Dettagli tecnici
- Ragionamento adattivo:
Gemini 2.5 Flash-Litesupporta il ragionamento on-demand, consentendo agli sviluppatori di allocare risorse di calcolo solo quando è richiesto un ragionamento più profondo. - Integrazioni degli strumenti: Piena compatibilità con gli strumenti nativi di Gemini 2.5, inclusi Grounding with Google Search, Code Execution, URL Context e Function Calling per workflow multimodali senza soluzione di continuità.
- Model Context Protocol (MCP): Sfrutta l’MCP di Google per recuperare dati web in tempo reale, garantendo risposte aggiornate e contestualmente pertinenti.
- Opzioni di deployment: Disponibile tramite CometAPI, Gemini API, Vertex AI e Google AI Studio, con una traccia di anteprima per early adopter che desiderano sperimentare e fornire feedback.
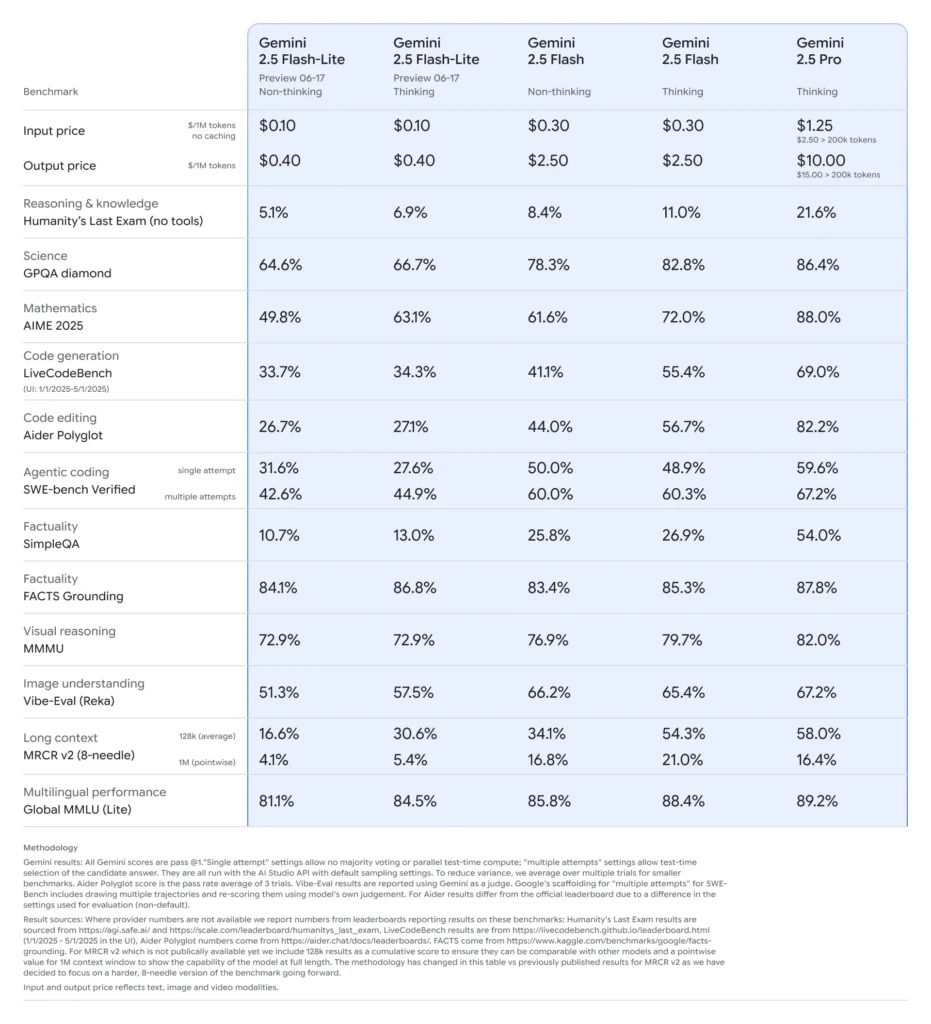
Prestazioni benchmark di Gemini 2.5 Flash-Lite
- Latenza: Ottiene fino al 50% di riduzione dei tempi di risposta mediani rispetto a Gemini 2.5 Flash, con latenze tipiche inferiori a 100 ms su benchmark standard di classificazione e sintesi.
- Throughput: Ottimizzato per carichi ad alto volume, sostenendo decine di migliaia di richieste al minuto senza degrado delle prestazioni.
- Prezzo-prestazioni: Dimostra una riduzione del 25% del costo per 1.000 token rispetto alla controparte Flash, rendendolo la scelta Pareto-ottimale per deployment sensibili ai costi.
- Adozione nel settore: I primi utenti riportano un’integrazione senza attriti nelle pipeline di produzione, con metriche prestazionali in linea con o superiori alle proiezioni iniziali.
Casi d’uso ideali
- Attività ad alta frequenza e bassa complessità: etichettatura automatizzata, analisi del sentiment e traduzione in batch
- Pipeline sensibili ai costi: estrazione di dati da ampi corpora documentali, sintesi periodica in batch
- Scenari edge e mobile: quando la latenza è critica ma i budget di risorse sono limitati
Limitazioni di Gemini 2.5 Flash-Lite
- Stato di anteprima: potrebbe subire modifiche all’API prima della GA; le integrazioni dovrebbero tenere conto di possibili incrementi di versione.
- Nessun fine-tuning al volo: non è possibile caricare pesi personalizzati; fare affidamento su prompt engineering e messaggi di sistema.
- Creatività ridotta: ottimizzato per attività deterministiche e ad alto throughput; meno adatto alla generazione open-ended o alla scrittura “creativa”.
- Limite di risorse: scala linearmente solo fino a ~16 vCPUs; oltre questa soglia, i guadagni di throughput diminuiscono.
- Vincoli multimodali: supporta input immagine/audio ma con fedeltà limitata; non ideale per compiti impegnativi di visione o trascrizione audio.
- Compromesso sulla finestra di contesto: anche se accetta fino a 1 M token, in pratica l’inferenza a quella scala può presentare un throughput degradato.