

Gemini Embedding 2 è il primo modello di embedding di Google nativamente multimodale che mappa testo, immagini, audio, video e PDF in un unico spazio vettoriale semantico a 3.072 dimensioni (con dimensioni di output configurabili). Introduce Matryoshka Representation Learning per fornire embedding annidati/troncati, prestazioni multilingue migliorate (100+ lingue) e controlli ottimizzati per embedding specifici al task (ad es., task:search, task:code).
Che cos’è Gemini Embedding 2?
Gemini Embedding 2 è un modello di embedding unificato di Google che mappa più modalità di input — testo, immagini, audio, video e documenti — in un unico spazio vettoriale semantico. Ogni embedding è (per impostazione predefinita) un vettore in virgola mobile a 3.072 dimensioni che rappresenta il significato semantico dell’input, in modo che elementi semanticamente simili (indipendentemente dalla modalità) risultino vicini nello spazio vettoriale. Le capacità principali sono:
- Ampia copertura di lingue e formati: un unico modello che accetta testo, immagini, audio, video e documenti e li colloca in un unico spazio vettoriale semantico. È documentato che Gemini Embedding 2 cattura l’intento semantico in 100+ lingue e accetta formati di file comuni (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), con limiti concreti per richiesta (ad es., fino a poche immagini o decine di secondi di audio/video per richiesta — vedi “Come si usa” più sotto).
- Vera multimodalità: un unico modello che accetta testo, immagini, audio, video e documenti e li colloca in un unico spazio vettoriale semantico, così da poter confrontare o recuperare tra modalità diverse (ad es., testo → immagine, audio → testo).
- Grande dimensionalità predefinita con troncamento flessibile: il modello produce per impostazione predefinita vettori a 3072 dimensioni, ma utilizza la Matryoshka Representation Learning (MRL) per concentrare i contenuti semantici più importanti nelle prime dimensioni, così da poter troncare a 1536, 768 (o meno) con solo modeste perdite di qualità nel retrieval. Questo riduce i compromessi tra costo di archiviazione e calcolo.
Perché è importante. Storicamente, gli embedding erano per lo più solo testo o richiedevano encoder separati per ogni modalità con complessi strati di allineamento cross-modale. Gemini Embedding 2 rimuove questa barriera supportando nativamente più formati — così una query testuale può recuperare un’immagine o una breve clip per similarità semantica senza trascrizione intermedia o mappature manuali. Ciò semplifica le pipeline di RAG (retrieval-augmented generation), di ricerca semantica e di retrieval multimodale.
Funzionalità e capacità principali (novità)
1. Vera multimodalità nativa (un unico spazio di embedding)
Un unico modello che accetta testo, immagini, audio, video e documenti e li colloca in un unico spazio vettoriale semantico. Gemini Embedding 2 mappa testo, immagini, audio, video e documenti nello stesso spazio di embedding, così il retrieval cross-modale (testo→immagine, audio→testo) funziona direttamente senza allineamento tra modelli. Questo riduce la complessità della pipeline e semplifica gli stack RAG (Retrieval-Augmented Generation).
2. Vettori predefiniti a 3.072 dimensioni con output regolabile
Gemini Embedding 2 produce per impostazione predefinita vettori a 3072 dimensioni, ma utilizza la Matryoshka Representation Learning (MRL) per concentrare i contenuti semantici più importanti nelle prime dimensioni, così da poter troncare a 1536, 768 (o meno) con solo modeste perdite di qualità nel retrieval. Questo riduce i compromessi tra costo di archiviazione e calcolo.
3. Matryoshka Representation Learning (MRL)
MRL produce embedding “annidati” — come le bambole russe — in modo che le porzioni a dimensionalità inferiore preservino le semantiche di livello superiore. Questo consente ai sistemi di scegliere un punto di funzionamento (compromesso archiviazione/accuratezza) senza mantenere diversi modelli di embedding separati. Analisi iniziali su blog e documentazione descrivono questa tecnica come un’innovazione centrale per la flessibilità.
4. Suggerimenti di task / obiettivi di embedding personalizzati
L’API accetta suggerimenti task (ad es., task:search, task:code retrieval, task:semantic-similarity) così il modello può ottimizzare la geometria dell’embedding per relazioni specifiche a valle — simile al condizionamento sul task usato in precedenti sistemi di embedding ma esteso agli input multimodali.
5. Ampiezza di lingue e modalità
È documentato che Gemini Embedding 2 cattura l’intento semantico in 100+ lingue e accetta formati di file comuni (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), con limiti concreti per richiesta (ad es., fino a poche immagini o decine di secondi di audio/video per richiesta — vedi “Come si usa” più sotto).
Benchmark delle prestazioni
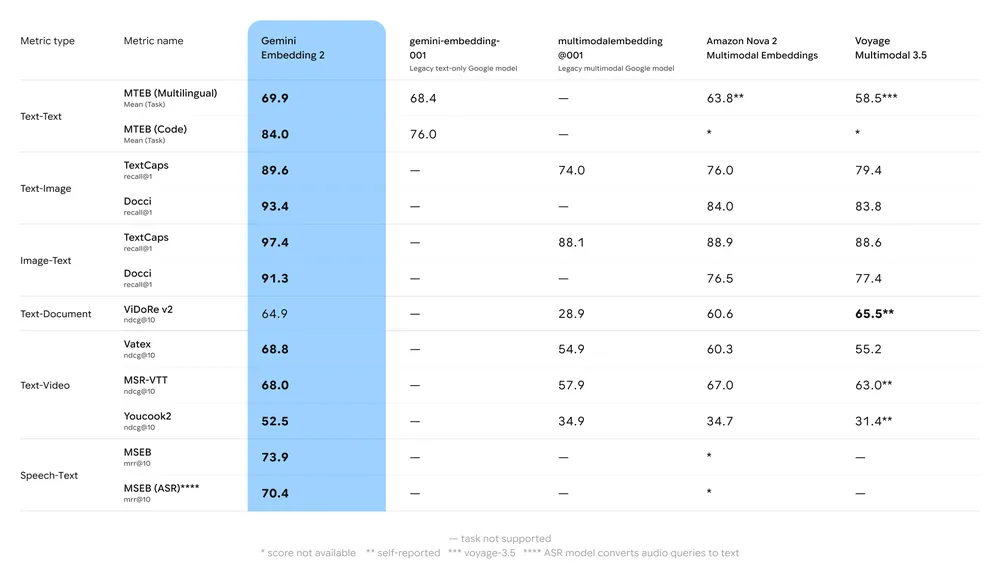
Sintesi dei benchmark principali:
- MTEB (Massive Text Embedding Benchmark): Forte posizionamento riportato nelle classifiche MTEB per compiti in inglese e multilingue; le analisi mostrano un miglioramento significativo rispetto ai precedenti modelli di embedding di Gemini e a molte alternative proprietarie.
- Retrieval multimodale: Supera o eguaglia i migliori embedding mono-modali quando usato per similarità cross-modale (ad es., retrieval testo→immagine), grazie all’addestramento multimodale nativo.
- Latenza e throughput: Generazione di embedding ospitata nel cloud, ma i casi d’uso sensibili alla latenza possono preferire vettori troncati o modelli di embedding leggeri alternativi per esigenze on-edge.
Gemini Embedding 2 vs gemini-embedding-001 e text-embedding-3-large
| Attributo | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Rilascio / disponibilità | 10 mar 2026 — anteprima pubblica (Gemini API / Vertex AI). | Precedente embedding di Gemini (varianti solo testo) — GA già da prima. | Annunciato a gen 2024 (solo testo, GA). |
| Modalità supportate | Testo, immagini, audio, video, documenti (PDF) — spazio vettoriale unificato. | Testo (principalmente). | Solo testo (multilingue di alta qualità). |
| Dimensionalità embedding predefinita | 3072 (MRL / troncamento consigliato: 1536, 768). | 3072 (per il modello large) — solo testo. | 3072 (text-embedding-3-large). |
| MTEB riportato (esempio) | Fascia alta dei 60 su MTEB; mostra 68.17 a 1536 nella tabella del fornitore (vedi documentazione). | gemini-embedding-001 ha riportato ~68.32 di media in alcune classifiche. | ~64.6 (media MTEB riportata da OpenAI per text-embedding-3-large). |
| Supporto audio/video nativo | Sì (embedding diretto di audio/video). | No (solo testo). | No (solo testo). |
| Casi d’uso tipici | Retrieval multimodale, RAG, ricerca semantica tra tipi di file, retrieval vocale, ricerca video. | Retrieval testuale, RAG multilingue. | Retrieval testuale, ricerca semantica, RAG — forte performance multilingue sul testo. |
Specifiche tecniche e limiti
Dimensione embedding predefinita e regolabile
- Predefinita: 3.072 dimensioni.
- Regolabile: il parametro
output_dimensionalityconsente di richiedere output a dimensionalità inferiore per risparmiare storage/CPU. Casi d’uso con archivi vettoriali massivi spesso riducono a 512–1.024 per ragioni di costo accettando qualche trade-off di accuratezza.
Modalità supportate e limiti per richiesta
- Immagini: PNG, JPEG — fino a 6 immagini per richiesta (limiti riportati dal fornitore).
- Video: MP4, MOV — il fornitore riporta fino a ~128 secondi per video in una singola richiesta di embedding.
- Audio: MP3, WAV — il fornitore riporta fino a ~80 secondi per input audio.
- Documenti: PDF — fino a 6 pagine per richiesta (dato del fornitore).
- Limite di token per contenuti testuali: il modello supporta input testuali di grandi dimensioni; esistono limiti pratici di token per richiesta (verificare la documentazione API e le quote Vertex AI).
Disponibilità e accesso
- Anteprima pubblica: Gemini Embedding 2 è stato rilasciato in anteprima pubblica ed è disponibile tramite la Gemini API e Google Cloud Vertex AI per uso sperimentale immediato
Domande frequenti (FAQ)
D1: Quali modalità supporta Gemini Embedding 2?
R: Testo, immagini (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV) e documenti PDF — tutti mappati nello stesso spazio vettoriale semantico.
D2: Qual è la dimensione vettoriale predefinita per Gemini Embedding 2?
R: La predefinita è 3.072 dimensioni. Puoi richiedere una dimensionalità di output più piccola tramite l’API.
D3: Gemini Embedding 2 è disponibile ora?
R: Sì — è stato annunciato come anteprima pubblica ed è disponibile tramite la Gemini API e Vertex AI (verifica l’id modello gemini-embedding-2-preview e il changelog attuale).
D4: Come si confronta con gli embedding di altri provider?
R: Test indipendenti di fornitori riportano che Gemini Embedding 2 è tra i migliori modelli proprietari per testo multilingue e mostra prestazioni all’avanguardia per diversi compiti multimodali. Le classifiche esatte variano per compito e dataset; testa sui tuoi dati.
D5: Devo trascrivere l’audio per usare Gemini Embedding 2?
R: No — Gemini Embedding 2 può accettare audio direttamente e produrre embedding senza prima trascriverlo in testo, abilitando il retrieval semantico end-to-end sull’audio.
D6: Come posso ridurre i costi di archiviazione per vettori a 3.072 dimensioni?
R: Opzioni includono richiedere una output_dimensionality inferiore, usare float16/quantization/PQ e archiviare rappresentazioni compresse nel tuo DB vettoriale. Post del fornitore forniscono workflow e best practice.
Cosa viene dopo — dovrei adottarlo ora?
Gemini Embedding 2 è un passo importante verso l’unificazione del retrieval multimodale e semplifica le architetture che in precedenza richiedevano retriever separati per testo, visione e parlato. I punti chiave per decidere l’adozione:
- Adotta prima se il tuo prodotto necessita di retrieval cross-modale robusto (testo↔immagine/video/audio) o se mantenere più retriever mono-modali è costoso e complesso.
- Pilota ora se vuoi valutare il troncamento MRL e misurare costo vs qualità (mantieni un deployment ibrido: 1536 come primario, 3072 per il re-ranking).
- Attendi se il tuo carico è estremamente sensibile ai costi e serve solo retrieval testuale — i migliori modelli solo testo (ad es., OpenAI text-embedding-3-large) restano competitivi e talvolta più economici a seconda della pipeline e del contratto.
Gli sviluppatori possono accedere a Gemini Embedding 2 e all’API OpenAI text-embedding-3 tramite CometAPI già da ora. Per iniziare, esplora le capacità del modello nel Playground e consulta la API guide per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore a quello ufficiale per aiutarti nell’integrazione.
Pronto a iniziare?→ Sign up for cometapi today !
Se vuoi conoscere altri suggerimenti, guide e novità sull’AI seguici su VK, X e Discord!