

Dal 19 al 20 novembre 2025 OpenAI ha rilasciato due aggiornamenti correlati ma distinti: GPT-5.1-Codex-Max, un nuovo modello di codifica agentica per Codex che enfatizza la codifica a lungo orizzonte, l'efficienza dei token e la "compattazione" per sostenere sessioni multi-finestra; e GPT-5.1 Pro, un modello ChatGPT Pro-tier aggiornato, ottimizzato per risposte più chiare e competenti in lavori complessi e professionali.
Che cos'è GPT-5.1-Codex-Max e quale problema cerca di risolvere?
GPT-5.1-Codex-Max è un modello Codex specializzato di OpenAI ottimizzato per flussi di lavoro di codifica che richiedono ragionamento ed esecuzione sostenuti e a lungo termineLaddove i modelli ordinari possono essere ostacolati da contesti estremamente lunghi, ad esempio refactoring multi-file, cicli di agenti complessi o attività CI/CD persistenti, Codex-Max è progettato per compattare e gestire automaticamente lo stato della sessione su più finestre di contesto, consentendogli di continuare a funzionare in modo coerente anche se un singolo progetto si estende su migliaia (o più) di token. OpenAI posiziona Codex-Max come il passo successivo per rendere gli agenti con capacità di codice realmente utili per lavori di ingegneria estesi.
Che cos'è GPT-5.1-Codex-Max e quale problema cerca di risolvere?
GPT-5.1-Codex-Max è un modello Codex specializzato di OpenAI ottimizzato per flussi di lavoro di codifica che richiedono ragionamento ed esecuzione sostenuti e a lungo termineLaddove i modelli ordinari possono essere ostacolati da contesti estremamente lunghi, ad esempio refactoring multi-file, cicli di agenti complessi o attività CI/CD persistenti, Codex-Max è progettato per compattare e gestire automaticamente lo stato della sessione su più finestre di contesto, consentendogli di continuare a funzionare in modo coerente anche se un singolo progetto comprende migliaia (o più) di token.
È descritto da OpenAI come "più veloce, più intelligente e più efficiente in termini di token in ogni fase del ciclo di sviluppo" ed è esplicitamente destinato a sostituire GPT-5.1-Codex come modello predefinito nelle superfici Codex.
Istantanea delle funzionalità
- Compattazione per la continuità multi-finestra: elimina e preserva il contesto critico per funzionare in modo coerente su milioni di token e ore. 0
- Efficienza del token migliorata rispetto a GPT-5.1-Codex: fino a circa il 30% in meno di token di pensiero per uno sforzo di ragionamento simile su alcuni benchmark del codice.
- Durabilità agente a lungo termine: osservato internamente per sostenere cicli di agenti di più ore/più giorni (OpenAI ha documentato esecuzioni interne di >24 ore).
- Integrazioni della piattaforma: disponibile oggi all'interno di Codex CLI, estensioni IDE, cloud e strumenti di revisione del codice; accesso API in arrivo.
- Supporto per l'ambiente Windows: OpenAI sottolinea specificamente che Windows è supportato per la prima volta nei flussi di lavoro Codex, ampliando la portata degli sviluppatori nel mondo reale.
Come si confronta con i prodotti concorrenti (ad esempio GitHub Copilot, altre IA di codifica)?
GPT-5.1-Codex-Max è presentato come un collaboratore più autonomo e a lungo termine rispetto agli strumenti di completamento per richiesta. Mentre Copilot e assistenti simili eccellono nei completamenti a breve termine all'interno dell'editor, i punti di forza di Codex-Max risiedono nell'orchestrazione di attività multi-fase, nel mantenimento di uno stato coerente tra le sessioni e nella gestione di flussi di lavoro che richiedono pianificazione, test e iterazione. Detto questo, l'approccio migliore per la maggior parte dei team sarà ibrido: utilizzare Codex-Max per l'automazione complessa e le attività di agenti prolungate e utilizzare assistenti più leggeri per i completamenti a livello di riga.
Come funziona GPT-5.1-Codex-Max?
Che cosa è la “compattazione” e come consente un lavoro di lunga durata?
Un progresso tecnico centrale è compattazione—un meccanismo interno che elimina la cronologia della sessione preservando i pezzi salienti del contesto in modo che il modello possa continuare a lavorare in modo coerente multiplo Finestre di contesto. In pratica, ciò significa che le sessioni Codex che si avvicinano al limite di contesto verranno compattate (i token più vecchi o di valore inferiore verranno riepilogati/conservati), in modo che l'agente abbia una finestra nuova e possa continuare a iterare ripetutamente fino al completamento dell'attività. OpenAI segnala esecuzioni interne in cui il modello ha lavorato su attività ininterrottamente per più di 24 ore.
Ragionamento adattivo ed efficienza dei token
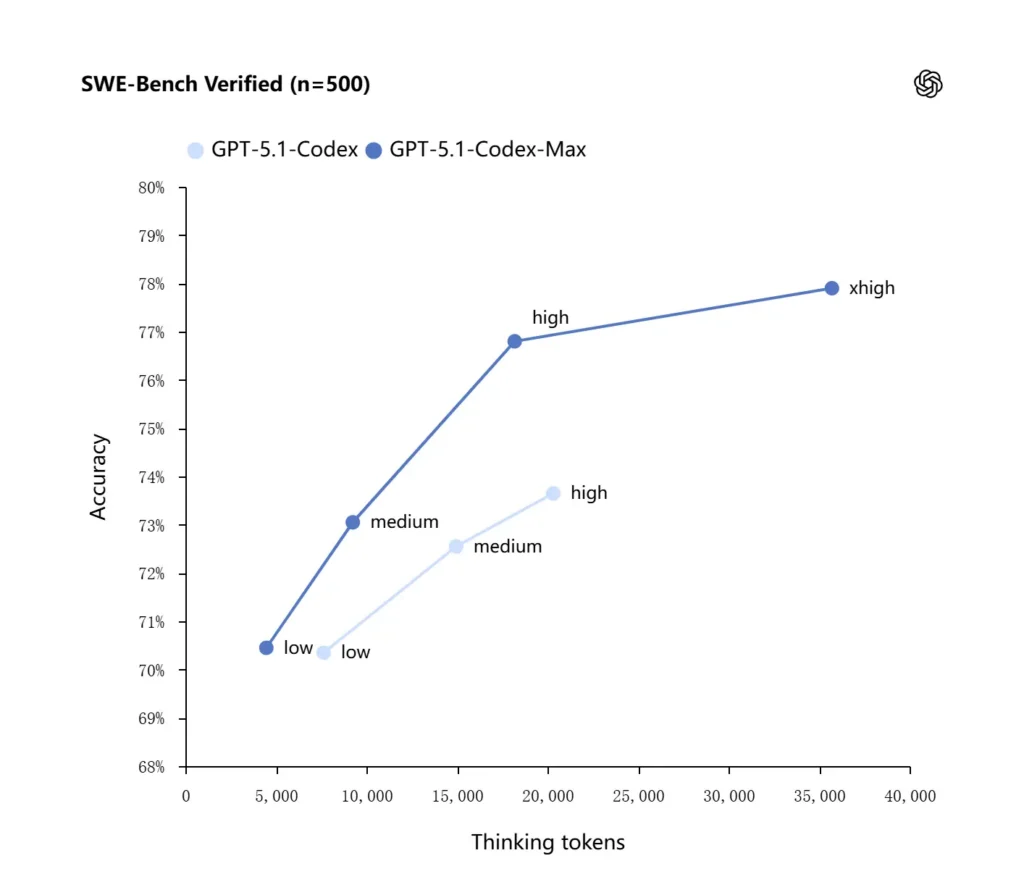
GPT-5.1-Codex-Max applica strategie di ragionamento migliorate che lo rendono più efficiente in termini di token: nei benchmark interni riportati da OpenAI, il modello Max raggiunge prestazioni simili o migliori rispetto a GPT-5.1-Codex utilizzando un numero significativamente inferiore di token "pensanti" (OpenAI cita circa 30% in meno Token di pensiero su SWE-bench verificati quando eseguiti a pari sforzo di ragionamento. Il modello introduce anche una modalità di sforzo di ragionamento "Extra High (xhigh)" per attività non sensibili alla latenza, che consente di impiegare più ragionamento interno per ottenere output di qualità superiore.
Integrazioni di sistema e strumenti agenti
Codex-Max viene distribuito all'interno dei flussi di lavoro Codex (CLI, estensioni IDE, cloud e superfici di revisione del codice) in modo da poter interagire con le attuali toolchain degli sviluppatori. Le prime integrazioni includono gli agenti Codex CLI e IDE (VS Code, JetBrains, ecc.), con accesso alle API previsto in seguito. L'obiettivo di progettazione non è solo una sintesi del codice più intelligente, ma anche un'intelligenza artificiale in grado di eseguire flussi di lavoro multi-step: aprire file, eseguire test, correggere errori, effettuare il refactoring e rieseguire.
Come si comporta GPT-5.1-Codex-Max nei benchmark e nel lavoro reale?
Ragionamento sostenuto e compiti a lungo termine
Le valutazioni evidenziano miglioramenti misurabili nel ragionamento sostenuto e nei compiti a lungo termine:
- Valutazioni interne di OpenAI: Codex-Max può lavorare su attività per "più di 24 ore" in esperimenti interni e l'integrazione di Codex con gli strumenti di sviluppo ha aumentato le metriche di produttività ingegneristica interna (ad esempio, utilizzo e throughput delle richieste di pull). Queste sono affermazioni interne di OpenAI e indicano miglioramenti a livello di attività nella produttività nel mondo reale.
- Valutazioni indipendenti (METR): Il rapporto indipendente del METR ha misurato il osservato il 50% dell'orizzonte temporale (una statistica che rappresenta il tempo mediano in cui il modello può sostenere in modo coerente un compito lungo) per GPT-5.1-Codex-Max a circa Ore 2 40 minuti (con un ampio intervallo di confidenza), in aumento rispetto alle 2 ore e 17 minuti di GPT-5 in misurazioni comparabili, un miglioramento significativo e in linea con il trend nella coerenza sostenuta. La metodologia e l'intervallo di confidenza di METR enfatizzano la variabilità, ma il risultato supporta l'ipotesi che Codex-Max migliori le prestazioni pratiche a lungo termine.
Benchmark del codice
OpenAI segnala risultati migliori nelle valutazioni di frontier coding, in particolare nel test SWE-bench Verified, dove GPT-5.1-Codex-Max supera GPT-5.1-Codex con una migliore efficienza dei token. L'azienda sottolinea che, a parità di sforzo di ragionamento "medio", il modello Max produce risultati migliori utilizzando circa il 30% in meno di token di ragionamento; per gli utenti che consentono un ragionamento interno più lungo, la modalità xhigh può migliorare ulteriormente le risposte a scapito della latenza.
| GPT‑5.1-Codex (alto) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench verificato (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
In che modo GPT-5.1-Codex-Max si confronta con GPT-5.1-Codex?
Differenze di prestazioni e di scopo
- Scopo: GPT-5.1-Codex era una variante di codifica ad alte prestazioni della famiglia GPT-5.1; Codice Max è esplicitamente un successore agentico a lungo termine, pensato per essere l'impostazione predefinita consigliata per Codex e ambienti simili a Codex.
- Efficienza del token: Codex-Max mostra miglioramenti significativi nell'efficienza dei token (OpenAI afferma di avere circa il 30% in meno di token pensanti) su SWE-bench e nell'uso interno.
- Gestione del contesto: Codex-Max introduce la compattazione e la gestione nativa multi-finestra per supportare attività che superano una singola finestra di contesto; Codex non forniva nativamente questa capacità sulla stessa scala.
- Preparazione degli utensili: Codex-Max viene fornito come modello Codex predefinito nelle superfici CLI, IDE e di revisione del codice, segnalando una migrazione per i flussi di lavoro degli sviluppatori di produzione.
Quando utilizzare quale modello?
- Utilizzare GPT-5.1-Codex per assistenza interattiva alla codifica, modifiche rapide, piccoli refactoring e casi d'uso a bassa latenza in cui l'intero contesto rilevante si adatta facilmente a un'unica finestra.
- Utilizzare GPT-5.1-Codex-Max per refactoring multi-file, attività agentiche automatizzate che richiedono molti cicli di iterazione, flussi di lavoro di tipo CI/CD o quando è necessario che il modello mantenga una prospettiva a livello di progetto attraverso numerose interazioni.
Modelli pratici di prompt ed esempi per ottenere i migliori risultati?
Modelli di sollecitazione che funzionano bene
- Siate espliciti riguardo agli obiettivi e ai vincoli: “Rifattorizza X, preserva l'API pubblica, mantieni i nomi delle funzioni e assicurati che i test A, B, C vengano superati.”
- Fornire un contesto minimo riproducibile: Collegarsi al test non riuscito, includere stack trace e frammenti di file rilevanti anziché scaricare interi repository. Codex-Max compatterà la cronologia secondo necessità.
- Utilizzare istruzioni dettagliate per attività complesse: suddividere i lavori di grandi dimensioni in una sequenza di sottoattività e lasciare che Codex-Max le esegua (ad esempio, "1) eseguire i test 2) correggere i 3 test più falliti 3) eseguire il linter 4) riassumere le modifiche").
- Richiedi spiegazioni e differenze: richiedere sia la patch sia una breve motivazione in modo che i revisori umani possano valutare rapidamente la sicurezza e l'intento.
Modelli di prompt di esempio
Attività di refactoring
“Rifattorizza il
payment/modulo per estrarre l'elaborazione dei pagamenti inpayment/processor.pyMantenere stabili le firme delle funzioni pubbliche per i chiamanti esistenti. Creare test unitari perprocess_payment()che coprono il successo, l'errore di rete e la scheda non valida. Esegui la suite di test e restituisci i test falliti e una patch in formato diff unificato."
Correzione bug + test
“Un test
tests/test_user_auth.py::test_token_refreshfallisce con traceback . Indagare la causa principale, proporre una correzione con modifiche minime e aggiungere un test unitario per prevenire la regressione. Applicare la patch ed eseguire i test."
Generazione iterativa di PR
“Implementa la funzionalità X: aggiungi endpoint
POST /api/exportche esporta i risultati ed è autenticato. Crea l'endpoint, aggiungi i documenti, crea i test e apri una richiesta di conferma con riepilogo e checklist degli elementi manuali."
Per la maggior parte di questi, inizia con medie sforzo; passare a xalto quando è necessario che il modello esegua ragionamenti approfonditi su più file e più iterazioni di test.
Come si accede a GPT-5.1-Codex-Max
Dove è disponibile oggi
OpenAI ha integrato GPT-5.1-Codex-Max in Utensili del Codex Oggi: la CLI del Codex, le estensioni IDE, il cloud e i flussi di revisione del codice utilizzano Codex-Max per impostazione predefinita (è possibile optare per Codex-Mini). La disponibilità dell'API deve essere preparata; GitHub Copilot ha anteprime pubbliche che includono i modelli GPT-5.1 e della serie Codex.
Gli sviluppatori possono accedere a GPT-5.1-Codex-Max e API GPT-5.1-Codex tramite CometAPI. Per iniziare, esplora le capacità del modello diCometaAPI nella Parco giochi e consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. ConeAPI t offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!
Avvio rapido (pratico passo dopo passo)
- Assicurati di avere accesso: verifica che il tuo piano prodotto ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) o il tuo piano API per sviluppatori supporti i modelli della famiglia GPT-5.1/Codex.
- Installa l'estensione Codex CLI o IDE: Se si desidera eseguire attività di codice in locale, installare la Codex CLI o l'estensione Codex IDE per VS Code / JetBrains / Xcode, a seconda dei casi. Nelle configurazioni supportate, l'impostazione predefinita sarà GPT-5.1-Codex-Max.
- Scegli lo sforzo di ragionamento: iniziare con medie sforzo per la maggior parte delle attività. Per il debug approfondito, i refactoring complessi o quando si desidera che il modello rifletta più a fondo e non si ha a cuore la latenza della risposta, passare a alto or xalto modalità. Per piccole correzioni rapide, Basso è ragionevole.
- Fornire il contesto del repository: Fornisci al modello un punto di partenza chiaro: un URL del repository o un set di file e una breve istruzione (ad esempio, "rielabora il modulo di pagamento per utilizzare I/O asincrono e aggiungere test unitari, mantenere i contratti a livello di funzione"). Codex-Max compatterà la cronologia man mano che si avvicina ai limiti del contesto e continuerà il lavoro.
- Iterare con i test: Dopo che il modello ha prodotto le patch, esegui suite di test e fornisci feedback sugli errori come parte della sessione in corso. La compattazione e la continuità multi-finestra consentono a Codex-Max di conservare il contesto dei test falliti e di iterare.
Conclusione:
GPT-5.1-Codex-Max rappresenta un passo sostanziale verso assistenti di codifica agentici in grado di supportare attività ingegneristiche complesse e di lunga durata con maggiore efficienza e capacità di ragionamento. I progressi tecnici (compattazione, modalità di sforzo di ragionamento, addestramento in ambiente Windows) lo rendono eccezionalmente adatto alle moderne organizzazioni ingegneristiche, a condizione che i team abbinino il modello a controlli operativi conservativi, chiare policy di coinvolgimento umano e un monitoraggio affidabile. Per i team che lo adottano con attenzione, Codex-Max ha il potenziale per cambiare il modo in cui il software viene progettato, testato e mantenuto, trasformando il lavoro ingegneristico ripetitivo in una collaborazione di maggior valore tra esseri umani e modelli.