

Nano Banana Pro — ufficialmente Gemini 3 Pro Image — è il nuovo modello di generazione ed editing di immagini di Google/DeepMind di livello studio che combina ragionamento multimodale avanzato, rendering del testo ad alta fedeltà, composizione multi‑immagine e controlli creativi di livello studio.
Che cos’è Nano Banana Pro e perché ti dovrebbe interessare?
Nano Banana Pro è il più recente modello di generazione e modifica di immagini di Google — la release “Gemini 3 Pro Image” — progettato per produrre immagini e testo sull’immagine con qualità da studio fino a 4K e sensibili al contesto. È il successore dei precedenti modelli Nano Banana (Gemini 2.5 Flash Image / “Nano Banana”) con ragionamento migliorato, grounding tramite Search (fatti reali), rendering del testo più robusto e controlli locali di modifica più potenti. Il modello è disponibile all’interno dell’app Gemini per utenti interattivi e puoi accedere a Nano Banana Pro tramite la normale Gemini API, selezionando lo specifico identificatore di modello (gemini-3-pro-image-preview o il suo successore stabile) per l’accesso programmatico.
Perché è importante: Nano Banana Pro non è costruito solo per creare immagini belle, ma per visualizzare informazioni — infografiche, snapshot basati su dati (meteo, sport), poster ricchi di testo, mockup di prodotto e fusioni multi‑immagine (fino a 14 immagini di input, mantenendo la coerenza dei personaggi fino a 5 persone). Per designer, team di prodotto e sviluppatori, questa combinazione di accuratezza, testo sull’immagine e accesso programmatico apre flussi di produzione finora difficili da automatizzare.
Quali funzioni sono esposte tramite API?
Le capacità tipiche dell’API per gli sviluppatori includono:
- Generazione Testo → Immagine (flussi di composizione “thinking” a uno o più passaggi).
- Editing di immagini (maschere locali, inpainting, regolazioni di stile).
- Fusione multi‑immagine (combinare immagini di riferimento).
- Controlli avanzati della richiesta: risoluzione, rapporto d’aspetto, passaggi di post‑processing e tracce del “pensiero di composizione” per debug/ispezionabilità nelle modalità di anteprima.
Innovazioni principali e funzioni di Nano Banana Pro
Ragionamento dei contenuti più intelligente
Usa lo stack di ragionamento di Gemini 3 Pro per interpretare istruzioni visive complesse e multi‑step (ad es., “crea un’infografica in 5 passaggi da questo dataset e aggiungi una didascalia bilingue”). L’API espone un meccanismo “Thinking” che può produrre test di composizione intermedi per affinare il risultato finale.
Perché è importante: Invece di un singolo passaggio che mappa prompt → pixel, il modello esegue un processo interno di “thinking” che perfeziona la composizione e può chiamare strumenti esterni (ad es., Google Search) per il grounding fattuale (ad es., etichette di diagrammi accurate o segnaletica corretta per località). Questo produce immagini non solo più belle ma anche semanticamente più corrette per compiti come infografiche, diagrammi o mockup di prodotto.
Come si ottiene: Il “Thinking” di Nano Banana Pro è un passaggio controllato di ragionamento/composizione interno in cui il modello genera visual intermedi e tracce di ragionamento prima di produrre l’immagine finale. L’API indica che il modello può creare fino a due frame intermedi e che l’immagine finale è l’ultimo stadio di tale catena. In produzione questo aiuta nella composizione, nel posizionamento del testo e nelle decisioni di layout.
Rendering del testo più accurato
Testo in‑immagine significativamente più leggibile e localizzato (menu, poster, diagrammi). Nano Banana Pro raggiunge nuovi livelli nel rendering del testo nelle immagini:
- Il testo nelle immagini è chiaro, leggibile e ortograficamente corretto;
- Supporta la generazione multilingue (inclusi cinese, giapponese, coreano, arabo, ecc.);
- Consente di inserire testi lunghi o descrittivi su più righe direttamente nelle immagini;
- Sono disponibili traduzione e localizzazione automatiche.
Perché è importante: Tradizionalmente i modelli di immagini faticano a rendere testo leggibile e ben allineato. Nano Banana Pro è esplicitamente ottimizzato per un rendering affidabile del testo e per la localizzazione (ad es., tradurre preservando il layout), sbloccando casi d’uso creativi reali come poster, packaging o annunci multilingue.
Come si ottiene: I miglioramenti nel rendering del testo derivano dall’architettura multimodale sottostante e dall’addestramento su dataset che enfatizzano esempi di testo‑in‑immagine, combinati con set di valutazione mirati (valutazioni umane e set di regressione). Il modello impara ad allineare forme dei glifi, font e vincoli di layout per produrre testo leggibile e localizzato all’interno delle immagini — anche se testo molto piccolo e paragrafi estremamente densi possono restare soggetti a errori.
Maggiore coerenza visiva e fedeltà
Controlli di livello studio (illuminazione, messa a fuoco, angolo di ripresa, color grading) e composizione multi‑immagine (fino a 14 immagini di riferimento, con permessi speciali per più soggetti umani) aiutano a preservare la coerenza dei personaggi (mantenere la stessa persona/personaggio tra le modifiche) e l’identità del brand su asset generati. Il modello supporta output nativi 1K/2K/4K.
Perché è importante: I flussi di lavoro di marketing e intrattenimento richiedono personaggi coerenti tra scatti ed editing. Il modello può mantenere la somiglianza per fino a cinque persone e fondere fino a 14 immagini di riferimento in un’unica composizione, producendo Sketch → 3D Render. È utile per creatività pubblicitaria, packaging o storytelling multi‑shot.
Come si ottiene: Gli input del modello accettano più immagini con assegnazioni di ruolo esplicite (ad es., “Immagine A: posa”, “Immagine B: riferimento volto”, “Immagine C: texture di sfondo”). L’architettura condiziona la generazione su tali immagini per mantenere identità/posa/stile applicando al contempo trasformazioni (illuminazione, camera).
Benchmark di prestazioni di Nano Banana Pro
Nano Banana Pro (Gemini 3 Pro Image) “eccelle nei benchmark di IA Testo→Immagine” e dimostra un ragionamento migliorato e un grounding contestuale rispetto ai precedenti modelli Nano Banana. Sottolinea una fedeltà superiore e un rendering del testo migliorato rispetto alle versioni precedenti.
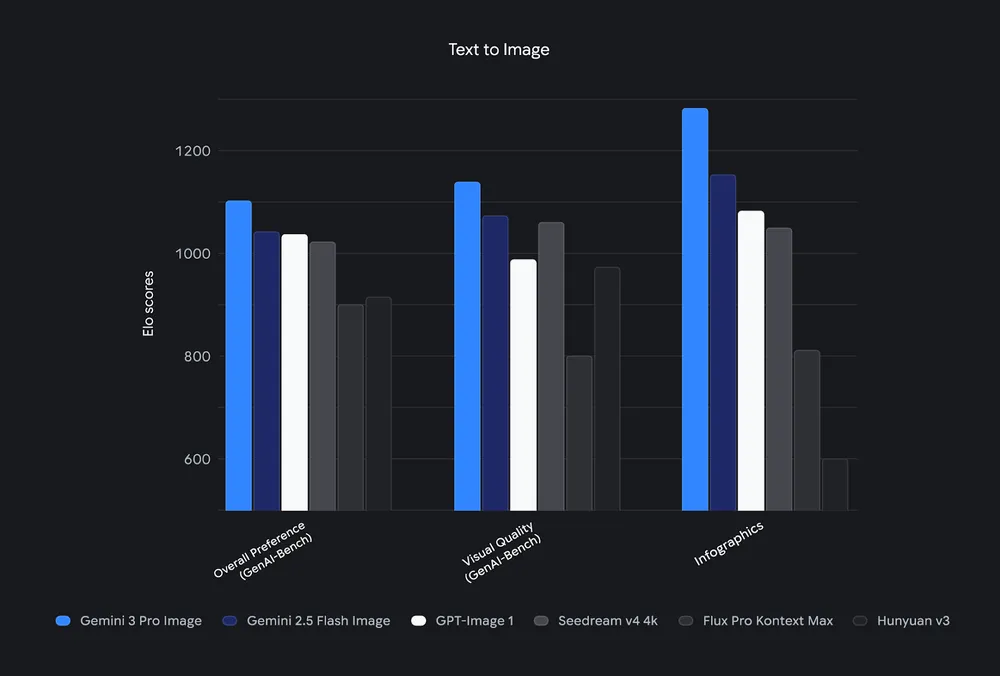
Indicazioni pratiche sulle prestazioni
Aspettati una maggiore latenza e costi più elevati per render 2K/4K ad alta fedeltà rispetto a 1K o ai modelli “Flash” ottimizzati per la velocità. Se throughput/latenza sono critici, usa la variante flash (ad es., Gemini 2.5 Flash / Nano Banana) per volumi elevati; usa Nano Banana Pro / gemini-3-pro-image per qualità e compiti di ragionamento complessi.
Come possono gli sviluppatori accedere a Nano Banana Pro?
Quali endpoint e modelli scegliere
Identificatore di modello (preview / pro): gemini-3-pro-image-preview (anteprima) — usa questo quando vuoi le capacità di Nano Banana Pro. Per lavori più rapidi e a costo inferiore, gemini-2.5-flash-image (Nano Banana) resta disponibile.
Superfici da utilizzare
- Gemini API (endpoint generativelanguage): Puoi usare una chiave CometAPI per accedere a xx. CometAPI offre la stessa API a un prezzo più favorevole rispetto al sito ufficiale. Chiamate HTTP dirette / SDK a
generateContentper la generazione di immagini (esempi sotto). - Google AI Studio: Interfaccia web per sperimentazione rapida e remix di app demo.
- Vertex AI (enterprise): Throughput pre‑assegnato, opzioni di fatturazione (pay‑as‑you‑go / tier enterprise) e filtri di sicurezza per la produzione su larga scala. Usa Vertex quando integri in grandi pipeline o job di rendering batch.
Il piano gratuito ha un limite di utilizzo ridotto; superato il limite si torna a Nano Banana. I piani Plus/Pro/Ultra offrono limiti più alti e output senza watermark, ma Ultra può essere usato negli strumenti video Flow e in Antigravity IDE in modalità 4K.
Come genero un’immagine con Nano Banana Pro (passo dopo passo)?
1) Ricetta rapida interattiva per usare l’app Gemini
- Apri Gemini → Tools → Create images.
- Seleziona Thinking (Nano Banana Pro) come modello.
- Inserisci un prompt: spiega soggetto, azione, mood, illuminazione, camera, rapporto d’aspetto e qualsiasi testo da far apparire sull’immagine. Esempio:
“Crea un poster 4K di un workshop di robotica: un team eterogeneo attorno a un tavolo, overlay di blueprint, headline in grassetto ‘Robots in Action’ in sans serif, luce tungsteno calda, profondità di campo ridotta, composizione cinematografica 16:9.” - (Opzionale) Carica fino a 14 immagini da fondere o usare come riferimento. Usa lo strumento di selezione/maschera per modifiche locali.
- Genera, itera in linguaggio naturale (ad es., “rendi l’headline blu e allineata in alto al centro; aumenta il contrasto del blueprint”), poi esporta.
2) Usa HTTP per inviare all’endpoint immagine di Gemini
Devi accedere a CometAPI per ottenere la chiave.
# save your API key to $CometAPI_API_KEY securely before running
curl -s -X POST \
"https://api.cometapi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $CometAPI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "Photorealistic 4K image of a yellow banana floating over Earth, studio lighting, cinematic composition. Add bold text overlay: \"Nano Banana Pro\" in top right corner."
}]
}],
"generationConfig": {
"imageConfig": {
"resolution": "4096x4096",
"aspectRatio": "1:1"
}
}
}' \
| jq -r '.candidates.content.parts[] | select(.inlineData) | .inlineData.data' \
| base64 --decode > nano_banana_pro_4k.png
Questo esempio scrive il payload immagine base64 in un file PNG. Il parametro generationConfig.imageConfig.resolution richiede l’output 4K (disponibile per il modello 3 Pro Image).
3) Chiamate SDK dirette a generateContent per la generazione di immagini
Richiede l’installazione del Google SDK e l’ottenimento dell’autenticazione Google. Esempio Python (testo + immagini di riferimento + grounding):
# pip install google-genai pillow
from google import genai
from PIL import Image
import base64
client = genai.Client() # reads credentials from env / config per SDK docs
# Read a reference image and set inline_data
with open("ref1.png", "rb") as f:
ref1_b64 = base64.b64encode(f.read()).decode("utf-8")
prompt_parts = [
{"text": "Create a styled product ad for a yellow banana-based energy bar. Use studio lighting, shallow DOF. Include a product label with the brand name 'Nano Bar'."},
{"inline_data": {"mime_type": "image/png", "data": ref1_b64}}
]
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=,
generation_config={
"imageConfig": {"resolution":"4096x4096", "aspectRatio":"4:3"},
# tools can be provided to ground facts, e.g. "google_search"
"tools":
}
)
for part in response.candidates.content.parts:
if part.inline_data:
image = part.as_image()
image.save("product_ad.png")
Questo esempio mostra il caricamento di un’immagine di riferimento inline e la richiesta di una composizione 4K abilitando google_search come tool. L’SDK Python gestirà i dettagli REST di basso livello.
Fusione multi‑immagine e coerenza dei personaggi
Per produrre un composito che preservi la stessa persona tra le scene, passa più parti inline_data (selezionate dal tuo set di foto) e specifica nell’istruzione creativa che il modello deve “preservare l’identità tra gli output”.
Breve esempio pratico — un prompt reale e flusso atteso
Prompt:
"Generate a 2K infographic: 'Q4 Sales by Region 2025' — stacked bar chart with North America 35%, EMEA 28%, APAC 25%, LATAM 12%. Include title top-center, caption with source bottom-right, clean sans-serif labels, neutral palette, vector look, 16:9."
Expected pipeline: app → template di prompt + dati CSV → sostituisci i placeholder nel prompt → chiamata API con image_size=2048x1152 → ricevi PNG in base64 → salva l’asset + metadati di provenienza → opzionalmente sovrapponi il font esatto via compositore se necessario.
Come progettare una pipeline di produzione e gestire sicurezza/provenienza?
Architettura di produzione consigliata
- Prompt + passaggio bozza (modello veloce): usa
gemini-2.5-flash-image(Nano Banana) per produrre molte varianti a bassa risoluzione in modo economico. - Selezione & raffinamento: scegli i candidati migliori, affina i prompt, applica inpainting/modifiche con maschera per precisione.
- Render finale ad alta fedeltà: chiama
gemini-3-pro-image-preview(Nano Banana Pro) per render finali 2K/4K e post‑processing (upsampling, color grade). - Provenienza & metadata: archivia prompt, versione del modello, timestamp e informazioni SynthID nel tuo archivio di metadati — il modello applica un watermark SynthID e gli output possono essere tracciati per conformità e audit dei contenuti.
Sicurezza, diritti e moderazione
- Copyright & diritti: non caricare o generare contenuti che violino diritti. Usa conferme esplicite degli utenti per immagini o prompt forniti dall’utente che possano creare somiglianze riconoscibili. La Google’s Prohibited Use Policy e i filtri di sicurezza del modello vanno rispettati.
- Filtraggio & controlli automatizzati: fai passare le immagini generate tramite una pipeline interna di moderazione dei contenuti (NSFW, simboli d’odio, contenuti politici/vincolanti) prima del consumo downstream o della pubblicazione.
Come eseguire editing (inpainting), composizione multi‑immagine e rendering del testo?
Nano Banana Pro supporta flussi di editing multimodali: fornisci una o più immagini di input e un’istruzione testuale che descriva le modifiche (rimuovere un oggetto, cambiare il cielo, aggiungere testo). L’API accetta immagine + testo nella stessa richiesta; il modello può produrre risposte con testo e immagini intercalati. Pattern d’esempio includono modifiche con maschera e blend multi‑immagine (style transfer / composizione). Vedi la documentazione per array contents che combinano blob di testo e immagini binarie.
Esempio: Edit (pseudo‑flow Python)
from google import genai
from PIL import Image
client = genai.Client()
prompt = "Remove the person on the left and add a small red 'Nano Banana Pro' sticker on the top-right of the speaker"
# contents can include Image objects or binary data per SDK; see doc for exact call
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=, # order matters: image + instruction
)
# Save result as before
Questo editing conversazionale ti consente di regolare iterativamente i risultati fino a ottenere un asset pronto per la produzione.
Esempio Node.js — editing immagine con maschera e riferimenti multipli
// npm install google-auth-library node-fetch
const { GoogleAuth } = require('google-auth-library');
const fetch = require('node-fetch');
const auth = new GoogleAuth({ scopes: });
async function runEdit() {
const client = await auth.getClient();
const token = await client.getAccessToken();
const API_URL = "https://api.generativemodels.googleapis.com/v1alpha/gemini:editImage";
const MODEL = "gemini-3-pro-image";
// Attach binary image content or URLs depending on API.
const payload = {
model: MODEL,
prompt: { text: "Replace background with an indoor studio set, keep subject, add rim light." },
inputs: {
referenceImages: [
{ uri: "gs://my-bucket/photo_subject.jpg" },
{ uri: "gs://my-bucket/target_studio.jpg" }
],
mask: { uri: "gs://my-bucket/mask.png" },
imageConfig: { resolution: "2048x2048", format: "png" }
},
options: { preserveIdentity: true }
};
const res = await fetch(API_URL, {
method: 'POST',
headers: {
'Authorization': `Bearer ${token.token}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
const out = await res.json();
console.log(JSON.stringify(out, null, 2));
}
runEdit();
(Le API a volte accettano URI di Cloud Storage o payload di immagini in base64; consulta la documentazione della Gemini API per i formati di input esatti.)
Per informazioni sulla generazione e l’editing di immagini tramite CometAPI, consulta la Guida alla chiamata di gemini-3-pro-image .
Conclusione
Nano Banana Pro (Gemini 3 Pro Image) è un salto di livello di produzione nella generazione di immagini: uno strumento per visualizzare dati, produrre modifiche localizzate e alimentare i flussi di lavoro degli sviluppatori. Usa l’app Gemini per un prototyping rapido, l’API per l’integrazione in produzione e segui le raccomandazioni sopra per controllare i costi, garantire la sicurezza e mantenere la qualità del brand. Testa sempre i flussi reali degli utenti e archivia i metadati di provenienza per soddisfare requisiti di trasparenza e audit.
Usa Nano Banana Pro quando ti servono asset di qualità da studio, controllo preciso della composizione, rendering del testo migliorato all’interno delle immagini e la capacità di fondere più riferimenti in un unico output coerente.
Gli sviluppatori possono accedere all’API Gemini 3 Pro Image (Nano Banana Pro) tramite CometAPI. Per iniziare, esplora le funzionalità del modello di CometAPI nel Playground e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver eseguito l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore rispetto al prezzo ufficiale per aiutarti nell’integrazione.
Pronto a iniziare?→ Iscriviti a CometAPI oggi stesso !
Se vuoi suggerimenti, guide e notizie sull’IA seguici su VK, X e Discord!