

Claude Opus 4.6 di Anthropic è arrivato a febbraio 2026 come un chiaro, mirato passo verso agenti di livello enterprise, lavoro conoscitivo a lungo contesto e un coding autonomo più robusto. Il rilascio combina ingegneria ambiziosa (una modalità beta con finestra di contesto da un milione di token, una capacità di “adaptive thinking” e funzionalità di lavoro di squadra tra agenti) con una decisione commerciale pragmatica: Anthropic ha mantenuto i prezzi dell’API coerenti con i precedenti modelli della famiglia Opus. Questa combinazione — capacità materialmente migliorate senza un aumento immediato dei prezzi — è il titolo.
Che cos’è esattamente Claude Opus 4.6?
Claude Opus 4.6 è il fiore all’occhiello di Anthropic nella linea Opus: un modello generativo su larga scala, incentrato sull’impresa, ottimizzato per flussi di lavoro basati su agenti, coding e lavoro conoscitivo a lungo termine. Anthropic posiziona Opus 4.6 come il suo modello più intelligente per costruire agenti e automazioni — qualcosa progettato non solo per rispondere a domande, ma per pianificare, chiamare strumenti, coordinare sottoagenti e seguire attività multifase su ampi codebase e corpora documentali.
A differenza dei chatbot orientati ai consumatori, Opus 4.6 punta alle integrazioni enterprise: è disponibile tramite l’interfaccia claude.ai, la Claude API e via CometAPI. Il punto di forza di Opus 4.6 è nelle attività di coding basate su agenti e nella chiamata di strumenti. Per le aziende, ciò significa che Opus 4.6 è posizionato come un upgrade plug‑and‑play per assistenti agentici, strumenti di migrazione del codice, pipeline di revisione documentale e flussi analitici che necessitano di un contesto più ampio rispetto a quello offerto dalle tipiche sessioni di chat.
Analisi approfondita delle principali novità di Opus 4.6
Finestra di contesto da un milione di token (e modalità pratiche)
Opus 4.6 supporta una finestra di contesto predefinita ampliata (pubblicizzata a 200K token, con una finestra da 1M token disponibile in beta). Sulla carta, una finestra da un milione di token è trasformativa: consente al modello di contenere interi repository di codice, lunghi atti legali, archivi di email pluriennali o grandi tabelle di dati in una singola conversazione, riducendo la necessità di impalcature di recupero esterne. Anthropic affianca alla finestra di contesto “grezza” strumenti di “compattazione del contesto” che aiutano a comprimere le informazioni rilevanti e ridurre i costi in token. In breve: Opus può davvero lavorare con artefatti molto grandi senza spezzettarli, semplificando la creazione di agenti di lunga durata.
Perché è importante: per il refactoring del codice, la revisione legale/finanziaria o i progetti di ricerca che richiedono ragionamento trasversale tra documenti, la finestra più ampia riduce l’overhead di ingegneria (meno retrieval, meno gestione dello stato) e migliora la coerenza su catene di ragionamento molto lunghe.
Adaptive thinking e controlli per il ragionamento esteso
Opus 4.6 introduce ciò che Anthropic chiama “adaptive thinking” (un’evoluzione delle precedenti idee di “extended thinking” dell’azienda). È sia una capacità interna sia un controllo API: gli sviluppatori possono regolare i “livelli di impegno” del modello e la profondità della pianificazione, permettendogli di spendere più calcolo su pianificazioni complesse o di mantenere risposte brevi e veloci per compiti banali.
Perché è importante: i flussi di lavoro agentici sono quelli in cui i miglioramenti marginali di qualità si sommano: migliore pianificazione + coordinamento significa meno correzioni umane e un’esecuzione autonoma più affidabile.
Cosa sono “agent teams” e l’orchestrazione basata su agenti?
Opus 4.6 introduce un supporto migliorato per i flussi di lavoro agentici: la capacità di avviare, coordinare e supervisionare più sottoagenti che si dividono e affrontano i compiti. I materiali di Anthropic (e i primi report dei partner) sottolineano che Opus può creare proattivamente sottoagenti, assegnare sottoattività, monitorarne l’avanzamento e terminare o cambiare strategia secondo necessità — fungendo di fatto da orchestratore leggero per lavori complessi, multi‑step di ingegneria o analisi. Questa stretta integrazione tra pianificazione, uso degli strumenti ed error‑correction è un punto di forza centrale per i team ad alta automazione.
Miglioramenti di API e tooling per l’integrazione enterprise
Anthropic ha ampliato i controlli dell’API per compattazione, persistenza e chiamata di strumenti. Il modello supporta limiti di output più ampi (Anthropic segnala fino a 128K token in output), semantiche di recupero più fini e integrazioni enterprise per Microsoft 365 e ambienti di sviluppo. Il risultato pratico è meno “glue code” quando si collega Opus a fogli di calcolo, presentazioni e toolchain interne. Anthropic ha integrato Opus 4.6 in strumenti di livello superiore come Claude Cowork (interfacce no‑code) e aggiornamenti a Claude Code che consentono agli utenti non tecnici di accedere all’automazione.
Come si comporta Opus 4.6 nei benchmark?
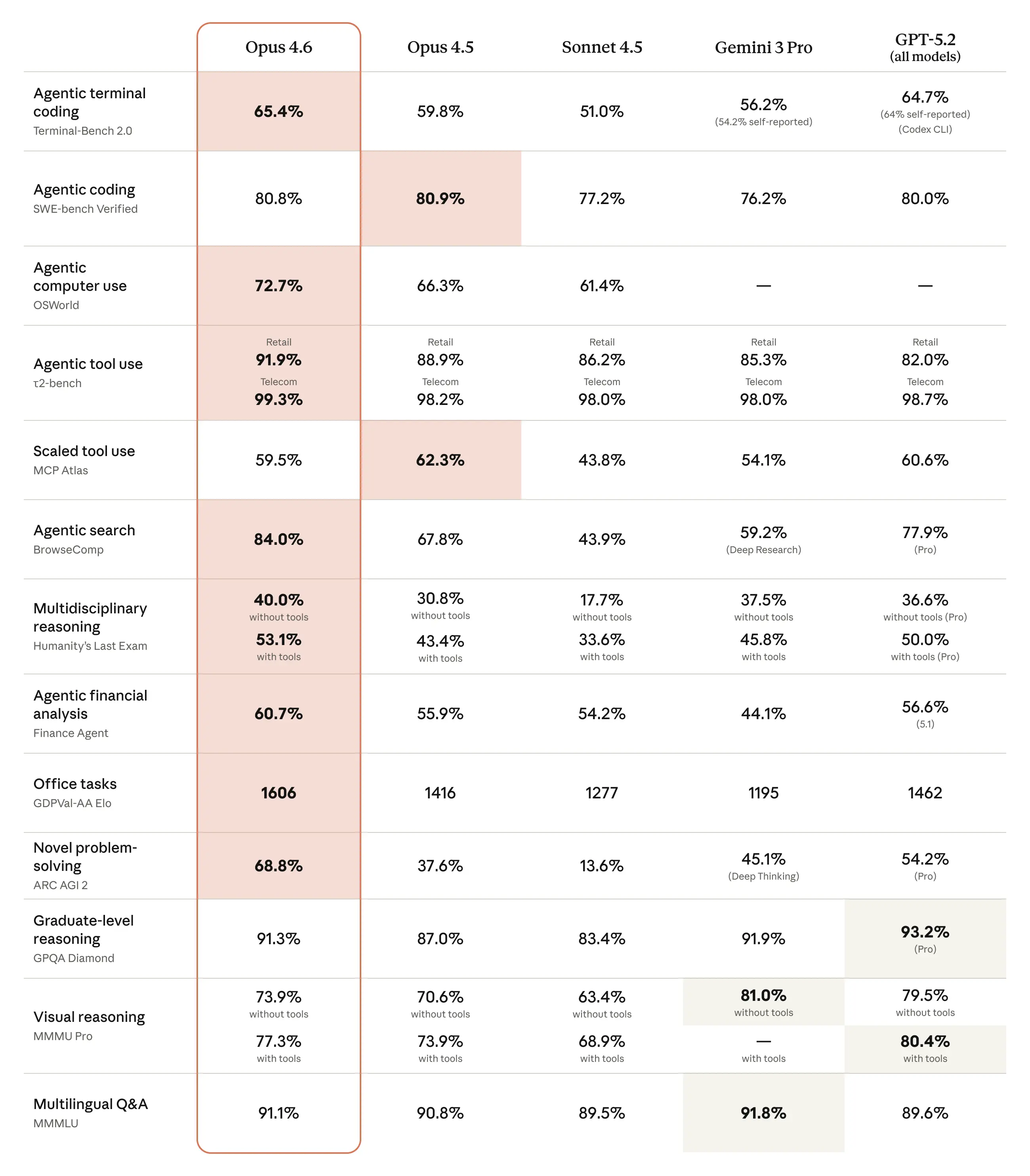
Opus 4.6 ottiene guadagni rispetto a Opus 4.5 e mostra posizionamenti competitivi rispetto a modelli recenti di OpenAI e Google in una combinazione di suite per coding, ragionamento e domini specifici. Esempi riportati in breve:
- BigLaw Bench: Opus 4.6 ha raggiunto ~90.2% sul BigLaw Bench di Anthropic (ragionamento legale).
- Terminal-Bench 2.0 / metriche GDPval: coperture indipendenti elencano punteggi di Terminal‑Bench 2.0 e valutazioni Elo GDPval‑AA che collocano Opus 4.6 davanti a Opus 4.5 e competitivo con alcune release recenti dei rivali. Un report ha indicato un punteggio Terminal‑Bench 2.0 del 65.4% e un Elo GDPval‑AA di ~1,606.
Anthropic riporta ampi miglioramenti nei compiti di coding agentico, con una pianificazione migliore, meno iterazioni e prestazioni più solide su codebase enormi — inclusa la capacità dichiarata di pianificare ed eseguire migrazioni su repository da milioni di righe in meno tempo. Si enfatizza la migliore capacità del modello di “auto‑intercettare” errori e sostenere il ragionamento su molti passaggi.
Quanto costa Opus 4.6?
Risposta breve — prezzi per token
- Standard (prompt ≤ 200K token): $5 / 1M token in input e $25 / 1M token in output.
- Prompt grandi (prompt > 200K token): $10 / 1M input e $37.50 / 1M output.
- Modalità Fast (anteprima di ricerca): un livello premium — $30 / 1M input e $150 / 1M output (inferenza più rapida).
Considerazioni pratiche sui costi:
- I flussi di lavoro basati su agenti tendono a essere costosi in token. Pianificazione multi‑step, chiamate agli strumenti e output lunghi aumentano i token in output; l’uso attento della compattazione e delle letture della cache è importante per controllare la fatturazione.
- Il batching fa risparmiare. Se il tuo carico di lavoro si adatta all’elaborazione batch asincrona, i prezzi dell’API batch di Anthropic possono ridurre in modo significativo il costo per token.
- Il contesto premium costa di più. Se ti affidi spesso alla beta da 1M token, pianifica addebiti per token più elevati. Molte organizzazioni adotteranno modalità miste: contesti grandi solo dove strettamente necessario e sessioni leggere altrove.
Cerchi soluzioni più economiche per usare la Claude API
CometAPI è una buona scelta. La Opus 4.6 API proviene anch’essa da Anthropic, ma il suo prezzo API è pari al 20% del prezzo ufficiale, e questo non cambia al variare della lunghezza del contesto.
Come si confronta Opus 4.6 con GPT-5.3 e Google Gemini 3?
Opus 4.6 vs GPT-5.3 di OpenAI
Il recente GPT‑5.3 di OpenAI (brandizzato da OpenAI nella linea “Codex” per compiti di coding/agent) è esplicitamente calibrato per il coding profondo e i flussi di lavoro in stile agente e rivendica punteggi leader del settore su diversi benchmark ingegneristici (SWE‑Bench Pro, Terminal‑Bench). Le prime coperture suggeriscono che GPT‑5.3‑Codex spinga lo stato dell’arte nei benchmark di ingegneria del software e pianificazione agentica, posizionandosi come il rivale più diretto di Opus 4.6 nei compiti puramente di coding e agentici. Opus 4.6 — per contro — enfatizza contesti estremamente lunghi e orchestrazione multi‑agente come elementi differenzianti. In breve: GPT‑5.3 sembra ottimizzato per profondità ingegneristica “grezza” e dominio dei benchmark su test centrati sugli sviluppatori; Opus 4.6 enfatizza l’ampiezza su flussi di lavoro enterprise a lungo contesto e ragionamento di dominio.
Opus 4.6 vs Google Gemini 3?
Il Gemini 3 di Google (e le varianti Gemini 3 Pro / Deep Think) è stato messo in luce per le ottime prestazioni nel ragionamento astratto, nella risoluzione di problemi visivi e in alcuni benchmark di QA scientifica; ha inoltre spinto più avanti il ragionamento multimodale avanzato rispetto ai predecessori. La copertura posiziona Gemini 3 come particolarmente forte nelle suite di ragionamento scientifico e visivo, mentre il punto di forza di Opus 4.6 è nel codice a lungo contesto e nel lavoro legale/enterprise. Per le organizzazioni che necessitano di ragionamento scientifico multimodale o di compiti avanzati di logica visiva, Gemini 3 può avere un vantaggio; per lavoro conoscitivo sostenuto a lungo contesto e automazione multi‑agente, Opus 4.6 rivendica una posizione.
Chi “vince” nei testa‑a‑testa?
Nessun fornitore “vince” universalmente: la scelta dipende dal flusso di lavoro che ti interessa. Le prime comparazioni indipendenti mostrano Opus 4.6 superare Opus 4.5 con un margine significativo nei compiti a lungo orizzonte e di dominio, mentre GPT‑5.3 e Gemini 3 mantengono vantaggi in alcune prove di coding e multimodali. Come in ogni generazione in rapida evoluzione, il vincitore è il cliente che mappa i punti di forza del modello su carichi di lavoro e integrazioni di tooling reali, non il modello con il singolo benchmark più alto.
Vale la pena di Claude Opus 4.6?
Risposta breve: Sì — se i tuoi problemi principali sono ragionamento a lungo contesto, flussi di lavoro con agenti autonomi o conformità enterprise. I punti di forza di Opus 4.6 sono reali e rilevanti: le finestre da 200K (e 1M in beta), l’adaptive thinking, i team di agenti e le integrazioni enterprise sono upgrade tangibili che riducono la complessità di ingegneria del prodotto e aumentano la classe di problemi che puoi automatizzare.
Se invece il tuo carico di lavoro è prevalentemente composto da micro‑attività brevi e altamente ripetitive, dove costo unitario e latenza sono fondamentali, Opus 4.6 può essere eccessivo rispetto a un modello specialista a corto orizzonte (ad es., GPT‑5.3 Codex) — a meno che tu non preveda di combinarli e instradare i compiti in modo appropriato.
CometAPI è una piattaforma di aggregazione tutto‑in‑uno per API di modelli di grandi dimensioni, che offre integrazione e gestione senza soluzione di continuità dei servizi API. Supporta l’invocazione di vari modelli di AI mainstream. Ciò include generazione di immagini, generazione di video, chat, TTS e STT AI, tutto su un’unica piattaforma.
Puoi anche scegliere il modello che desideri in base al costo e alle capacità, e passare da uno all’altro in qualsiasi momento, ad esempio Gemini 3 Flash, GPT 5.3 o Opus 4.6. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo di gran lunga inferiore a quello ufficiale per aiutarti nell’integrazione.
Pronto a iniziare?→ Registrati per iniziare a programmare oggi !
Se vuoi conoscere altri consigli, guide e notizie sull’AI, seguici su VK, X e Discord!