

Il 17 giugno, l'unicorno dell'intelligenza artificiale di Shanghai MiniMax ha ufficialmente reso open source MiniMax‑M1, il primo modello di inferenza ibrido-attenzionale open-weight su larga scala al mondo. Combinando un'architettura Mixture-of-Experts (MoE) con il nuovo meccanismo Lightning Attention, MiniMax-M1 offre notevoli miglioramenti in termini di velocità di inferenza, gestione di contesti ultra-lunghi e prestazioni in attività complesse.
Contesto ed evoluzione
Costruire sulle fondamenta di MiniMax-Testo-01, che ha introdotto un'attenzione particolare a un framework Mixture-of-Experts (MoE) per raggiungere contesti da 1 milione di token durante l'addestramento e fino a 4 milioni di token in fase di inferenza, MiniMax-M1 rappresenta la nuova generazione della serie MiniMax-01. Il modello precedente, MiniMax-Text-01, conteneva 456 miliardi di parametri totali con 45.9 miliardi di token attivati per token, dimostrando prestazioni pari a quelle dei LLM di livello superiore e ampliando notevolmente le capacità di contesto.
Caratteristiche principali di MiniMax‑M1
- MoE ibrido + attenzione ai fulmini: MiniMax‑M1 fonde un design sparso di tipo Mixture‑of‑Experts (456 miliardi di parametri totali, ma solo 45.9 miliardi attivati per token) con Lightning Attention, un'attenzione a complessità lineare ottimizzata per sequenze molto lunghe.
- Contesto ultra-lungo: Supporta fino a 1 milioni token di input, circa otto volte il limite di 128 K di DeepSeek-R1, che consentono una comprensione approfondita di documenti di grandi dimensioni.
- Efficienza superiore: Quando si generano 100 K token, Lightning Attention di MiniMax‑M1 richiede solo circa il 25-30% della potenza di calcolo utilizzata da DeepSeek‑R1.
Varianti del modello
- MiniMax‑M1‑40K: 1 M contesto token, 40 K budget di inferenza token
- MiniMax‑M1‑80K: 1 M contesto token, 80 K budget di inferenza token
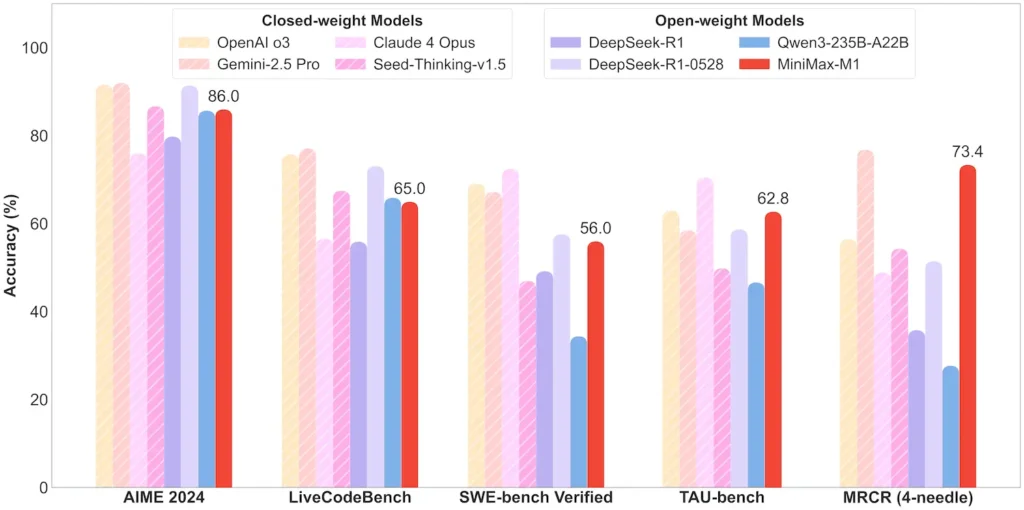
Negli scenari di utilizzo degli strumenti TAU-bench, la variante 40K ha superato in prestazioni tutti i modelli open-weight, incluso Gemini 2.5 Pro, dimostrando le sue capacità di agente.
Costi e configurazione della formazione
MiniMax-M1 è stato addestrato end-to-end utilizzando l'apprendimento per rinforzo (RL) su larga scala in una serie diversificata di attività, dal ragionamento matematico avanzato agli ambienti di ingegneria del software basati su sandbox. Un nuovo algoritmo, CISPO (Clipped Importance Sampling for Policy Optimization) migliora ulteriormente l'efficienza dell'addestramento ritagliando i pesi del campionamento di importanza anziché gli aggiornamenti a livello di token. Questo approccio, combinato con l'attenzione fulminea del modello, ha permesso di completare l'addestramento RL completo su 512 GPU H800 in sole tre settimane, con un costo di noleggio totale di 534,700 dollari.
Disponibilità e prezzi
MiniMax-M1 viene rilasciato sotto la Apache 2.0 licenza open source ed è immediatamente accessibile tramite:
- Repository GitHub, inclusi pesi del modello, script di addestramento e benchmark di valutazione.
- SilicioCloud hosting, offrendo due varianti: token da 40 K ("M1-40K") e token da 80 K ("M1-80K"), con l'intenzione di abilitare l'intero funnel di token da 1 M.
- Il prezzo è attualmente fissato a 4 yen per milione token per input e 16 yen per milione token per l'output, con sconti sul volume disponibili per i clienti aziendali.
Sviluppatori e organizzazioni possono integrare MiniMax-M1 tramite API standard, ottimizzarlo in base a dati specifici del dominio o distribuirlo in locale per carichi di lavoro sensibili.
Prestazioni a livello di attività
| Categoria di attività | In evidenza | Prestazioni relative |
|---|---|---|
| Matematica e logica | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; quasi closed‑source |
| Comprensione del contesto lungo | Sovrano (4 gettoni K–1 M): Livello superiore stabile | Supera GPT‑4 oltre la lunghezza del token di 128 K |
| Software Engineering | SWE-bench (bug reali di GitHub): 56% | Il migliore tra i modelli aperti; 2° dopo i modelli chiusi leader |
| Utilizzo di agenti e strumenti | TAU-bench (simulazione API) | 62–63.5% rispetto a Gemini 2.5, Claude 4 |
| Dialogo e assistente | MultiChallenge: 44.7% | Corrisponde a Claude 4, DeepSeek‑R1 |
| Controllo qualità dei fatti | SimpleQA: 18.5% | Area di miglioramento futuro |
Nota: percentuali e parametri di riferimento tratti dalle informazioni ufficiali di MiniMax e da resoconti giornalistici indipendenti
Innovazioni tecniche
- Stack di attenzione ibrido: Attenzione fulminea strati (costo lineare) intervallati da Softmax Attention periodico (quadratico ma più espressivo) per bilanciare efficienza e potenza di modellazione.
- Routing MoE sparso: 32 moduli esperti; ogni token attiva solo circa il 10% dei parametri totali, riducendo i costi di inferenza e preservando la capacità.
- Apprendimento per rinforzo CISPO: Un nuovo algoritmo di "ottimizzazione della politica del peso IS ritagliato" che conserva token rari ma cruciali nel segnale di apprendimento, accelerando la stabilità e la velocità RL.
La versione open-weight di MiniMax-M1 consente a tutti di accedere a un'inferenza ad alta efficienza e a contesti ultra-lunghi, colmando il divario tra la ricerca e l'intelligenza artificiale su larga scala implementabile.
Iniziamo
CometAPI fornisce un'interfaccia REST unificata che aggrega centinaia di modelli di intelligenza artificiale, inclusa la famiglia ChatGPT, in un endpoint coerente, con gestione integrata delle chiavi API, quote di utilizzo e dashboard di fatturazione. Questo significa che non dovrete più destreggiarvi tra URL e credenziali di più fornitori.
Per iniziare, esplora le capacità dei modelli in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API.
L'ultima integrazione dell'API MiniMax‑M1 apparirà presto su CometAPI, quindi rimanete sintonizzati! Mentre finalizziamo il caricamento del modello MiniMax‑M1, esplorate i nostri altri modelli su Pagina dei modelli oppure provali nel Parco giochi AIL'ultimo modello di MiniMax in CometAPI è API di anteprima ABAB7 di Minimax e al API MiniMax Video-01 ,fare riferimento a:
