Specifiche tecniche di GPT-5.4 Mini
| Voce | GPT-5.4 Mini (stima da fonti ufficiali + convalida incrociata) |
|---|---|
| Famiglia di modelli | Serie GPT-5.4 (variante “mini” a costi contenuti) |
| Fornitore | OpenAI |
| Tipi di input | Testo, Immagine |
| Tipi di output | Testo |
| Finestra di contesto | 400,000 tokens |
| Token massimi in output | 128,000 tokens |
| Data di aggiornamento della conoscenza | ~31 maggio 2024 (eredita la linea mini) |
| Supporto al ragionamento | Sì (leggero rispetto al GPT-5.4 completo) |
| Supporto agli strumenti | Chiamate di funzione, ricerca web, ricerca di file, agenti (inferito dalla famiglia GPT-5) |
| Posizionamento | Modello quasi di frontiera, ad alta velocità e a costi contenuti |
Che cos'è GPT-5.4 Mini?
GPT-5.4 Mini è una variante di GPT-5.4 ad alta velocità e a costi contenuti, progettata per carichi di lavoro sensibili alla latenza e ad alto volume. Porta una parte significativa delle capacità di ragionamento, coding e multimodali di GPT-5.4 in un modello più piccolo e più veloce, ottimizzato per sistemi in produzione su larga scala.
Rispetto ai precedenti modelli “mini”, GPT-5.4 Mini è posizionato come un piccolo modello quasi di frontiera, il che significa che si avvicina alle prestazioni del modello di punta riducendo drasticamente costi e tempi di risposta.
Caratteristiche principali di GPT-5.4 Mini
- Inferenza ad alta velocità: ottimizzato per applicazioni a bassa latenza come chatbot, copilots e sistemi in tempo reale
- Ampia finestra di contesto (400K): supporta documenti lunghi, workflow multi-step e memoria degli agenti
- Solido supporto per coding e agenti: progettato per l’uso di strumenti, il ragionamento multi-step e compiti delegati a sottoagenti
- Input multimodale: accetta input sia testuali sia di immagini per workflow più ricchi
- Scalabilità economica: significativamente più economico di GPT-5.4 mantenendo una forte capacità di ragionamento
- Ottimizzazione della pipeline di agenti: ideale per architetture multi-modello in cui i modelli grandi pianificano e i modelli mini eseguono
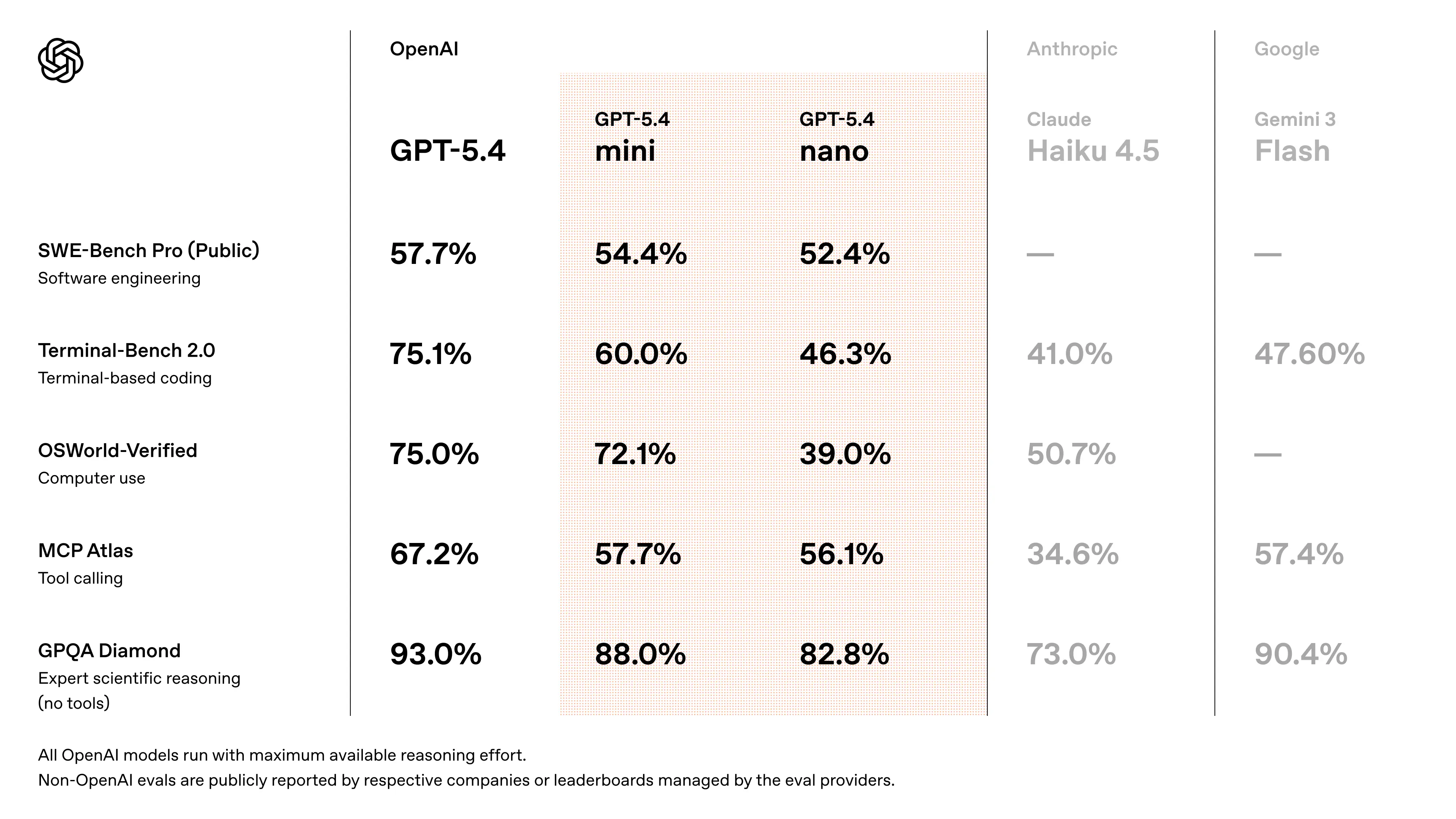
Prestazioni nei benchmark di GPT-5.4 Mini
- Si avvicina alle prestazioni di GPT-5.4 nelle attività di coding in stile SWE-Bench (~94–95% delle prestazioni del modello di punta) (stima convalidata incrociando discussioni sul rilascio)
- Miglioramenti significativi rispetto a GPT-5 Mini in:
- accuratezza del ragionamento
- affidabilità nell’uso degli strumenti
- comprensione multimodale
- Progettato per superare le precedenti generazioni “mini” nei workflow basati su agenti e nei benchmark di coding
- Misurazioni di velocità: i primi tester API riportano ~180–190 tokens/sec su GPT-5.4 Mini (vs ~55–120 t/s per le varianti GPT-5 mini più datate a seconda delle modalità di priorità).
👉 Punto chiave: GPT-5.4 Mini offre prestazioni quasi di frontiera a una frazione di costo e latenza, rendendolo ideale per sistemi scalabili.
Casi d'uso rappresentativi
- Assistant e editor di codice (plugin IDE, Copilot): parsing veloce del contesto, esplorazione del codebase e completamenti rapidi rendono GPT-5.4 Mini ideale per suggerimenti in-editor, dove il time-to-first-token è cruciale. GitHub Copilot è una delle prime integrazioni.
- Sottoagenti / worker delegati: quando un agente principale delega compiti brevi e veloci (formattazione, piccoli passaggi di ragionamento, ricerche in stile grep) a un worker economico e rapido. OpenAI posiziona mini/nano per questi ruoli.
- Automazione API ad alto volume: generazione di codice in bulk, triage automatico dei ticket, sintesi dei log su larga scala, dove costo per chiamata e latenza sono vincoli primari. Le metriche di throughput della community indicano vantaggi operativi tangibili per la versione mini.
- Tool-wrapping e toolchain: chiamate a strumenti veloci in cui il modello orchestra chiamate a strumenti esterni (search, grep, esecuzione test) e restituisce output compatti e azionabili. La famiglia GPT-5.4 include capacità migliorate di “computer use”.
Come accedere all'API di GPT-5.4 Mini
Passaggio 1: Registrati per ottenere una chiave API
Accedi a cometapi.com. Se non sei ancora un nostro utente, registrati prima. Accedi alla tua CometAPI console. Ottieni la credenziale di accesso (API key) dell’interfaccia. Fai clic su “Add Token” nella sezione API token del centro personale, ottieni la chiave del token: sk-xxxxx e invia.

Passaggio 2: Invia richieste all'API di GPT-5.4 Mini
Seleziona l’endpoint “gpt-5.4-mini” per inviare la richiesta API e imposta il corpo della richiesta. Il metodo e il corpo della richiesta sono disponibili nella documentazione API sul nostro sito. Il nostro sito fornisce anche i test su Apifox per tua comodità. Sostituisci <YOUR_API_KEY> con la tua chiave CometAPI effettiva presente nel tuo account. L’URL base è Chat Completions e Responses.
Inserisci la tua domanda o richiesta nel campo content — è a questo che il modello risponderà. Elabora la risposta dell’API per ottenere la risposta generata.
Passaggio 3: Recupera e verifica i risultati
Elabora la risposta dell’API per ottenere l’output generato. Dopo l’elaborazione, l’API risponde con lo stato dell’attività e i dati di output.