di codifica indipendenti.
Quali casi d'uso pratici mostrano il ROI?
- Sviluppo full-stack: GLM‑4.5 può supportare intere applicazioni web, dai layout frontend in HTML/CSS/JavaScript agli schemi di database backend, tramite prompt multi-turn, riducendo i cicli di prototipazione da giorni a ore.
- Analisi di documenti complessi: La finestra di contesto estesa da 128 K consente agli studi legali, finanziari e scientifici di analizzare contratti o report di ricerca composti da più pagine in un'unica operazione, riducendo il sovraccarico di segmentazione.
- Flussi di lavoro automatizzati degli agenti: L'inferenza ibrida consente la creazione di script autonomi (ad esempio, bot di web scraping, agenti di trading) che ragionano attraverso processi multifase con un intervento umano minimo.
Studi di casi quantitativi suggeriscono fino a 60 percento riduzione delle ore di sviluppo per attività incentrate sul codice e 40 percento tempi di risposta più rapidi per l'analisi dei contenuti di lunga durata.
Quali sono i potenziali svantaggi e le considerazioni?
Nessuna tecnologia è esente da compromessi. I potenziali utilizzatori dovrebbero tenere conto dei fattori normativi, operativi ed ecosistemici.
Limiti
Supporto e SLA: A differenza delle controparti commerciali, i provider open source potrebbero non offrire SLA di livello aziendale o supporto 24 ore su 7, XNUMX giorni su XNUMX.
Vincoli di produttività: Sebbene la finestra di contesto sia enorme, le velocità dei token al secondo sono inferiori a quelle di alcune controparti closed-source ottimizzate per l'inferenza, il che potrebbe influire sulle applicazioni in tempo reale.
Spese generali operative: I modelli MoE self-hosting richiedono un'orchestrazione attenta (routing esperto, gestione della memoria) per evitare colli di bottiglia nelle prestazioni e sforamenti dei costi.
Quali investimenti infrastrutturali sono necessari?
- Impronta di calcolo: Anche con l'efficienza MoE, l'hosting della variante standard di GLM-4.5 richiede GPU con ≥80 GB di memoria e interconnessioni NVLink robuste per l'inferenza a bassa latenza.
- Overhead di messa a punto fine: La personalizzazione del modello per attività specifiche del dominio potrebbe richiedere cicli GPU sostanziali, con conseguente aumento dei costi iniziali prima che si concretizzino i risparmi sulla fatturazione tramite token.
- Manutenzione: Le distribuzioni on-premise spostano la responsabilità degli aggiornamenti, delle patch di sicurezza e del ridimensionamento dal fornitore ai team DevOps interni.
Come puoi iniziare a usare GLM‑4.5?
Per avviare l'integrazione GLM-4.5 sono necessari alcuni semplici passaggi, soprattutto considerando il manuale open source e l'ampio supporto di terze parti.
Quali API e piattaforme supportano GLM‑4.5?
- CometaAPI API: Endpoint completamente compatibile con OpenAI, dotato di SDK in Python, JavaScript e Java.
- Endpoint diretto Z.ai: Offre supporto ufficiale e funzionalità di accesso anticipato come l'orchestrazione multi-agente.
- Specchi della comunità: Numero crescente di runtime open source (ad esempio Ollama, AutoGPT-CLI) che consentono l'inferenza locale.
Dove possono trovare gli sviluppatori strumenti e documentazione?
- Documentazione ufficiale di Z.ai: Guide complete sull'installazione, sulla progettazione rapida e sull'ottimizzazione MoE.
- Repository GitHub: Notebook di esempio per la generazione di codice, la generazione con recupero aumentato (RAG) e framework di agenti compatibili con i principali strumenti di orchestrazione.
- Forum della comunità: Forum di discussione attivi su piattaforme come Hugging Face, dove i professionisti condividono ricette di perfezionamento, librerie di prompt e benchmark delle prestazioni.
Conclusione
La serie GLM-4.5 rappresenta un'audace rivendicazione nell'attuale panorama ipercompetitivo dell'intelligenza artificiale: un rapporto costo-prestazioni senza pari per sviluppatori, aziende e istituti di ricerca. Con un prezzo dei token a partire da 0.11 $ per milione di token in input e 0.28 $ per milione di token in output, ulteriormente ridotto da uno sconto promozionale del 50%, e prestazioni di riferimento che rivaleggiano o superano modelli proprietari più grandi, GLM-4.5 offre un ROI sostanziale per applicazioni incentrate sul codice, comprensione estesa e flussi di lavoro agentici.
Iniziamo
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Gli sviluppatori possono accedere API aereo GLM-4.5 e al API GLM‑4.5 attraverso CometaAPI, le ultime versioni di Claude Models elencate sono quelle aggiornate alla data di pubblicazione dell'articolo. Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.