Gemini 2.5 Flash è progettato per fornire risposte rapide senza compromettere la qualità dell'output. Supporta input multimodali, inclusi testo, immagini, audio e video, rendendolo adatto a diverse applicazioni. Il modello è accessibile tramite piattaforme come Google AI Studio e Vertex AI, offrendo agli sviluppatori gli strumenti necessari per un'integrazione fluida in vari sistemi.
Informazioni di base (Funzionalità)
Gemini 2.5 Flash introduce diverse funzionalità di spicco che lo distinguono all'interno della famiglia Gemini 2.5:
- Ragionamento ibrido: Gli sviluppatori possono impostare un parametro thinking_budget per controllare con precisione quanti token il modello dedica al ragionamento interno prima dell'output .
- Frontiera di Pareto: Posizionato nel punto ottimale costo-prestazioni, Flash offre il miglior rapporto prezzo-intelligenza tra i modelli 2.5 .
- Supporto multimodale: Elabora in modo nativo testo, immagini, video e audio, abilitando capacità conversazionali e analitiche più ricche .
- Contesto da 1 milione di token: Una lunghezza del contesto senza pari consente un'analisi approfondita e la comprensione di documenti lunghi in una singola richiesta .
Versioni del modello
Gemini 2.5 Flash è passato attraverso le seguenti versioni chiave:
- gemini-2.5-flash-lite-preview-09-2025: Usabilità degli strumenti migliorata: prestazioni migliori su attività complesse e multi-step, con un incremento del 5% nei punteggi SWE-Bench Verified (dal 48.9% al 54%). Efficienza migliorata: abilitando il ragionamento, si ottiene un output di qualità superiore con meno token, riducendo latenza e costi.
- Anteprima 04-17: versione di accesso anticipato con funzionalità di “thinking”, disponibile tramite gemini-2.5-flash-preview-04-17.
- Disponibilità generale stabile (GA): Dal 17 giugno 2025, l'endpoint stabile gemini-2.5-flash sostituisce la preview, garantendo affidabilità a livello di produzione senza modifiche all'API rispetto alla preview del 20 maggio .
- Deprecazione della preview: Gli endpoint di preview erano programmati per l'arresto il 15 luglio 2025; gli utenti devono migrare all'endpoint GA prima di questa data .
A luglio 2025, Gemini 2.5 Flash è ora disponibile pubblicamente e stabile (nessuna modifica rispetto a gemini-2.5-flash-preview-05-20 ).Se stai utilizzando gemini-2.5-flash-preview-04-17, il pricing di preview esistente continuerà fino alla dismissione programmata dell'endpoint del modello il 15 luglio 2025, quando verrà chiuso. Puoi migrare al modello generalmente disponibile "gemini-2.5-flash" .
Più veloce, più economico, più intelligente:
- Obiettivi di progettazione: bassa latenza + alto throughput + basso costo;
- Accelerazione complessiva nel ragionamento, nell'elaborazione multimodale e nei compiti su testi lunghi;
- L'uso dei token è ridotto del 20–30%, riducendo significativamente i costi di ragionamento.
Specifiche tecniche
Finestra di contesto in input: Fino a 1 milione di token, consentendo un'ampia conservazione del contesto.
Token di output: In grado di generare fino a 8,192 token per risposta.
Modalità supportate: Testo, immagini, audio e video.
Piattaforme di integrazione: Disponibile tramite Google AI Studio e Vertex AI.
Prezzi: Modello di pricing competitivo basato sui token, che facilita un'adozione conveniente.
Dettagli tecnici
Sotto il cofano, Gemini 2.5 Flash è un modello di linguaggio di grandi dimensioni basato su transformer addestrato su un mix di dati da web, codice, immagini e video. Le principali specifiche tecniche includono:
Addestramento multimodale: Addestrato per allineare più modalità, Flash può combinare senza soluzione di continuità testo con immagini, video o audio, utile per attività come il riassunto di video o la didascalia audio .
Processo di pensiero dinamico: Implementa un ciclo di ragionamento interno in cui il modello pianifica e scompone prompt complessi prima dell'output finale .
Budget di pensiero configurabili: Il thinking_budget può essere impostato da 0 (nessun ragionamento) fino a 24,576 token, consentendo compromessi tra latenza e qualità della risposta .
Integrazione con strumenti: Supporta Grounding con Google Search, esecuzione di codice, contesto da URL e chiamata di funzioni, abilitando azioni nel mondo reale direttamente da prompt in linguaggio naturale .
Prestazioni nei benchmark
In valutazioni rigorose, Gemini 2.5 Flash dimostra prestazioni leader nel settore:
- LMArena Hard Prompts: Ha ottenuto un punteggio secondo solo a 2.5 Pro nel difficile benchmark Hard Prompts, mostrando solide capacità di ragionamento multi-step .
- Punteggio MMLU di 0.809: Supera le prestazioni medie dei modelli con un'accuratezza MMLU di 0.809, riflettendo l'ampia conoscenza dei domini e le capacità di ragionamento .
- Latenza e throughput: Raggiunge una velocità di decodifica di 271.4 token/sec con un Time-to-First-Token di 0.29 s, rendendolo ideale per carichi di lavoro sensibili alla latenza.
- Leader prezzo-prestazioni: A \$0.26/1 M tokens, Flash batte molti concorrenti pur eguagliandoli o superandoli nei benchmark chiave .
Questi risultati indicano il vantaggio competitivo di Gemini 2.5 Flash nel ragionamento, nella comprensione scientifica, nella risoluzione di problemi matematici, nella programmazione, nell'interpretazione visiva e nelle capacità multilingue:
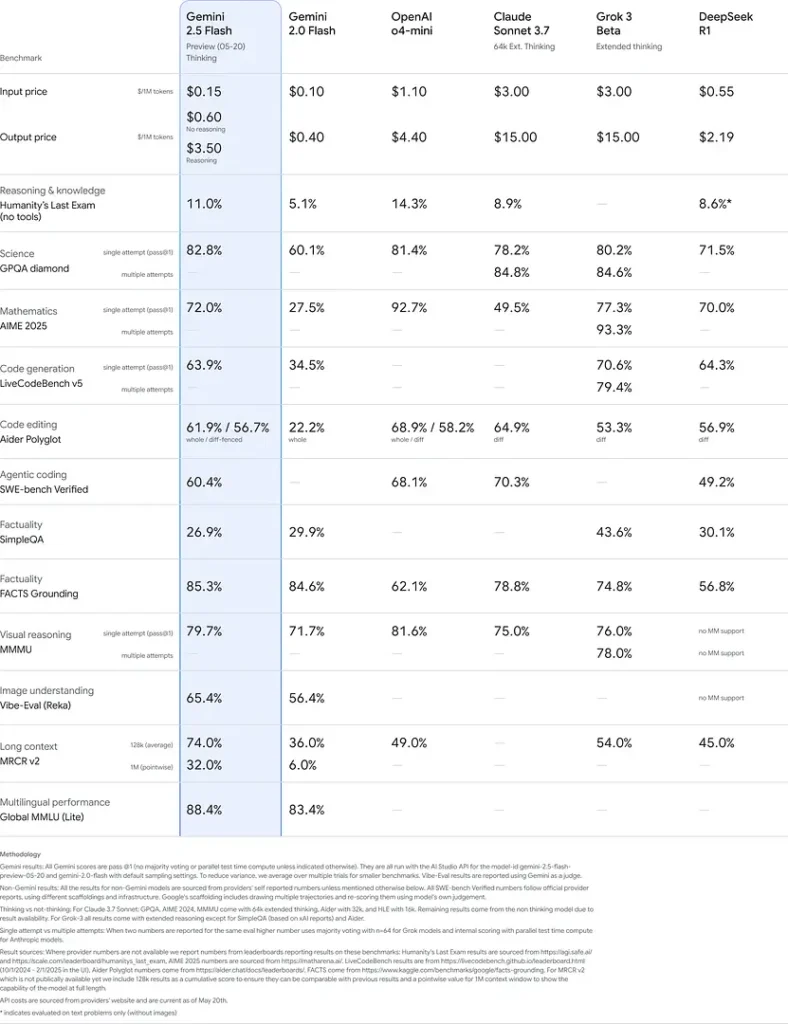
Limitazioni
Sebbene potente, Gemini 2.5 Flash presenta alcune limitazioni:
- Rischi per la sicurezza: Il modello può mostrare un tono “moralistico” e può produrre output plausibili ma errati o distorti (allucinazioni), in particolare su query di casi limite. Un rigoroso controllo umano rimane essenziale.
- Limiti di frequenza: L'uso dell'API è vincolato da limiti di frequenza (10 RPM, 250,000 TPM, 250 RPD sui livelli predefiniti), che possono influenzare l'elaborazione in batch o le applicazioni ad alto volume.
- Livello minimo di intelligenza: Pur essendo eccezionalmente capace per un modello flash, rimane meno accurato di 2.5 Pro nei compiti basati su agenti più impegnativi, come la programmazione avanzata o il coordinamento multi-agente.
- Compromessi sui costi: Pur offrendo il miglior rapporto prezzo-prestazioni, l'uso esteso della modalità thinking aumenta il consumo complessivo di token, incrementando i costi per i prompt che richiedono ragionamenti approfonditi .