GLM-4.6 è l’ultima release principale della famiglia GLM di Z.ai (precedentemente Zhipu AI): un modello MoE (Mixture-of-Experts) linguistico di grandi dimensioni di quarta generazione, ottimizzato per flussi di lavoro basati su agenti, ragionamento su contesti lunghi e programmazione nel mondo reale. La release enfatizza l’integrazione pratica tra agenti/strumenti, una finestra di contesto molto ampia e la disponibilità di pesi aperti per la distribuzione locale.
Caratteristiche principali
- Contesto lungo — finestra di contesto nativa di 200K token (espansa da 128K). (docs.z.ai)
- Coding e capacità basate su agenti — miglioramenti dichiarati nelle attività di programmazione nel mondo reale e migliore invocazione di strumenti per gli agenti.
- Efficienza — ~30% di consumo di token in meno rispetto a GLM-4.5 nei test di Z.ai.
- Distribuzione e quantizzazione — prima integrazione annunciata FP8 e Int4 per i chip Cambricon; supporto FP8 nativo su Moore Threads tramite vLLM.
- Dimensione del modello e tipo di tensore — gli artefatti pubblicati indicano un modello da ~357B parametri (tensori BF16 / F32) su Hugging Face.
Dettagli tecnici
Modalità e formati. GLM-4.6 è un LLM solo testo (modalità di input e output: testo). Lunghezza del contesto = 200K token; output massimo = 128K token.
Quantizzazione e supporto hardware. Il team riporta FP8/Int4 quantization sui chip Cambricon e FP8 nativo su GPU Moore Threads usando vLLM per l’inferenza — importante per ridurre i costi di inferenza e consentire distribuzioni on-prem e su cloud domestico.
Strumenti e integrazioni. GLM-4.6 è distribuito tramite l’API di Z.ai, reti di provider di terze parti (ad es., CometAPI) ed è integrato in agenti di coding (Claude Code, Cline, Roo Code, Kilo Code).
Dettagli tecnici
Modalità e formati. GLM-4.6 è un LLM solo testo (modalità di input e output: testo). Lunghezza del contesto = 200K token; output massimo = 128K token.
Quantizzazione e supporto hardware. Il team riporta FP8/Int4 quantization sui chip Cambricon e FP8 nativo su GPU Moore Threads usando vLLM per l’inferenza — importante per ridurre i costi di inferenza e consentire distribuzioni on-prem e su cloud domestico.
Strumenti e integrazioni. GLM-4.6 è distribuito tramite l’API di Z.ai, reti di provider di terze parti (ad es., CometAPI) ed è integrato in agenti di coding (Claude Code, Cline, Roo Code, Kilo Code).
Prestazioni nei benchmark
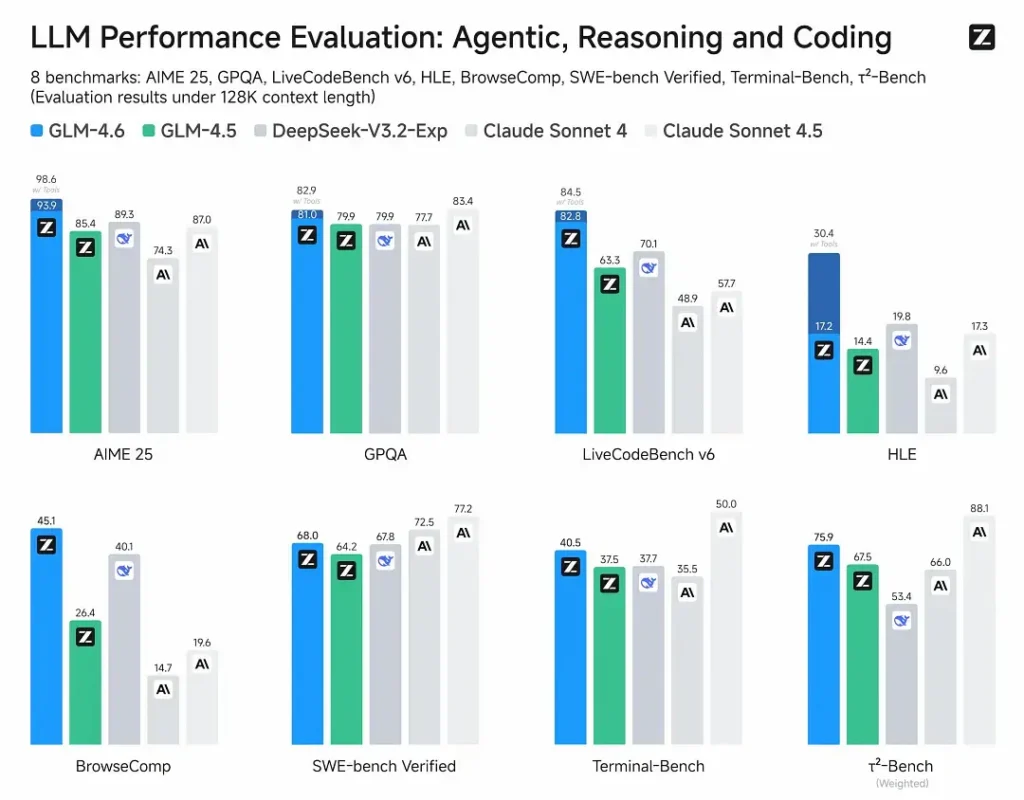
- Valutazioni pubblicate: GLM-4.6 è stato testato su otto benchmark pubblici che coprono agenti, ragionamento e coding e mostra chiari miglioramenti rispetto a GLM-4.5. Nei test di programmazione nel mondo reale valutati da umani (CC-Bench esteso), GLM-4.6 utilizza ~15% meno token rispetto a GLM-4.5 e registra un tasso di vittoria di ~48.6% vs Claude Sonnet 4 di Anthropic (quasi parità in molte classifiche).
- Posizionamento: i risultati affermano che GLM-4.6 è competitivo con i principali modelli nazionali e internazionali (gli esempi citati includono DeepSeek-V3.1 e Claude Sonnet 4).
Limitazioni e rischi
- Allucinazioni ed errori: come tutti gli LLM attuali, GLM-4.6 può e fa errori fattuali — la documentazione di Z.ai avverte esplicitamente che gli output possono contenere errori. Gli utenti dovrebbero applicare verifica e recupero/RAG per contenuti critici.
- Complessità del modello e costo di serving: 200K di contesto e output molto grandi aumentano drasticamente le esigenze di memoria e latenza e possono alzare i costi di inferenza; sono necessari quantizzazione/ingegneria dell’inferenza per operare su scala.
- Lacune di dominio: sebbene GLM-4.6 riporti prestazioni forti su agenti/coding, alcuni report pubblici notano che è ancora indietro rispetto a certe versioni di modelli concorrenti in microbenchmark specifici (ad es., alcune metriche di coding vs Sonnet 4.5). Valutare per singolo compito prima di sostituire modelli in produzione.
- Sicurezza e policy: i pesi aperti aumentano l’accessibilità ma sollevano anche questioni di responsabilità di gestione (mitigazioni, barriere di sicurezza e red-teaming restano responsabilità dell’utente).
Casi d’uso
- Sistemi basati su agenti e orchestrazione di strumenti: tracce lunghe degli agenti, pianificazione multi-strumento, invocazione dinamica degli strumenti; la messa a punto per agenti è un punto chiave di vendita.
- Assistenti di programmazione nel mondo reale: generazione di codice multi-turn, revisione del codice e assistenti IDE interattivi (integrati in Claude Code, Cline, Roo Code—secondo Z.ai). I miglioramenti nell’efficienza dei token lo rendono attraente per piani sviluppatore ad uso intensivo.
- Flussi di lavoro su documenti lunghi: sintesi, sintesi multi-documento, revisioni legali/tecniche estese grazie alla finestra da 200K.
- Creazione di contenuti e personaggi virtuali: dialoghi estesi, mantenimento coerente del personaggio in scenari multi-turn.
Come GLM-4.6 si confronta con altri modelli
- GLM-4.5 → GLM-4.6: cambiamento significativo nella dimensione del contesto (128K → 200K) e nell’efficienza dei token (~15% meno token su CC-Bench); uso migliorato di agenti/strumenti.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai riporta quasi parità su diverse classifiche e un tasso di vittoria di ~48.6% sui compiti di coding del mondo reale di CC-Bench (competizione serrata, con alcuni microbenchmark dove Sonnet è ancora in testa). Per molte squadre di ingegneria, GLM-4.6 è posizionato come un’alternativa efficiente in termini di costi.
- GLM-4.6 vs altri modelli a lungo contesto (DeepSeek, varianti Gemini, famiglia GPT-4): GLM-4.6 enfatizza il grande contesto e i flussi di lavoro di coding basati su agenti; i punti di forza relativi dipendono dalla metrica (efficienza dei token/integrazione con agenti vs accuratezza della sintesi di codice puro o pipeline di sicurezza). La selezione empirica dovrebbe essere guidata dal compito.
L’ultimo modello di punta di Zhipu AI, GLM-4.6, è stato rilasciato: 355B parametri totali, 32B attivi. Supera GLM-4.5 in tutte le capacità principali.
- Programmazione: in linea con Claude Sonnet 4, il migliore in Cina.
- Contesto: espanso a 200K (da 128K).
- Ragionamento: migliorato, supporta le chiamate agli strumenti durante l’inferenza.
- Ricerca: chiamata agli strumenti migliorata e prestazioni degli agenti potenziate.
- Scrittura: migliore allineamento alle preferenze umane in stile, leggibilità e role-playing.
- Multilingue: traduzione tra lingue potenziata.