

Kling O1, rilasciato durante la settimana di lancio di "Omni" di Kling AI, si posiziona come un modello di base video multimodale unificato che accetta testo, immagini e video nella stessa richiesta e può sia generare che modificare video in flussi di lavoro iterativi a livello di regista. Il team di Kling definisce O1 come "il primo modello video multimodale unificato su larga scala al mondo". I test interni di Kling vantano notevoli vittorie rispetto a Veo 3.1 e Runway Aleph di Google.
Che cos'è Kling O1?
Kling O1 (spesso commercializzato come Video O1 or Omni Uno) è un modello di base video di recente rilascio di Kling AI che unifica la generazione e l'editing di testo, immagini e video all'interno di un unico framework basato su prompt. Anziché trattare la conversione da testo a video, da immagine a video e l'editing video come pipeline separate, Kling O1 accetta input misti (testo + più immagini + video di riferimento opzionale) in un unico prompt, li elabora e produce brevi clip coerenti o modifica filmati esistenti con un controllo granulare. L'azienda ha posizionato il lancio come parte di un "Omni Launch" e descrive O1 come un "motore video multimodale" costruito attorno a un paradigma di Linguaggio Visuale Multimodale (MVL) e a un percorso di ragionamento Chain-of-Thought (CoT) per interpretare istruzioni creative complesse e composte da più parti.
Il messaggio di Kling enfatizza tre flussi di lavoro pratici: (1) generazione testo → video, (2) immagine/elemento → video (composizione e scambio soggetto/oggetto di scena utilizzando riferimenti espliciti) e (3) editing video/continuazione delle riprese (restyling, aggiunta/rimozione di oggetti, controllo di inizio/fine fotogramma). Il modello supporta prompt multi-elemento (inclusa una sintassi "@" per il targeting di immagini di riferimento specifiche) e offre controlli in stile regista come l'ancoraggio di inizio/fine fotogramma e la continuazione video per creare sequenze multi-ripresa.
5 punti salienti di Kling O1
1) Vero input multimodale unificato (MVL)
La funzionalità di punta di Kling O1 è la gestione di testo, immagini fisse (riferimenti multipli) e video come input simultanei di prima classe. Gli utenti possono fornire diverse immagini di riferimento (o una breve clip di riferimento). e al un'istruzione in linguaggio naturale; il modello analizzerà tutti gli input insieme per produrre o modificare un output coerente. Ciò riduce l'attrito della catena di strumenti e consente flussi di lavoro come "usa soggetto da @image1, posizionarli nell'ambiente da @image2, abbina il movimento a ref_video.mp4e applicare la gradazione cromatica cinematografica X." Questa inquadratura "Multimodal Visual Language" (MVL) è fondamentale per il discorso di Kling.
Perché è importante: I veri flussi di lavoro creativi spesso richiedono la combinazione di riferimenti: un personaggio da una risorsa, un movimento di telecamera da un'altra e un'istruzione narrativa nel testo. Unificare questi input consente la generazione in un unico passaggio e riduce i passaggi di composizione manuale.
2) Modifica + generazione in un modello (modalità multi-elementi)
La maggior parte dei sistemi precedenti separava la generazione (testo→video) dal montaggio preciso al fotogramma. O1 li combina intenzionalmente: lo stesso modello che crea una clip da zero può anche modificare il girato esistente, sostituendo oggetti, modificando gli abiti, rimuovendo oggetti di scena o estendendo una ripresa, il tutto tramite istruzioni in linguaggio naturale. Questa convergenza semplifica notevolmente il flusso di lavoro per i team di produzione.
Il modello O1 realizza una profonda integrazione di molteplici attività video al suo interno:
- Generazione di testo in video
- Generazione di riferimenti immagine/soggetto
- Montaggio video e ritocco pittorico
- Restyling video
- Generazione di scatti successivi/precedenti
- Generazione video vincolata ai fotogrammi chiave
Il significato più importante di questo progetto risiede nel fatto che processi complessi che in precedenza richiedevano più modelli o strumenti indipendenti possono ora essere completati all'interno di un unico motore. Questo non solo riduce significativamente i costi di creazione e di calcolo, ma getta anche le basi per lo sviluppo di un "modello unificato di comprensione e generazione video".
3) La coerenza della generazione video
Coerenza dell'identità: Il modello O1 migliora le capacità di modellazione della coerenza cross-modale, mantenendo la stabilità della struttura, del materiale, dell'illuminazione e dello stile del soggetto di riferimento durante il processo di generazione:
- Supporta immagini di riferimento multi-vista per la modellazione del soggetto;
- supporta la coerenza del soggetto tra inquadrature incrociate (caratteri, oggetti e caratteristiche della scena rimangono costanti nelle diverse inquadrature);
- supporta riferimenti ibridi multi-soggetto, consentendo la generazione di ritratti di gruppo e la costruzione di scene interattive.
Questo meccanismo migliora significativamente la coerenza e la "consistenza dell'identità" della generazione video, rendendolo adatto a scenari con requisiti di coerenza estremamente elevati, come la pubblicità e la generazione di riprese a livello cinematografico.
Memoria migliorata: Il modello O1 possiede anche una "memoria", che impedisce che il suo stile di output diventi instabile a causa di contesti lunghi o istruzioni variabili. Può persino:
- ricordare più caratteri contemporaneamente;
- consentire a diversi personaggi di interagire nel video;
- mantenere coerenza nello stile, nell'abbigliamento e nella postura.
4) Composizione precisa con sintassi “@” e controllo del fotogramma iniziale/finale
Kling ha introdotto una scorciatoia di composizione (segnalata come sistema di menzione "@") in modo da poter fare riferimento a immagini specifiche nel prompt (ad esempio, @image1, @image2) per assegnare ruoli alle risorse in modo affidabile. In combinazione con la specifica esplicita dei fotogrammi di inizio e fine, questo consente al regista di controllare come gli elementi si muovono, si muovono o si trasformano nella clip generata: un set di funzionalità incentrato sulla produzione che differenzia O1 da molti generatori orientati al consumatore.
5) Alta fedeltà, uscite lunghe e stacking multi-task
Si dice che Kling O1 produca output cinematografici a 1080p (30 fps) e, con le precedenti versioni di Kling che hanno aperto la strada, l'azienda promuove la generazione di clip più lunghe (riportando fino a 2 minuti nelle recenti recensioni di prodotto). Supporta inoltre l'aggregazione di più attività creative in un'unica richiesta (generazione, aggiunta di un soggetto, modifica dell'illuminazione e modifica della composizione). Queste proprietà lo rendono competitivo con i motori testo→video di livello superiore.
Perché è importante: clip più lunghe e ad alta fedeltà e la possibilità di combinare i montaggi riducono la necessità di unire insieme numerose clip brevi e semplificano la produzione end-to-end.
Come è strutturato Kling O1 e quali sono i meccanismi sottostanti?
O1 intorno a un Linguaggio visivo multimodale (MVL) nucleo: un modello che apprende incorporamenti congiunti per segnali di linguaggio + immagini + movimento (fotogrammi video e caratteristiche in stile flusso ottico), e quindi applica decodificatori basati su diffusione o trasformatore per sintetizzare fotogrammi temporalmente coerenti. Il modello è descritto come esecutivo condizionata su più riferimenti (testo; immagini uno-a-molti; brevi videoclip) per produrre una rappresentazione video latente che viene poi decodificata in immagini per fotogramma, preservando la coerenza temporale tramite attenzione cross-frame o moduli temporali specializzati.
1. Trasformatore multimodale + architettura a contesto lungo
Il modello O1 impiega l'architettura Transformer multimodale sviluppata autonomamente da Keling, integrando segnali di testo, immagine e video e supportando la memoria di contesto temporale lungo (Multimodal Long Context).
Ciò consente al modello di comprendere la continuità temporale e la coerenza spaziale durante la generazione del video.
2. MVL: Linguaggio visivo multimodale
MVL è l'innovazione fondamentale di questa architettura.
Allinea profondamente il linguaggio e i segnali visivi all'interno del Transformer attraverso uno strato intermedio semantico unificato, in tal modo:
- Consentire a una singola casella di input di combinare istruzioni multimodali;
- Migliorare la comprensione accurata delle descrizioni in linguaggio naturale da parte del modello;
- Supporta la generazione di video interattivi altamente flessibili.
L'introduzione di MVL segna un cambiamento nella generazione di video da "guidati dal testo" a "guidati congiuntamente da semantica e visuale".
3. Meccanismo di inferenza della catena di pensiero
Il modello O1 introduce un percorso di inferenza "Chain-of-Thought" durante la fase di generazione del video.
Questo meccanismo consente al modello di eseguire la logica degli eventi e la deduzione temporale prima della generazione, mantenendo così una connessione naturale tra azioni ed eventi all'interno del video.
Pipeline di inferenza e modifica
- Generation: feed: (testo + riferimenti immagine facoltativi + riferimenti video facoltativi + impostazioni di generazione) → il modello produce fotogrammi video latenti → decodifica in fotogrammi → post-elaborazione colore/temporale facoltativa.
- Modifica basata sulle istruzioni: Feed: (video originale + istruzioni di testo + riferimenti immagine opzionali) → il modello mappa internamente la modifica richiesta a un insieme di trasformazioni pixel-space e quindi sintetizza i frame modificati preservando il contenuto invariato. Poiché tutto è in un unico modello, gli stessi moduli di condizionamento e temporali vengono utilizzati sia per la creazione che per la modifica.
Kling Viedo o1 contro Veo 3.1 contro Runway Aleph
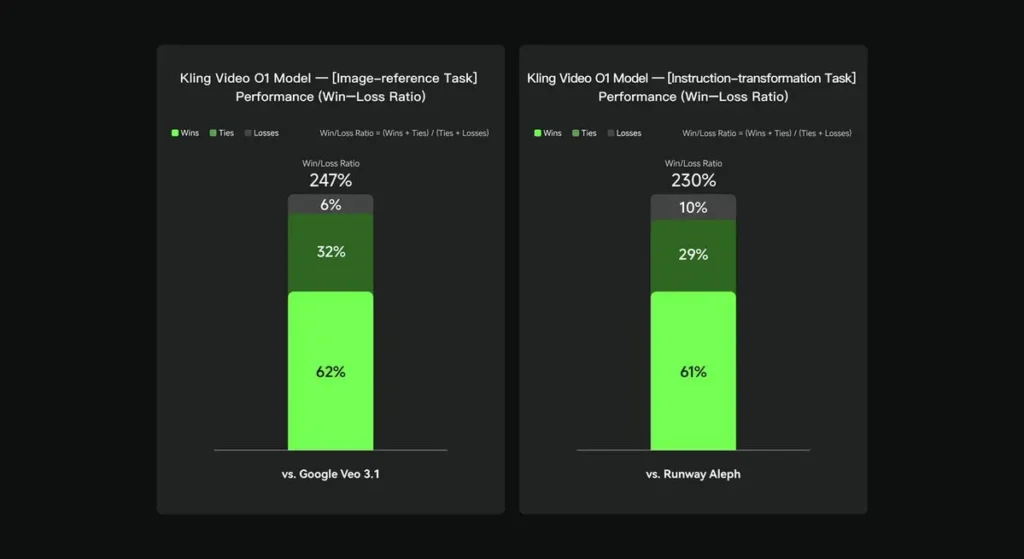
Nelle valutazioni interne, Keling Video O1 ha ottenuto risultati significativamente superiori rispetto alle controparti internazionali esistenti in diversi aspetti chiave. Risultati delle prestazioni (basati sul set di valutazione auto-costruito da Keling AI):
- Attività di "riferimento immagine": O1 supera Google Veo 3.1 nel complesso, con un tasso di vincita del 247%;
- Attività di "Trasformazione delle istruzioni": O1 supera Runway Aleph, con una percentuale di vittorie del 230%.
Istantanea del concorrente (confronto a livello di funzionalità)
| Capacità / Modello | Kling O1 | Google Veo 3.1 | Pista (Aleph / Gen-4.5) |
|---|---|---|---|
| Prompt multimodale unificato (testo+immagini+video) | Sì (argomento di vendita principale). flussi multimodali a richiesta singola. | Parziale: esistono testo→video + riferimenti; minore enfasi su un singolo MVL unificato. | Runway si concentra su generazione + editing, ma spesso come modalità separate; l'ultima Gen-4.5 riduce il divario. |
| Modifiche pixel basate su testo/conversazione | Si — “modifica come una conversazione” (senza maschere). | Parziale: la modifica esiste, ma i flussi di lavoro basati su maschera/fotogramma chiave sono ancora comuni. | Runway è dotato di potenti strumenti di modifica; Runway vanta potenti trasformazioni delle istruzioni (varia a seconda della versione). |
| Controllo inizio/fine fotogramma e riferimento telecamera | Si — descrizione esplicita dei movimenti di inizio/fine fotogramma e della telecamera di riferimento. | Limitato / in evoluzione | Pista: controlli migliorati; l'esperienza utente non è esattamente la stessa. |
| Generazione di clip lunghe (alta fedeltà) | fino a ~2 minuti (1080p, 30 fps) nei materiali dei prodotti e nei post della community; | Veo 3.1: forte coerenza, ma le versioni precedenti avevano valori predefiniti più brevi; varia a seconda del modello/impostazione. | Runway Gen-4.5: punta molto sulla qualità; lunghezza/fedeltà variabili. |
Conclusione:
La fama pubblica di Kling O1 è unificazione del flusso di lavoro: affidare a un singolo modello il compito di comprendere testo, immagini e video e di eseguire sia la generazione che l'editing basato su istruzioni avanzate all'interno dello stesso sistema semantico. Per i creatori e i team che si muovono frequentemente tra le fasi di "creazione", "modifica" ed "estensione", tale consolidamento può semplificare notevolmente la velocità di iterazione e la complessità degli strumenti. Maggiore coerenza temporale, controllo dei frame di inizio/fine e integrazioni pragmatiche della piattaforma che lo rendono accessibile ai creatori.
L'API Kling Video o1 sarà presto disponibile su CometAPI.
Gli sviluppatori possono accedere Kling 2.5 Turb e al API di Veo 3.1 attraverso CometaAPI, gli ultimi modelli elencati sono quelli aggiornati alla data di pubblicazione dell'articolo. Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!