

Nel 2025-2026, il panorama degli strumenti di intelligenza artificiale ha continuato a consolidarsi: le API gateway (come CometAPI) si sono espanse per fornire un accesso in stile OpenAI a centinaia di modelli, mentre le app LLM per utenti finali (come AnythingLLM) hanno continuato a migliorare il loro provider "Generic OpenAI" per consentire alle app desktop e local-first di chiamare qualsiasi endpoint compatibile con OpenAI. Ciò semplifica oggi l'instradamento del traffico AnythingLLM tramite CometAPI e l'ottenimento dei vantaggi della scelta del modello, del routing dei costi e della fatturazione unificata, continuando a utilizzare l'interfaccia utente locale e le funzionalità RAG/agente di AnythingLLM.
Che cos'è AnythingLLM e perché dovresti collegarlo a CometAPI?
Che cos'è AnythingLLM?
AnythingLLM è un'applicazione di intelligenza artificiale open source e all-in-one, nonché un client locale/cloud per la creazione di assistenti di chat, flussi di lavoro di generazione aumentata dal recupero (RAG) e agenti basati su LLM. Offre un'interfaccia utente intuitiva, un'API per sviluppatori, funzionalità di workspace/agente e supporto per LLM locali e cloud, progettati per essere privati per impostazione predefinita ed estensibili tramite plugin. AnythingLLM espone un OpenAI generico provider che consente di comunicare con le API LLM compatibili con OpenAI.
Che cos'è CometAPI?
CometAPI è una piattaforma commerciale di aggregazione API che espone 500+ modelli di intelligenza artificiale attraverso un'interfaccia REST in stile OpenAI e fatturazione unificata. In pratica, consente di richiamare modelli da più fornitori (OpenAI, Anthropic, varianti Google/Gemini, modelli immagine/audio, ecc.) tramite lo stesso https://api.cometapi.com/v1 endpoint e una singola chiave API (formato sk-xxxxx). CometAPI supporta endpoint standard in stile OpenAI come /v1/chat/completions, /v1/embeddings, ecc., il che semplifica l'adattamento di strumenti che già supportano API compatibili con OpenAI.
Perché integrare AnythingLLM con CometAPI?
Tre motivi pratici:
- Scelta del modello e flessibilità del fornitore: AnythingLLM può utilizzare "qualsiasi LLM compatibile con OpenAI" tramite il suo wrapper OpenAI generico. Puntando tale wrapper a CometAPI si ottiene l'accesso immediato a centinaia di modelli senza modificare l'interfaccia utente o i flussi di AnythingLLM.
- Ottimizzazione costi/operazioni: Utilizzando CometAPI è possibile cambiare modello (o passare a modelli più economici) in modo centralizzato per il controllo dei costi e mantenere una fatturazione unificata anziché dover gestire più chiavi di provider.
- Sperimentazione più rapida: Puoi confrontare diversi modelli A/B (ad esempio,
gpt-4o,gpt-4.5, varianti di Claude o modelli multimodali open source) tramite la stessa interfaccia utente AnythingLLM, utile per agenti, risposte RAG, riepiloghi e attività multimodali.
Ambiente e condizioni che devi preparare prima di integrare
Requisiti di sistema e software (livello alto)
- Desktop o server che esegue AnythingLLM (Windows, macOS, Linux): installazione desktop o istanza self-hosted. Verifica di utilizzare una build recente che esponga Preferenze LLM / Fornitori di intelligenza artificiale e socievole.
- Account CometAPI e una chiave API (il
sk-xxxxxsegreto di stile). Utilizzerai questo segreto nel provider OpenAI generico di AnythingLLM. - Connettività di rete dalla tua macchina a
https://api.cometapi.com(nessun firewall che blocca l'HTTPS in uscita). - Facoltativo ma consigliato: un ambiente Python o Node moderno per i test (Python 3.10+ o Node 18+), curl e un client HTTP (Postman / HTTPie) per verificare l'integrità di CometAPI prima di collegarlo ad AnythingLLM.
Qualsiasi condizione specifica dell'LLM
. OpenAI generico Il provider LLM è il percorso consigliato per gli endpoint che imitano la superficie API di OpenAI. La documentazione di AnythingLLM avverte che questo provider è incentrato sugli sviluppatori e che è necessario comprendere gli input forniti. Se si utilizza lo streaming o l'endpoint non lo supporta, AnythingLLM include un'impostazione per disabilitare lo streaming per OpenAI generico.
Lista di controllo di sicurezza e operativa
- Tratta la chiave CometAPI come qualsiasi altro segreto: non inserirla nei repository; conservala nei portachiavi del sistema operativo o nelle variabili di ambiente, ove possibile.
- Se si prevede di utilizzare documenti sensibili in RAG, assicurarsi che le garanzie di privacy degli endpoint soddisfino le proprie esigenze di conformità (consultare la documentazione/i termini di CometAPI).
- Stabilisci i limiti massimi di token e di finestra di contesto per evitare bollette incontrollate.
Come si configura AnythingLLM per utilizzare CometAPI (passo dopo passo)?
Di seguito è riportata una sequenza di passaggi concreti, seguita da esempi di variabili di ambiente e frammenti di codice per testare la connessione prima di salvare le impostazioni nell'interfaccia utente di AnythingLLM.
Passaggio 1: ottieni la tua chiave CometAPI
- Registrati o accedi a CometAPI.
- Vai su "Chiavi API" e genera una chiave: otterrai una stringa simile a questa
sk-xxxxxMantienilo segreto.
Passaggio 2: verificare che CometAPI funzioni con una richiesta rapida
Utilizzare curl o Python per chiamare un semplice endpoint di completamento della chat per confermare la connettività.
Esempio di ricciolo
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": ,
"max_tokens": 50
}'
Se questo restituisce un 200 e una risposta JSON con un choices array, la tua chiave e la tua rete funzionano. (La documentazione di CometAPI mostra la superficie e gli endpoint in stile OpenAI).
Esempio Python (richieste)
import requests
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": "Bearer sk-xxxxx", "Content-Type": "application/json"}
payload = {
"model": "gpt-4o",
"messages": ,
"max_tokens": 64
}
r = requests.post(url, json=payload, headers=headers, timeout=15)
print(r.status_code, r.json())
Passaggio 3: configurare AnythingLLM (interfaccia utente)
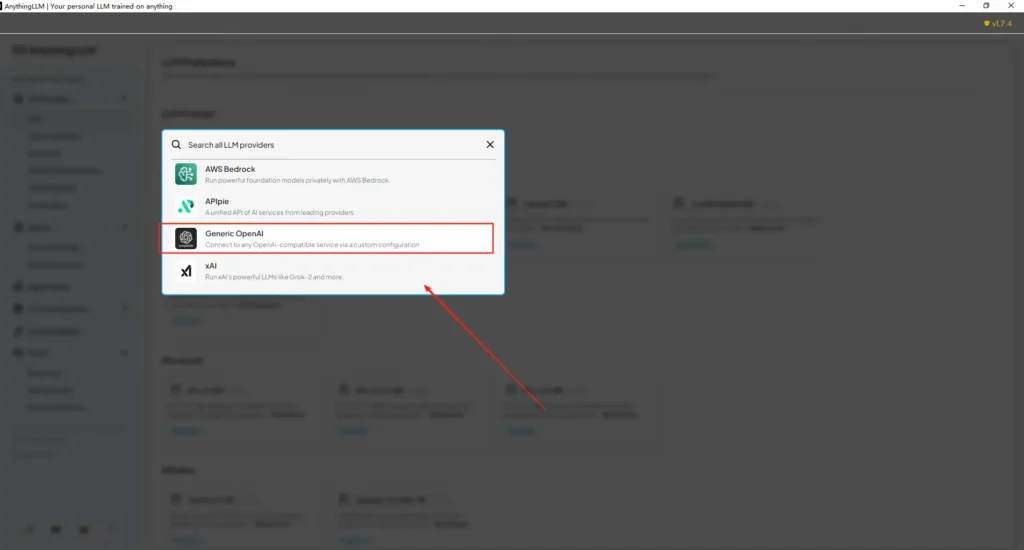
Apri AnythingLLM → Impostazioni → Fornitori di intelligenza artificiale → Preferenze LLM (o percorso simile nella tua versione). Usa il OpenAI generico fornitore e compilare i campi come segue:
Configurazione API (esempio)
• Accedere al menu delle impostazioni di AnythingLLM, individuare Preferenze LLM in Fornitori di intelligenza artificiale.
• Seleziona Generic OpenAI come fornitore del modello, inseriscihttps://api.cometapi.com/v1nel campo URL.
• Incolla ilsk-xxxxxda CometAPI nella casella di input della chiave API. Compila la finestra del contesto del token e il numero massimo di token in base al modello effettivo. Puoi anche personalizzare i nomi dei modelli in questa pagina, ad esempio aggiungendogpt-4omodello.
Ciò è in linea con la guida "Generic OpenAI" di AnythingLLM (wrapper per sviluppatori) e con l'approccio URL di base compatibile con OpenAI di CometAPI.
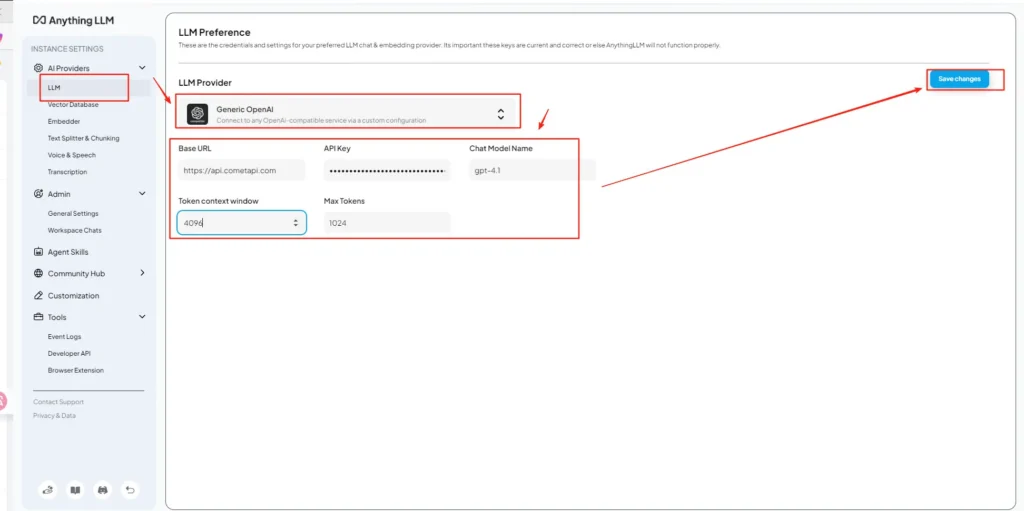
Passaggio 4: imposta i nomi dei modelli e i limiti dei token
Nella stessa schermata delle impostazioni, aggiungi o personalizza i nomi dei modelli esattamente come li pubblica CometAPI (ad esempio, gpt-4o, minimax-m2, kimi-k2-thinking) in modo che l'interfaccia utente di AnythingLLM possa presentare tali modelli agli utenti. CometAPI pubblica stringhe di modello per ciascun fornitore.
Fase 5: test in AnythingLLM
Avvia una nuova chat o utilizza un'area di lavoro esistente, seleziona il provider OpenAI generico (se hai più provider), scegli uno dei nomi di modello CometAPI che hai aggiunto ed esegui un semplice prompt. Se ottieni completamenti coerenti, sei integrato.
Come AnythingLLM utilizza internamente tali impostazioni
Il wrapper OpenAI generico di AnythingLLM costruisce richieste in stile OpenAI (/v1/chat/completions, /v1/embeddings), quindi una volta indicato l'URL di base e fornita la chiave CometAPI, AnythingLLM instraderà chat, chiamate degli agenti e richieste di incorporamento tramite CometAPI in modo trasparente. Se si utilizzano agenti AnythingLLM (il @agent flussi), erediteranno lo stesso provider.
Quali sono le migliori pratiche e le possibili insidie?
Buone pratiche
- Utilizzare impostazioni di contesto appropriate al modello: Abbina la finestra di contesto del token e il numero massimo di token di AnythingLLM al modello scelto su CometAPI. La mancata corrispondenza causa troncamenti imprevisti o chiamate non riuscite.
- Proteggi le tue chiavi API: Memorizza le chiavi CometAPI nelle variabili di ambiente e/o nel gestore dei segreti/Kubernetes; non archiviarle mai in Git. AnythingLLM memorizzerà le chiavi nelle sue impostazioni locali se le inserisci nell'interfaccia utente: considera l'archiviazione host come sensibile.
- Iniziare con modelli più economici/più piccoli per i flussi sperimentali: Utilizza CometAPI per provare modelli a basso costo per lo sviluppo e riservare modelli premium per la produzione. CometAPI pubblicizza esplicitamente la commutazione dei costi e la fatturazione unificata.
- Monitora l'utilizzo e imposta avvisi: CometAPI fornisce dashboard di utilizzo: imposta budget/avvisi per evitare fatture a sorpresa.
- Agenti e strumenti di prova isolati: Gli agenti AnythingLLM possono attivare azioni; testarli prima con prompt sicuri e su istanze di staging.
Insidie comuni
- Interfaccia utente vs.
.envconflitti: Durante l'auto-hosting, le impostazioni dell'interfaccia utente possono sovrascrivere.envmodifiche (e viceversa). Controlla il generato/app/server/.envse le cose tornano normali dopo il riavvio. Segnalazione dei problemi della communityLLM_PROVIDERresetta. - Mancata corrispondenza del nome del modello: L'utilizzo di un nome di modello non disponibile su CometAPI causerà un errore 400/404 dal gateway. Verificare sempre i modelli disponibili nell'elenco dei modelli CometAPI.
- Limiti dei token e streaming: Se hai bisogno di risposte in streaming, verifica che il modello CometAPI supporti lo streaming (e che la versione dell'interfaccia utente di AnythingLLM lo supporti). Alcuni provider differiscono nella semantica dello streaming.
Quali casi d'uso concreti sblocca questa integrazione?
Generazione aumentata di recupero (RAG)
Utilizza i caricatori di documenti di AnythingLLM + il database vettoriale con gli LLM CometAPI per generare risposte contestuali. Puoi sperimentare con modelli di embedding economici e chat più costosi, oppure mantenere tutto su CometAPI per una fatturazione unificata. I flussi RAG di AnythingLLM sono una funzionalità integrata primaria.
Automazione degli agenti
AnythingLLM supporta @agent Flussi di lavoro (esplorazione di pagine, chiamata di strumenti, esecuzione di automazioni). L'instradamento delle chiamate LLM degli agenti tramite CometAPI offre la possibilità di scegliere tra diversi modelli per le fasi di controllo/interpretazione senza modificare il codice dell'agente.
Test A/B multi-modello e ottimizzazione dei costi
Cambia modello per area di lavoro o funzionalità (ad esempio, gpt-4o per risposte di produzione, gpt-4o-mini per gli sviluppatori). CometAPI semplifica gli scambi di modelli e centralizza i costi.
Condotte multimodali
CometAPI fornisce modelli di immagini, audio e specializzati. Il supporto multimodale di AnythingLLM (tramite provider) e i modelli di CometAPI consentono di creare didascalie per le immagini, riepiloghi multimodali o flussi di trascrizione audio attraverso la stessa interfaccia.
Conclusione
CometAPI continua a posizionarsi come gateway multi-modello (oltre 500 modelli, API in stile OpenAI), il che la rende un partner naturale per app come AnythingLLM che già supportano un provider OpenAI generico. Allo stesso modo, il provider generico di AnythingLLM e le recenti opzioni di configurazione semplificano la connessione a tali gateway. Questa convergenza semplifica la sperimentazione e la migrazione in produzione entro la fine del 2025.
Come iniziare a usare Comet API
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
Per iniziare, esplora le capacità del modello diCometaAPI nella Parco giochi e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. ConeAPI t offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!