

DeepSeek-V3.1 è l'ultimo modello di ragionamento ibrido di DeepSeek che supporta sia una modalità di chat veloce "non-pensante" che una modalità "pensante/ragionatore" più ponderata, offre contesto esteso (fino a 128K), output strutturati e chiamate di funzioni, ed è accessibile direttamente tramite l'API di DeepSeek compatibile con OpenAI, tramite un endpoint compatibile con Anthropic o tramite CometAPI. Di seguito vi illustrerò il modello, i benchmark e i costi, le funzionalità avanzate (chiamate di funzioni, output JSON, modalità di ragionamento), quindi fornirò esempi di codice end-to-end concreti: chiamate REST dirette a DeepSeek (curl / Node / Python), utilizzo del client Anthropic e chiamate tramite CometAPI.
Che cos'è DeepSeek-V3.1 e quali sono le novità di questa versione?
DeepSeek-V3.1 è la versione più recente della famiglia DeepSeek V3: una linea di modelli linguistici di grandi dimensioni ad alta capacità e con un mix di esperti che spedisce un progettazione di inferenza ibrida con due “modalità” operative: una veloce chiacchierata senza pensiero modalità e a pensante / ragionatore Modalità in grado di esporre tracce di tipo "chain-of-thought" per attività di ragionamento più complesse e per l'utilizzo di agenti/strumenti. La versione enfatizza una latenza di "pensiero" più rapida, funzionalità migliorate di strumenti/agenti e una gestione del contesto più lunga per flussi di lavoro su scala documentale.
Punti pratici chiave:
- Due modalità di funzionamento:
deepseek-chatper produttività e costi,deepseek-reasoner(un modello di ragionamento) quando si desiderano tracce di una catena di pensiero o una maggiore fedeltà di ragionamento. - Miglioramenti nella gestione degli agenti/strumenti e del tokenizzatore/contesto per i documenti lunghi.
- Lunghezza del contesto: fino a ~128K token (consente documenti lunghi, basi di codice, registri).
Punto di riferimento rivoluzionario
DeepSeek-V3.1 ha dimostrato miglioramenti significativi nelle sfide di codifica del mondo reale. Nella valutazione verificata di SWE-bench, che misura la frequenza con cui il modello risolve i problemi di GitHub per garantire il superamento dei test unitari, la V3.1 ha raggiunto un tasso di successo del 66%, rispetto al 45% sia della V3-0324 che della R1. Nella versione multilingue, la V3.1 ha risolto il 54.5% dei problemi, quasi il doppio del tasso di successo di circa il 30% delle altre versioni. Nella valutazione Terminal-Bench, che verifica se il modello può completare con successo le attività in un ambiente Linux live, DeepSeek-V3.1 ha superato con successo il 31% delle attività, rispetto al 13% e al 6% rispettivamente delle altre versioni. Questi miglioramenti dimostrano che DeepSeek-V3.1 è più affidabile nell'esecuzione del codice e nel funzionamento in ambienti di strumenti reali.
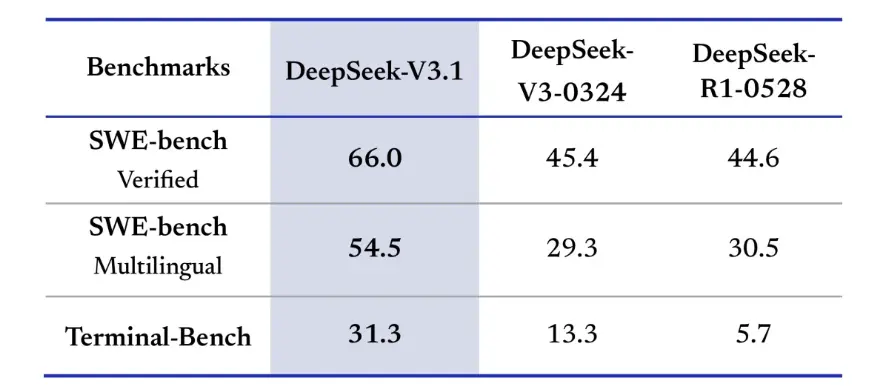
Anche i benchmark di information retrieval favoriscono DeepSeek-V3.1 in termini di navigazione, ricerca e risposta alle domande. Nella valutazione BrowseComp, che richiede la navigazione e l'estrazione di risposte da una pagina web, V3.1 ha risposto correttamente al 30% delle domande, rispetto al 9% di R1. Nella versione cinese, DeepSeek-V3.1 ha raggiunto un'accuratezza del 49%, rispetto al 36% di R1. Nell'Hard Language Exam (HLE), V3.1 ha leggermente superato R1, raggiungendo un'accuratezza rispettivamente del 30% e del 25%. In attività di ricerca approfondita come xbench-DeepSearch, che richiedono la sintesi di informazioni da più fonti, V3.1 ha ottenuto un punteggio del 71% rispetto al 1% di R55. DeepSeek-V3.1 ha anche dimostrato un piccolo ma costante vantaggio in benchmark come (ragionamento strutturato), SimpleQA (risposta a domande fattuali) e Seal0 (risposta a domande specifiche per dominio). Nel complesso, la versione V3.1 ha superato significativamente la versione R1 nel recupero delle informazioni e nella risposta alle domande in modo semplice.
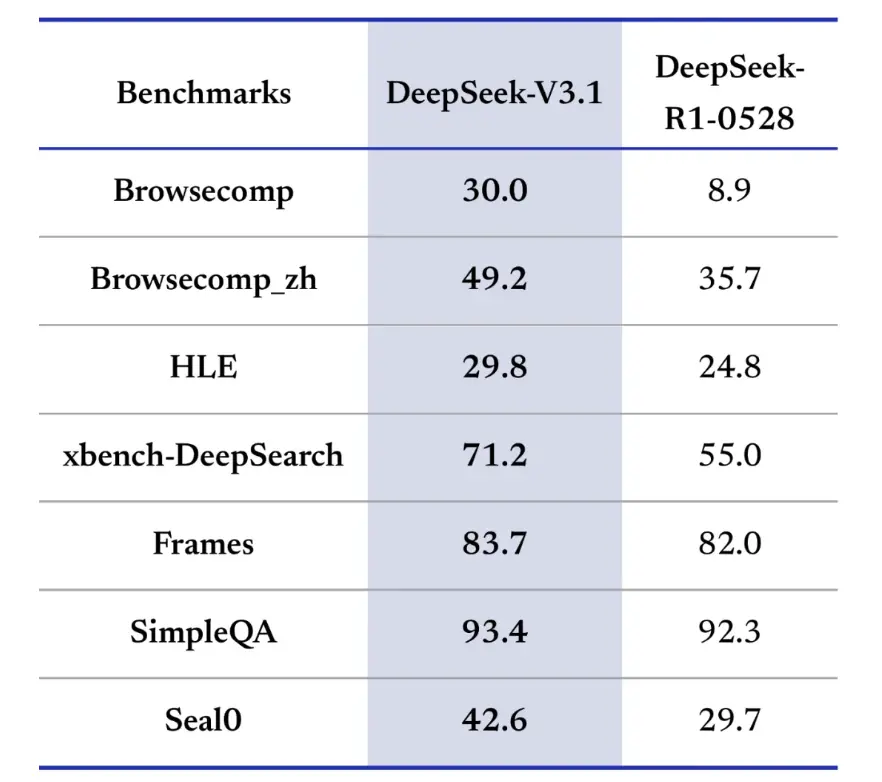
In termini di efficienza del ragionamento, i risultati dell'utilizzo dei token ne dimostrano l'efficacia. Nell'AIME 2025 (un esame di matematica difficile), V3.1-Think ha raggiunto un'accuratezza paragonabile o leggermente superiore a R1 (88.4% contro 87.5%), ma ha utilizzato circa il 30% di token in meno. Nel GPQA Diamond (un esame di laurea multidisciplinare), i due modelli erano quasi alla pari (80.1% contro 81.0%), ma V3.1 ha utilizzato quasi la metà dei token come R1. Nel benchmark LiveCodeBench, che valuta il ragionamento del codice, V3.1 non solo è risultato più accurato (74.8% contro 73.3%), ma anche più conciso. Ciò dimostra che V3.1-Think è in grado di fornire un ragionamento dettagliato evitando la verbosità.
Nel complesso, la versione V3.1 rappresenta un significativo salto generazionale rispetto alla V3-0324. Rispetto alla R1, la V3.1 ha raggiunto una maggiore accuratezza in quasi tutti i benchmark ed è risultata più efficace nei compiti di ragionamento più complessi. L'unico benchmark in cui la R1 ha eguagliato i risultati è stato GPQA, ma a un costo quasi doppio.
Come posso ottenere una chiave API e configurare un account di sviluppo?
Passaggio 1: registrati e crea un account
- Visita il portale per sviluppatori di DeepSeek (DeepSeek docs/console). Crea un account con il tuo indirizzo email o provider SSO.
- Completare tutti i controlli di identità o le impostazioni di fatturazione richiesti dal portale.
Passaggio 2: creare una chiave API
- Nella dashboard, vai a Tasti API → Crea chiaveAssegna un nome alla tua chiave (ad esempio,
dev-local-01). - Copia la chiave e conservala in un gestore di segreti sicuro (vedi le best practice di produzione di seguito).
Suggerimento: alcuni gateway e router di terze parti (ad esempio, CometAPI) consentono di utilizzare una singola chiave gateway per accedere ai modelli DeepSeek tramite essi, il che è utile per la ridondanza multi-provider (vedere API DeepSeek V3.1 sezione).
Come posso configurare il mio ambiente di sviluppo (Linux/macOS/Windows)?
Si tratta di una configurazione semplice e riproducibile per Python e Node.js che funziona per DeepSeek (endpoint compatibili con OpenAI), CometAPI e Anthropic.
Prerequisiti
- Python 3.10+ (consigliato), pip, virtualenv.
- Node.js 18+ e npm/yarn.
- curl (per test rapidi).
Ambiente Python (passo dopo passo)
- Crea una directory di progetto:
mkdir deepseek-demo && cd deepseek-demo
python -m venv .venv
source .venv/bin/activate # macOS / Linux
# .venv\Scripts\activate # Windows PowerShell
- Installa i pacchetti minimi:
pip install --upgrade pip
pip install requests
# Optional: install an OpenAI-compatible client if you prefer one:
pip install openai
- Salva la tua chiave API nelle variabili di ambiente (non eseguire mai il commit):
export DEEPSEEK_KEY="sk_live_xxx"
export CometAPI_KEY="or_xxx"
export ANTHROPIC_KEY="anthropic_xxx"
(Utilizzo di Windows PowerShell $env:DEEPSEEK_KEY = "…")
Ambiente del nodo (passo dopo passo)
- Inizializzare:
mkdir deepseek-node && cd deepseek-node
npm init -y
npm install node-fetch dotenv
- Creare un
.envfile:
DEEPSEEK_KEY=sk_live_xxx
CometAPI_KEY=or_xxx
ANTHROPIC_KEY=anthropic_xxx
Come posso richiamare direttamente DeepSeek-V3.1? Esempi di codice passo passo.
L'API di DeepSeek è compatibile con OpenAI. Di seguito sono riportati copia-incolla esempi: curl, Python (richieste e stile SDK OpenAI) e Node.
Fase 1: Esempio di ricciolo semplice
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat-v3.1",
"messages": [
{"role":"system","content":"You are a concise engineering assistant."},
{"role":"user","content":"Give a 5-step secure deployment checklist for a Django app."}
],
"max_tokens": 400,
"temperature": 0.0,
"reasoning_enabled": true
}'
Note: reasoning_enabled Attiva/disattiva la modalità Think (flag del fornitore). Il nome esatto del flag può variare a seconda del fornitore: consultare la documentazione del modello.
Passaggio 2: Python (richieste) con semplice telemetria
import os, requests, time, json
API_KEY = os.environ
URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat-v3.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Refactor this Flask function to be testable: ..."}
],
"max_tokens": 600,
"temperature": 0.1,
"reasoning_enabled": True
}
start = time.time()
r = requests.post(URL, headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}, json=payload, timeout=60)
elapsed = time.time() - start
print("Status:", r.status_code, "Elapsed:", elapsed)
data = r.json()
print(json.dumps(data, indent=2))
CometAPI: accesso completamente gratuito a DeepSeek V3.1
Per gli sviluppatori che desiderano un accesso immediato senza registrazione, CometAPI offre un'alternativa interessante a DeepSeek V3.1 (nome modello: deepseek-v3-1-250821; deepseek-v3.1). Questo servizio gateway aggrega più modelli di intelligenza artificiale tramite un'API unificata, fornendo accesso a DeepSeek e offrendo altri vantaggi, tra cui failover automatico, analisi dell'utilizzo e fatturazione semplificata tra provider.
Per prima cosa, crea un account CometAPI su https://www.cometapi.com/—l'intero processo richiede solo due minuti e richiede solo la verifica dell'indirizzo email. Una volta effettuato l'accesso, genera una nuova chiave nella sezione "Chiave API". https://www.cometapi.com/ offre crediti gratuiti per i nuovi account e uno sconto del 20% sul prezzo ufficiale dell'API.
L'implementazione tecnica richiede modifiche minime al codice. È sufficiente modificare l'endpoint API da un URL DeepSeek diretto al gateway CometAPI.
Nota: l'API supporta lo streaming (
stream: true),max_tokens, temperatura, sequenze di arresto e funzionalità di chiamata di funzioni simili ad altre API compatibili con OpenAI.
Come posso richiamare DeepSeek utilizzando gli SDK di Anthropic?
DeepSeek fornisce un endpoint compatibile con Anthropic in modo da poter riutilizzare gli SDK Anthropic o gli strumenti di Claude Code indirizzando l'SDK a https://api.deepseek.com/anthropic e impostando il nome del modello su deepseek-chat (o deepseek-reasoner dove supportato).
Richiama il modello DeepSeek tramite l'API Anthropic
Installa l'SDK di Anthropic: pip install anthropic. Configura il tuo ambiente:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEY
Crea un messaggio:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
print(message.content)
Utilizzare DeepSeek in Claude Code
Installa: npm install -g @anthropic-ai/claude-code. Configura il tuo ambiente:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_API_KEY}
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
Entra nella directory del progetto ed esegui il codice Claude:
cd my-project
claude
Utilizzare DeepSeek in Claude Code tramite CometAPI
CometAPI supporta Claude Code. Dopo l'installazione, durante la configurazione dell'ambiente, è sufficiente sostituire l'URL di base con https://www.cometapi.com/console/ e la chiave con la chiave di CometAPI per utilizzare il modello DeepSeek di CometAPI in Claude Code.
# Navigate to your project folder cd your-project-folder
# Set environment variables (replace sk-... with your actual token)
export ANTHROPIC_AUTH_TOKEN=sk-...
export ANTHROPIC_BASE_URL=https://www.cometapi.com/console/
# Start Claude Code
claude
Note:
- DeepSeek mappa i nomi dei modelli antropici non supportati in
deepseek-chat. - Il livello di compatibilità antropica supporta
system,messages,temperature, streaming, sequenze di arresto e array di pensiero.
Quali sono le migliori pratiche concrete di produzione (sicurezza, costi, affidabilità)?
Di seguito sono riportati i modelli di produzione consigliati che si applicano a DeepSeek o a qualsiasi utilizzo LLM ad alto volume.
Segreti e identità
- Memorizza le chiavi API in un gestore segreto (non utilizzare
.envin produzione). Ruotare regolarmente le chiavi e creare chiavi per servizio con il minimo privilegio. - Utilizzare progetti/account separati per sviluppo/staging/produzione.
Limiti di velocità e nuovi tentativi
- Realizzare backoff esponenziale su HTTP 429/5xx con jitter. Limita i tentativi di ripetizione (ad esempio, 3 tentativi).
- Utilizzare chiavi di idempotenza per le richieste che potrebbero essere ripetute.
Esempio Python: riprova con backoff
import time, random, requests
def post_with_retries(url, headers, payload, attempts=3):
for i in range(attempts):
r = requests.post(url, json=payload, headers=headers, timeout=60)
if r.status_code == 200:
return r.json()
if r.status_code in (429, 502, 503, 504):
backoff = (2 ** i) + random.random()
time.sleep(backoff)
continue
r.raise_for_status()
raise RuntimeError("Retries exhausted")
Gestione dei costi
- Limitare
max_tokensed evitare di richiedere accidentalmente output enormi. - Risposte del modello di cache dove appropriato (soprattutto per richieste ripetute). DeepSeek distingue esplicitamente tra hit e miss della cache nel prezzo: la memorizzazione nella cache fa risparmiare denaro.
- Usa il
deepseek-chatper piccole risposte di routine; riservadeepseek-reasonerper i casi in cui è realmente necessario il CoT (è più costoso).
Osservabilità e registrazione
- Registra solo i metadati relativi alle richieste in testo normale (hash dei prompt, conteggi dei token, latenze). Evita di registrare dati utente completi o contenuti sensibili. Conserva gli ID di richiesta/risposta per il supporto e la riconciliazione della fatturazione.
- Tieni traccia dell'utilizzo dei token per richiesta ed esponi budget/avvisi sui costi.
Controlli di sicurezza e allucinazioni
- Usa il output degli strumenti e validatori deterministici per qualsiasi questione critica per la sicurezza (finanziaria, legale, medica).
- Per output strutturati, utilizzare
response_format+Schema JSON e convalida degli output prima di intraprendere azioni irreversibili.
Modelli di distribuzione
- Eseguire chiamate al modello da un processo worker dedicato per controllare la concorrenza e la coda.
- Delegare i lavori più pesanti ai worker asincroni (attività di Celery, Fargate, attività di Cloud Run) e rispondere agli utenti con indicatori di avanzamento.
- Per esigenze di latenza/rendimento estreme, valutare gli SLA del provider e se auto-ospitare o utilizzare gli acceleratori del provider.
Nota di chiusura
DeepSeek-V3.1 è un modello ibrido e pragmatico, progettato sia per chat veloci che per attività agentiche complesse. La sua API compatibile con OpenAI semplifica la migrazione per molti progetti, mentre i livelli di compatibilità Anthropic e CometAPI lo rendono flessibile per gli ecosistemi esistenti. Benchmark e report della community mostrano promettenti compromessi tra costi e prestazioni, ma come per qualsiasi nuovo modello, è consigliabile validarlo sui carichi di lavoro reali (prompting, chiamata di funzioni, controlli di sicurezza, latenza) prima del lancio in produzione.
Su CometAPI, puoi eseguirlo in modo sicuro e interagire con esso tramite un'API compatibile con OpenAI o intuitiva parco giochi, senza limiti di tariffa.
👉 Distribuisci subito DeepSeek-V3.1 su CometAPI!
Perché utilizzare CometAPI?
- Multiplexing del fornitore: cambiare fornitore senza riscrivere il codice.
- Fatturazione/metriche unificate: se si instradano più modelli tramite CometAPI, si ottiene un'unica superficie di integrazione.
- Metadati del modello: visualizza la lunghezza del contesto e i parametri attivi per ogni variante del modello.