
Qwen3-Max-Preview è l'ultimo modello di anteprima di punta di Alibaba nella famiglia Qwen3: un modello in stile Mixture-of-Experts (MoE) da oltre un trilione di parametri con una finestra di contesto token ultra-lunga da 262k, rilasciato in anteprima per l'uso aziendale/cloud. Si rivolge a *ragionamento approfondito, comprensione di documenti lunghi, codifica e flussi di lavoro agentici.
Informazioni di base e caratteristiche principali
- Nome / Etichetta:
qwen3-max-preview(Istruire). - Scala: Oltre 1 trilione di parametri (ammiraglia da mille miliardi di parametri). Questo è il traguardo chiave di marketing/statistico per il lancio.
- Finestra contestuale: Token 262,144 (supporta input molto lunghi e trascrizioni multi-file).
- Modalità: Variante "Instruct" ottimizzata per le istruzioni con supporto per pensiero (catena di pensieri deliberata) e non-pensiero modalità veloci nella famiglia Qwen3.
- Disponibilità: Accesso in anteprima tramite Chat di Qwen, Studio modello cloud Alibaba (endpoint compatibili con OpenAI o DashScope) e provider di routing come CometaAPI.
Dettagli tecnici (architettura e modalità)
- architettura: Qwen3-Max segue la linea di design Qwen3 che utilizza un mix di denso + Mix di Esperti (MoE) componenti in varianti più grandi, oltre a scelte ingegneristiche per ottimizzare l'efficienza dell'inferenza per conteggi di parametri molto elevati.
- Modalità di pensiero vs modalità di non pensiero: La serie Qwen3 ha introdotto un modalità di pensiero (per output in stile catena di pensiero multi-step) e modalità non-pensiero per risposte più rapide e concise; la piattaforma espone parametri per attivare o disattivare questi comportamenti.
- Funzionalità di memorizzazione nella cache del contesto/prestazioni: Elenchi di Model Studio cache di contesto supporto per richieste di grandi dimensioni per ridurre i costi di input ripetuti e migliorare la produttività in contesti ripetuti.
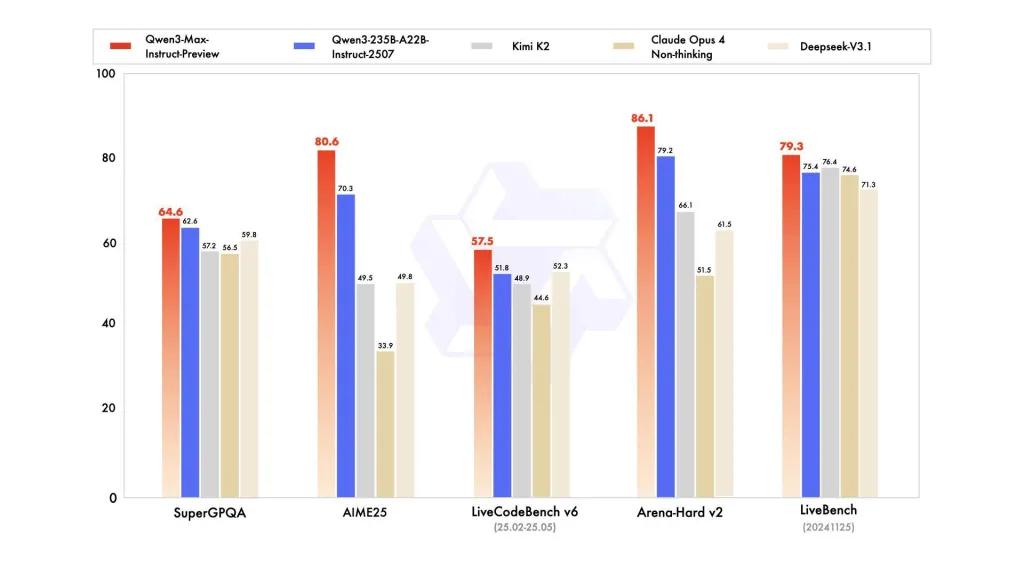
Prestazioni di riferimento
i report fanno riferimento a SuperGPQA, varianti di LiveCodeBench, AIME25 e altre suite di contest/benchmark in cui Qwen3-Max appare competitivo o leader.
Limitazioni e rischi (note pratiche e di sicurezza)
- Opacità per la ricetta di allenamento completa/pesi: In anteprima, il rilascio completo di training/dati/pesi e i materiali di riproducibilità potrebbero essere limitati rispetto alle precedenti versioni open-weight di Qwen3. Alcuni modelli della famiglia Qwen3 sono stati rilasciati open-weight, ma Qwen3-Max viene fornito come anteprima controllata per l'accesso al cloud. riduce la riproducibilità per ricercatori indipendenti.
- Allucinazioni e realtà: I report dei fornitori affermano una riduzione delle allucinazioni, ma l'uso pratico continuerà a riscontrare errori fattuali e affermazioni eccessivamente convincenti: si applicano le avvertenze standard del LLM. È necessaria una valutazione indipendente prima di implementazioni ad alto rischio.
- Costo su larga scala: Con un'ampia finestra di contesto e un'elevata capacità, costi simbolici può essere sostanziale per prompt molto lunghi o per la produttività in produzione. Utilizzare controlli di caching, chunking e budget.
- Considerazioni normative e di sovranità dei dati: Gli utenti aziendali dovrebbero verificare le regioni di Alibaba Cloud, la residenza dei dati e le implicazioni di conformità prima di elaborare informazioni sensibili. (La documentazione di Model Studio include endpoint e note specifici per regione.)
Utilizzo Tipico
- Comprensione/riepilogo dei documenti su larga scala: memorie legali, specifiche tecniche e basi di conoscenza multi-file (vantaggio: Token da 262K finestra).
- Ragionamento del codice a contesto lungo e assistenza al codice su scala di repository: comprensione del codice multi-file, ampie revisioni PR, suggerimenti di refactoring a livello di repository.
- Ragionamento complesso e attività di pensiero concatenato: gare di matematica, pianificazione multi-step, flussi di lavoro agentici in cui le tracce "pensanti" aiutano la tracciabilità.
- Domande e risposte aziendali multilingue ed estrazione di dati strutturati: supporto di grandi corpora multilingue e capacità di output strutturato (JSON/tabelle).
Come chiamare l'API Qqwen3-max-preview da CometAPI
qwen3-max-preview Prezzi API in CometAPI: sconto del 20% sul prezzo ufficiale:
| Token di input | $0.24 |
| Gettoni di uscita | $2.42 |
Passi richiesti
- Accedere cometapi.comSe non sei ancora un nostro utente, registrati prima
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.
- Ottieni l'URL di questo sito: https://api.cometapi.com/
Usa il metodo
- Selezionare l'endpoint "qwen3-max-preview" per inviare la richiesta API e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per maggiore praticità.
- Sostituire con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo contenuto: il modello risponderà a questa domanda.
- Elaborare la risposta API per ottenere la risposta generata.
Chiamata API
CometAPI fornisce un'API REST completamente compatibile, per una migrazione senza interruzioni. Dettagli chiave per Documento API:
- Parametri fondamentali:
prompt,max_tokens_to_sample,temperature,stop_sequences - endpoint:
https://api.cometapi.com/v1/chat/completions - Parametro del modello: anteprima qwen3-max
- Autenticazione:
Bearer YOUR_CometAPI_API_KEY - Tipo di contenuto:
application/json.
sostituire
CometAPI_API_KEYcon la tua chiave; nota il URL di base.
Python (richieste) — Compatibile con OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Suggerimento: uso max_input_tokens, max_output_tokense Model Studio cache di contesto funzionalità durante l'invio di contesti molto ampi per controllare costi e produttività.
Vedere anche Qwen3-codificatore