

Iniziare con Gemini 2.5 Flash-Lite tramite CometAPI è un'entusiasmante opportunità per sfruttare uno dei modelli di intelligenza artificiale generativa più convenienti e a bassa latenza disponibili oggi. Questa guida combina gli ultimi annunci di Google DeepMind, le specifiche dettagliate della documentazione di Vertex AI e le fasi pratiche di integrazione tramite CometAPI per aiutarti a essere operativo in modo rapido ed efficace.
Cos'è Gemini 2.5 Flash-Lite e perché dovresti prenderlo in considerazione?
Panoramica della famiglia Gemini 2.5
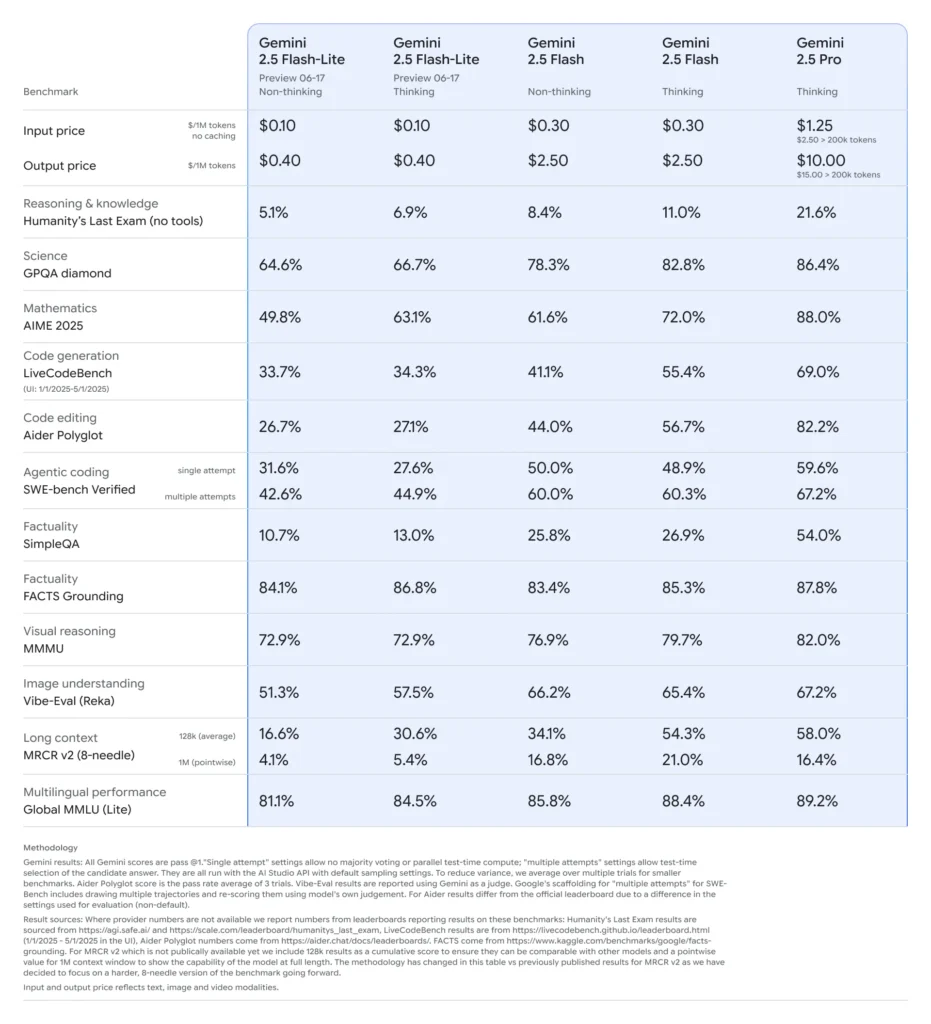
A metà giugno 2025, Google DeepMind ha rilasciato ufficialmente la serie Gemini 2.5, che include le versioni GA stabili di Gemini 2.5 Pro e Gemini 2.5 Flash, insieme all'anteprima di un nuovissimo modello leggero: Gemini 2.5 Flash-Lite. Progettata per bilanciare velocità, costi e prestazioni, la serie 2.5 rappresenta l'impegno di Google per soddisfare un ampio spettro di casi d'uso, dai carichi di lavoro di ricerca più impegnativi alle distribuzioni su larga scala e a basso costo.
Caratteristiche principali di Flash-Lite
Flash-Lite si distingue per offrire funzionalità multimodali (testo, immagini, audio, video) a bassissima latenza, con una finestra di contesto che supporta fino a un milione di token e integrazioni di strumenti, tra cui la Ricerca Google, l'esecuzione di codice e la chiamata di funzioni. Fondamentalmente, Flash-Lite introduce il controllo del "budget di pensiero", consentendo agli sviluppatori di bilanciare la profondità di ragionamento con i tempi di risposta e i costi, regolando un parametro interno di budget dei token.
Posizionamento nella gamma modelli
Rispetto ai suoi simili, Flash-Lite si colloca al limite di Pareto in termini di economicità: con un prezzo di circa 0.10 dollari per milione di token in input e 0.40 dollari per milione di token in output durante l'anteprima, offre un prezzo inferiore sia a Flash (0.30 dollari/2.50 dollari) che a Pro (1.25 dollari/10 dollari), pur mantenendo gran parte delle loro capacità multimodali e del supporto per le chiamate di funzioni. Questo rende Flash-Lite ideale per attività ad alto volume e bassa complessità, come la sintesi, la classificazione e gli agenti conversazionali leggeri.
Perché gli sviluppatori dovrebbero prendere in considerazione Gemini 2.5 Flash-Lite?
Benchmark delle prestazioni e test nel mondo reale
Nei confronti diretti, Flash-Lite ha dimostrato:
- Capacità di elaborazione 2 volte più veloce rispetto a Gemini 2.5 Flash nelle attività di classificazione.
- Risparmio sui costi triplicato per pipeline di riepilogo su scala aziendale.
- Precisione competitiva su benchmark di logica, matematica e codice, corrispondenti o superiori alle precedenti anteprime di Flash-Lite.
Casi d'uso ideali
- Chatbot ad alto volume: Offri esperienze di conversazione coerenti e a bassa latenza a milioni di utenti.
- Generazione automatizzata di contenuti: Riepilogo scalabile dei documenti, traduzione e creazione di microcopie.
- Pipeline di ricerca e raccomandazione: Sfrutta l'inferenza rapida per una personalizzazione in tempo reale.
- Elaborazione dati in batch: Annota grandi set di dati con costi di elaborazione minimi.
Come si ottiene e si gestisce l'accesso API per Gemini 2.5 Flash-Lite tramite CometAPI?
Perché usare CometAPI come gateway?
CometAPI aggrega oltre 500 modelli di intelligenza artificiale, inclusa la serie Gemini di Google, in un endpoint REST unificato, semplificando l'autenticazione, la limitazione della velocità e la fatturazione tra i provider. Invece di destreggiarsi tra più URL di base e chiavi API, è possibile indirizzare tutte le richieste a https://api.cometapi.com/v1, specificare il modello di destinazione nel payload e gestire l'utilizzo tramite un'unica dashboard.
Prerequisiti e registrazione
- Accedere cometapi.comSe non sei ancora un nostro utente, registrati prima
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.
- Ottieni l'URL di questo sito: https://api.cometapi.com/
Gestione dei token e delle quote
La dashboard di CometAPI offre quote di token unificate che possono essere condivise tra Google, OpenAI, Anthropic e altri modelli. Utilizza gli strumenti di monitoraggio integrati per impostare avvisi di utilizzo e limiti di tariffazione, in modo da non superare mai le allocazioni di budget o incorrere in addebiti imprevisti.
Come si configura l'ambiente di sviluppo per l'integrazione di CometAPI?
Installazione delle dipendenze richieste
Per l'integrazione con Python, installa i seguenti pacchetti:
pip install openai requests pillow
- openai: SDK compatibile per la comunicazione con CometAPI.
- richieste: Per operazioni HTTP come il download di immagini.
- cuscino: Per la gestione delle immagini durante l'invio di input multimodali.
Inizializzazione del client CometAPI
Utilizza le variabili di ambiente per mantenere la tua chiave API fuori dal codice sorgente:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Questa istanza client può ora indirizzare qualsiasi modello supportato specificandone l'ID (ad esempio, gemini-2.5-flash-lite-preview-06-17) nelle vostre richieste.
Configurazione del budget di pensiero e di altri parametri
Quando invii una richiesta, puoi includere parametri facoltativi:
- temperatura/top_p: Controlla la casualità nella generazione.
- candidatoConteggio: Numero di uscite alternative.
- max_token: Limite del token di output.
- budget_di_pensiero: Parametro personalizzato per Flash-Lite per bilanciare profondità, velocità e costi.
Come si presenta una richiesta di base a Gemini 2.5 Flash-Lite tramite CometAPI?
Esempio solo testo
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Questa chiamata restituisce un riepilogo sintetico in meno di 200 ms, ideale per chatbot o pipeline di analisi in tempo reale.
Esempio di input multimodale
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite elabora immagini fino a 7 MB e restituisce descrizioni contestuali, rendendolo adatto alla comprensione dei documenti, all'analisi dell'interfaccia utente e alla creazione di report automatizzati.
Come puoi sfruttare funzionalità avanzate come lo streaming e la chiamata di funzioni?
Risposte in streaming per applicazioni in tempo reale
Per le interfacce dei chatbot o i sottotitoli in tempo reale, utilizza l'API di streaming:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
In questo modo vengono forniti output parziali non appena disponibili, riducendo la latenza percepita nelle interfacce utente interattive.
Chiamata di funzione per l'output di dati strutturati
Definire schemi JSON per imporre risposte strutturate:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Questo approccio garantisce output conformi a JSON, semplificando le pipeline di dati a valle e le integrazioni.
Come ottimizzare prestazioni, costi e affidabilità quando si utilizza Gemini 2.5 Flash-Lite?
Ottimizzazione del budget di pensiero
Il parametro "budget di pensiero" di Flash-Lite consente di definire la quantità di "sforzo cognitivo" impiegato dal modello. Un budget basso (ad esempio, 0) privilegia velocità e costi, mentre valori più elevati consentono un ragionamento più approfondito a scapito di latenza e token.
Gestione dei limiti e del throughput dei token
- Gettoni di input: Fino a 1,048,576 token per richiesta.
- Gettoni di uscita: Limite predefinito di 65,536 token.
- Input multimodali: Fino a 500 MB tra risorse di immagini, audio e video.
Implementa il batching lato client per carichi di lavoro ad alto volume e sfrutta il ridimensionamento automatico di CometAPI per gestire il traffico di massa senza intervento manuale.
Strategie di efficienza dei costi
- Raggruppa le attività meno complesse su Flash-Lite, riservando Flash Pro o standard per i lavori più impegnativi.
- Utilizza i limiti di tariffa e gli avvisi di budget nella dashboard CometAPI per evitare spese incontrollabili.
- Monitora l'utilizzo in base all'ID del modello per confrontare i costi per richiesta e adattare di conseguenza la logica di routing.
Quali sono le best practice e i passaggi successivi all'integrazione iniziale?
Monitoraggio, registrazione e sicurezza
- Registrazione: Acquisisci metadati di richiesta/risposta (timestamp, latenze, utilizzo del token) per audit delle prestazioni.
- Avvisi: Imposta notifiche di soglia per tassi di errore o sforamenti di costo in CometAPI.
- Sicurezza : ruotare regolarmente le chiavi API e conservarle in archivi sicuri o variabili di ambiente.
Modelli di utilizzo comuni
- chatbots: Utilizza Flash-Lite per le query rapide degli utenti e passa a Pro per i follow-up più complessi.
- Elaborazione dei documenti: Analisi batch di PDF o immagini durante la notte con un budget ridotto.
- Analisi in tempo reale: Trasmetti in streaming dati finanziari o operativi per ottenere informazioni immediate tramite l'API di streaming.
Esplorando ulteriormente
- Prova la modalità di richiesta ibrida: combina input di testo e immagini per ottenere un contesto più completo.
- Prototipo RAG (Retrieval-Augmented Generation) integrando strumenti di ricerca vettoriale con Gemini 2.5 Flash-Lite.
- Confrontare le offerte dei concorrenti (ad esempio GPT-4.1, Claude Sonnet 4) per convalidare i compromessi tra costi e prestazioni.
Scalabilità in produzione
- Sfrutta il livello enterprise di CometAPI per pool di quote dedicati e garanzie SLA.
- Implementare strategie di distribuzione blue-green per testare nuovi prompt o budget senza interrompere l'attività degli utenti.
- Esaminare regolarmente le metriche di utilizzo del modello per identificare opportunità di ulteriori risparmi sui costi o miglioramenti della qualità.
Iniziamo
CometAPI fornisce un'interfaccia REST unificata che aggrega centinaia di modelli di intelligenza artificiale, sotto un endpoint coerente, con gestione integrata delle chiavi API, quote di utilizzo e dashboard di fatturazione. Invece di dover gestire URL e credenziali di più fornitori.
Gli sviluppatori possono accedere API Gemini 2.5 Flash-Lite (anteprima)(Modello: gemini-2.5-flash-lite-preview-06-17) Attraverso CometaAPI, gli ultimi modelli elencati sono quelli aggiornati alla data di pubblicazione dell'articolo. Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
In pochi passaggi, puoi integrare Gemini 2.5 Flash-Lite nelle tue applicazioni tramite CometAPI, sbloccando una potente combinazione di velocità, convenienza e intelligenza multimodale. Seguendo le linee guida sopra riportate, che riguardano la configurazione, le richieste di base, le funzionalità avanzate e l'ottimizzazione, sarai pronto a offrire ai tuoi utenti esperienze di intelligenza artificiale di nuova generazione. Il futuro dell'intelligenza artificiale economica e ad alta produttività è qui: inizia subito con Gemini 2.5 Flash-Lite.