

Nel mondo in rapida evoluzione dell'intelligenza artificiale, il rilascio di ogni nuovo modello linguistico di grandi dimensioni (LLM) rappresenta più di un semplice balzo in avanti nella versione numerica: segnala progressi nel ragionamento, nella capacità di programmazione e nella collaborazione uomo-macchina. A fine settembre 2025, Zhipu AI (Z.ai) svelato GLM-4.6, il membro più recente della sua famiglia General Language Model. Basandosi sulla solida architettura e sulle solide basi di ragionamento di GLM-4.5, questo aggiornamento perfeziona le capacità del modello in ragionamento agentivo, intelligenza di codifica e comprensione del contesto a lungo termine, pur rimanendo aperto e accessibile sia agli sviluppatori che alle aziende.
Che cos'è GLM-4.6?
GLM-4.6 è una versione importante della serie GLM (General Language Model), progettata per bilanciare il ragionamento ad alta capacità con flussi di lavoro pratici per gli sviluppatori. Ad alto livello, la versione si rivolge a tre casi d'uso strettamente correlati: (1) generazione di codice avanzata e ragionamento sul codice, (2) attività di contesto esteso che richiedono la comprensione del modello su input molto lunghi e (3) flussi di lavoro agentici in cui il modello deve pianificare, richiamare strumenti e orchestrare processi multi-step. Il modello è disponibile in varianti pensate per API cloud e hub di modelli di community, consentendo modelli di distribuzione sia ospitati che self-hosted.
In pratica, GLM-4.6 si posiziona come un'ammiraglia "developer-first": i suoi miglioramenti non riguardano solo i numeri dei benchmark grezzi, ma anche funzionalità che cambiano in modo sostanziale il modo in cui gli sviluppatori creano assistenti, copiloti del codice e agenti basati su documenti o conoscenze. Aspettatevi una versione che pone l'accento sull'ottimizzazione delle istruzioni per l'uso degli strumenti, miglioramenti granulari per la qualità del codice e il debug, e scelte infrastrutturali che consentono contesti molto lunghi senza degenerazione lineare delle prestazioni.
Cosa si propone di risolvere GLM-4.6?
- Riduci l'attrito derivante dal lavorare con lunghe basi di codice e documenti di grandi dimensioni supportando finestre di contesto effettive più lunghe.
- Migliorare l'affidabilità della generazione e del debug del codice, producendo output più idiomatici e testabili.
- Aumentare la robustezza dei comportamenti agentivi (pianificazione, utilizzo di strumenti ed esecuzione di attività in più fasi) attraverso istruzioni mirate e ottimizzazione dello stile di rinforzo.
Da GLM-4.5 a GLM-4.6, cosa è cambiato nella pratica?
- Scala del contesto: 128K vai a Token da 200 rappresenta la più grande modifica in termini di UX/architettura per gli utenti: documenti lunghi, intere basi di codice o trascrizioni di agenti estesi possono ora essere elaborati come un'unica finestra di contesto. Ciò riduce la necessità di chunking ad hoc o costosi cicli di recupero per molti flussi di lavoro.
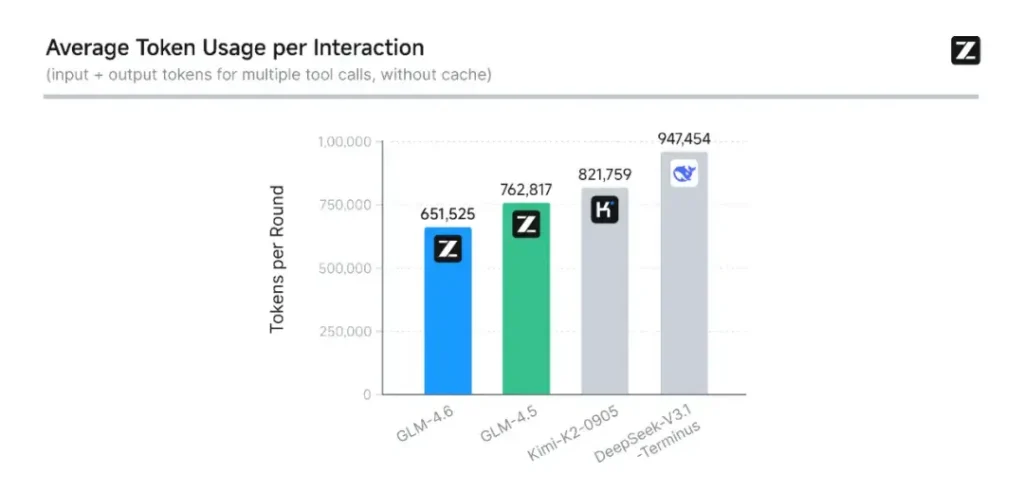
- Codifica e valutazione nel mondo reale: Z.ai ha esteso CC-Bench (il loro benchmark di codifica e completamento) con traiettorie di attività reali più difficili e segnala che GLM-4.6 termina le attività con ~15% di token in meno rispetto a GLM-4.5, migliorando al contempo i tassi di successo in complesse attività di ingegneria multi-turn. Ciò segnala una migliore efficienza dei token e miglioramenti delle capacità grezze negli scenari di codifica applicati. Z.ai
- Integrazione di agenti e strumenti: GLM-4.6 include modelli di supporto migliori per le chiamate di strumenti e gli agenti di ricerca, importanti per i prodotti che si basano sul modello per orchestrare la ricerca sul Web, l'esecuzione di codice o altri microservizi.
Quali sono le caratteristiche principali di GLM-4.6?
1. Finestra di contesto estesa a 200K token
Una delle caratteristiche più accattivanti di GLM-4.6 è la sua finestra di contesto estesa in modo massiccio. Espansione da 128K nella generazione precedente a Token da 200, GLM-4.6 può elaborare interi libri, complessi set di dati multi-documento o ore di dialogo in un'unica sessione. Questa espansione non solo migliora la comprensione, ma consente anche ragionamento coerente su input lunghi — un grande passo avanti per la sintesi dei documenti, l'analisi legale e i flussi di lavoro di ingegneria del software.
2. Intelligenza di codifica migliorata
L'intelligenza artificiale di Zhipu è interna CC-Bench benchmark, una serie di attività di programmazione del mondo reale, mostra che GLM-4.6 raggiunge notevoli miglioramenti nella precisione e nell'efficienza della codificaIl modello può produrre codice sintatticamente corretto e logicamente valido durante l'utilizzo circa il 15% in meno di token rispetto a GLM-4.5 per attività equivalenti. Questa efficienza simbolica si traduce in completamenti più rapidi ed economici senza sacrificare la qualità, un fattore vitale per l'implementazione aziendale.
3. Ragionamento avanzato e integrazione degli strumenti
Oltre alla generazione di testo grezzo, GLM-4.6 brilla in ragionamento potenziato dagli strumentiÈ stato addestrato e allineato per la pianificazione multi-step e per l'orchestrazione di sistemi esterni, dai database agli strumenti di ricerca agli ambienti di esecuzione. In pratica, ciò significa che GLM-4.6 può fungere da "cervello" di un agente AI autonomo, decidendo quando chiamare le API esterne, come interpretare i risultati e come mantenere la continuità delle attività tra le sessioni.
4. Allineamento migliorato del linguaggio naturale
Attraverso l'apprendimento di rinforzo continuo e l'ottimizzazione delle preferenze, GLM-4.6 fornisce flusso di conversazione più fluido, migliore corrispondenza di stile e maggiore allineamento di sicurezzaIl modello adatta il suo tono e la sua struttura al contesto, che si tratti di documentazione formale, tutoraggio didattico o scrittura creativa, migliorando la fiducia dell'utente e la leggibilità.
Quale architettura alimenta GLM-4.6?
GLM-4.6 è un modello misto di esperti?
Continuità del metodo di inferenza: Il team GLM indica che GLM-4.5 e GLM-4.6 condividono la stessa pipeline di inferenza fondamentale, consentendo l'aggiornamento delle configurazioni di distribuzione esistenti con il minimo attrito. Ciò riduce il rischio operativo per i team che già utilizzano GLM-4.x., ovvero parametri di scalabilità e scelte di progettazione del modello che enfatizzano la specializzazione per il ragionamento agentico, la codifica e l'inferenza efficiente. Il report GLM-4.5 fornisce la descrizione pubblica più chiara della strategia MoE e del regime di addestramento della famiglia (pre-addestramento multifase, iterazione del modello esperto, apprendimento per rinforzo per l'allineamento); GLM-4.6 applica tali insegnamenti ottimizzando la lunghezza del contesto e le capacità specifiche per attività.
Appunti pratici di architettura per ingegneri
- Impronta dei parametri vs. elaborazione attivata: Grandi totali di parametri (centinaia di miliardi) non si traducono direttamente in un costo di attivazione equivalente per ogni richiesta: MoE significa che solo un sottoinsieme di esperti si attiva per sequenza di token, offrendo un compromesso più favorevole tra costi e produttività per molti carichi di lavoro.
- Precisione e formati dei token: I pesi pubblici sono distribuiti nei formati BF16 e F32 e stanno comparendo rapidamente quantizzazioni comunitarie (GGUF, 4/8 bit); queste consentono ai team di eseguire GLM-4.6 su vari profili hardware.
- Compatibilità dello stack di inferenza: Z.ai documenta vLLM e altri moderni runtime LLM come backend di inferenza compatibili, il che rende GLM-4.6 fattibile sia per le distribuzioni cloud che on-prem.
Prestazioni di riferimento: come si comporta GLM-4.6?
Quali parametri di riferimento sono stati segnalati?
Z.ai ha valutato GLM-4.6 su una serie di otto parametri di riferimento pubblici che abbraccia attività di agentic, ragionamento e codifica. Hanno anche esteso CC-Bench (un benchmark di codifica su attività reali, valutato da utenti umani e eseguito in ambienti isolati da Docker) per simulare meglio le attività di ingegneria di produzione (sviluppo front-end, test, risoluzione algoritmica di problemi). In queste attività, GLM-4.6 ha mostrato miglioramenti costanti rispetto a GLM-4.5.
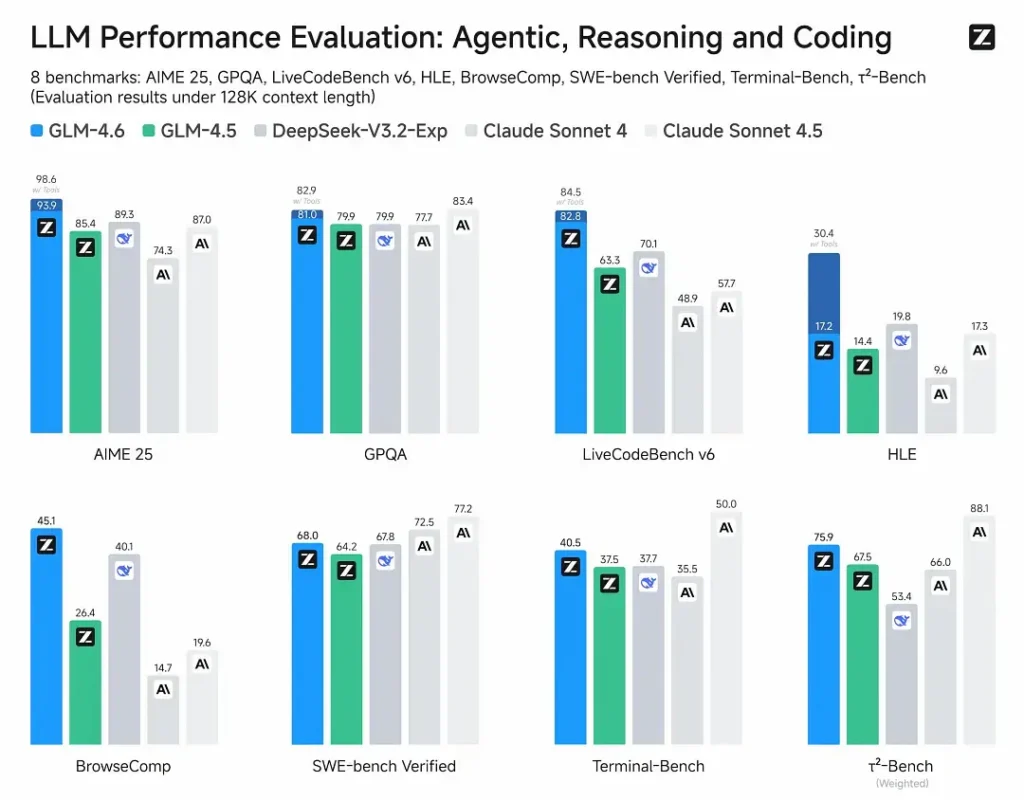
Prestazioni di codifica
- Vittorie nei compiti reali: Nelle valutazioni umane CC-Bench, GLM-4.6 ha raggiunto quasi parità con Claude Sonnet 4 di Anthropic in compiti multi-turni e testa a testa: Z.ai segnala un 48.6% percentuale di vincita nelle loro valutazioni isolate da Docker e valutate da esperti umani (interpretazione: quasi 50/50 con Claude Sonnet 4 nel loro set curato). Allo stesso tempo, GLM-4.6 ha superato diversi modelli aperti nazionali (ad esempio, varianti di DeepSeek) nei loro compiti.
- Efficienza del token: Rapporti di Z.ai ~15% di token in meno utilizzato per completare le attività rispetto a GLM-4.5 nelle traiettorie CC-Bench: questo è importante sia per la latenza che per i costi.
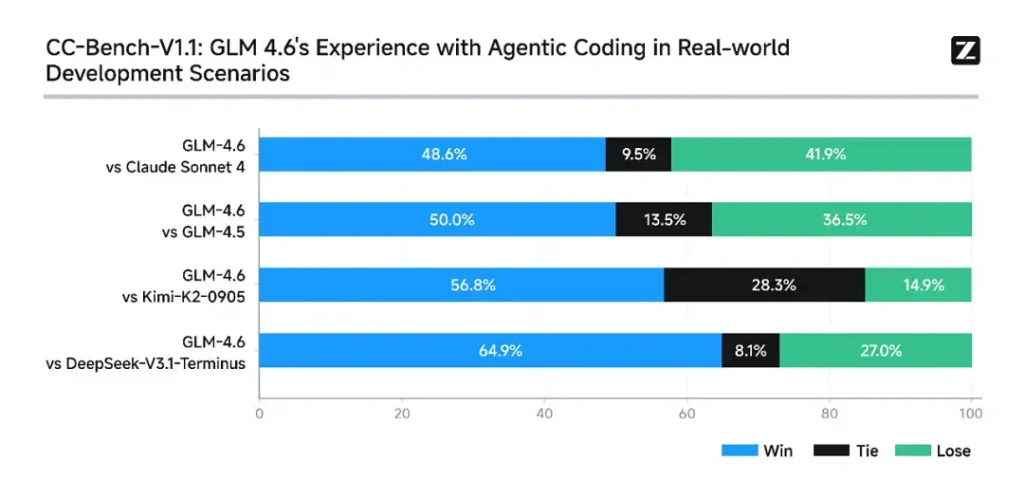
Ragionamento e matematica
GLM-4.6 afferma di aver migliorato la capacità di ragionamento e di aver migliorato le prestazioni nell'utilizzo degli strumenti rispetto a GLM-4.5. Mentre GLM-4.5 enfatizzava le modalità di "pensiero" ibrido e di risposta diretta, GLM-4.6 aumenta la robustezza per il ragionamento multi-step, soprattutto se integrato con strumenti di ricerca o esecuzione.
La messaggistica pubblica di Z.ai posiziona GLM-4.6 come competitivo con i principali modelli nazionali e internazionali Nei benchmark scelti, in particolare, competitivo con Claude Sonnet 4 e con prestazioni superiori ad alcune alternative nazionali come le varianti di DeepSeek nelle attività di codice/agente. Tuttavia, in alcuni sottobenchmark specifici per la codifica**, GLM-4.6 è ancora inferiore a Claude Sonnet 4.5 (una versione più recente di Anthropic), rendendo il panorama più competitivo che dominato.
Come accedere a GLM-4.6
- 1. Attraverso la piattaforma Z.ai: Gli sviluppatori possono accedere direttamente a GLM-4.6 tramite API di Z.ai or **interfaccia di chat (chat.z.ai)**Questi servizi ospitati consentono una sperimentazione e un'integrazione rapide senza distribuzione locale. L'API supporta sia il completamento standard del testo che le modalità di chiamata strutturata degli strumenti, essenziali per i flussi di lavoro agentici.
- 2. Pesi aperti su Hugging Face e ModelScope: Per coloro che preferiscono il controllo locale, Zhipu AI ha rilasciato i file del modello GLM-4.6 su Abbracciare il viso e al ModelScope, comprese le versioni di safetensor in BF16 e al F32 precisione. Gli sviluppatori della community hanno già prodotto versioni GGUF quantizzate, consentendo l'inferenza su GPU di livello consumer.
- 3. Quadri di integrazione: GLM-4.6 si integra perfettamente con i principali motori di inferenza come vLLM, SGLange LMDeploy, rendendolo adattabile alle moderne pile di servizio. Questa versatilità consente alle aziende di scegliere tra Cloud, bordoe distribuzione on-prem a seconda dei requisiti di conformità o latenza.
CometAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale (IA) di provider leader, come la serie GPT di OpenAI, Gemini di Google, Claude di Anthropic, Midjourney, Suno e altri, in un'unica interfaccia intuitiva per gli sviluppatori. Offrendo autenticazione, formattazione delle richieste e gestione delle risposte coerenti, CometAPI semplifica notevolmente l'integrazione delle funzionalità di IA nelle tue applicazioni. Che tu stia sviluppando chatbot, generatori di immagini, compositori musicali o pipeline di analisi basate sui dati, CometAPI ti consente di iterare più velocemente, controllare i costi e rimanere indipendente dal fornitore, il tutto sfruttando le più recenti innovazioni nell'ecosistema dell'IA.
L'ultima integrazione GLM-4.6 apparirà presto su CometAPI, quindi rimanete sintonizzati! Mentre concludiamo il caricamento del modello GLM 4.6, esplorate gli altri nostri modelli nella pagina Modelli o provateli nell'AI Playground.
Gli sviluppatori possono accedere API GLM‑4.5 tramite CometAPI, l'ultima versione del modello è sempre aggiornato con il sito ufficiale. Per iniziare, esplora le capacità del modello nel Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API. CometaAPI offrire un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrarti.
Pronti a partire? → Iscriviti oggi a CometAPI !
Conclusione: perché GLM-4.6 è importante adesso
GLM-4.6 rappresenta un traguardo importante nella linea GLM perché unisce miglioramenti pratici per gli sviluppatori (finestre di contesto più lunghe, ottimizzazioni mirate di codifica e agentic e miglioramenti tangibili nei benchmark) con l'apertura e la flessibilità dell'ecosistema che molte organizzazioni desiderano. Per i team che sviluppano assistenti di codice, agenti di documenti di formato esteso o automazioni basate su strumenti, GLM-4.6 merita di essere valutato come uno dei migliori candidati.