
.webp&w=3840&q=75)
GLM-5.1 rappresenta una svolta cruciale nel panorama dell’IA. Mentre le aziende cinesi di IA accelerano la commercializzazione aprendo al contempo le capacità di frontiera, questo modello riduce il divario con i leader proprietari come GPT-5.4 di OpenAI, Claude Opus 4.6 di Anthropic e Gemini 3.1 Pro di Google—soprattutto nell’ingegneria del software reale. Addestrato sulla stessa architettura MoE da 744 miliardi di parametri di GLM-5 ma fortemente ottimizzato per flussi di lavoro agentici, eccelle dove la maggior parte degli LLM vacilla: attività lunghe, ambigue e iterative che richiedono pianificazione, sperimentazione, debug e auto-correzione su migliaia di chiamate agli strumenti.
Ora, CometAPI integra GLM-5.1 e GLM-5, e gli sviluppatori possono anche vedere altri modelli occidentali di punta e accedervi a un prezzo API molto basso (che è anche un vantaggio di CometAPI rispetto ad altri concorrenti).
Che cos’è GLM-5.1?
GLM-5.1 è il nuovo modello di punta di Z.ai e l’ultimo impegno dell’azienda nel lavoro software in stile agente a lungo orizzonte. Nelle parole di Z.ai, è progettato per attività che richiedono esecuzione continua anziché risposte “one-shot”, ed è posizionato come un modello che può pianificare, eseguire, affinare e consegnare all’interno di una singola esecuzione estesa. Le note di rilascio di Z.ai affermano che GLM-5.1 è costruito con fine-tuning supervisionato multi-turno, apprendimento per rinforzo e un framework di valutazione della qualità del processo, e che migliora stabilità, coerenza e uso degli strumenti su attività prolungate.
Questo posizionamento è importante perché GLM-5.1 non viene venduto come “l’ennesimo modello di chat”. È rivolto a flussi di lavoro ingegneristici in cui i modelli devono mantenere un obiettivo in mente, gestire passaggi intermedi e recuperare dagli errori senza perdere il filo, come modello per pianificazione autonoma, esecuzione sostenuta, correzione di bug e iterazione strategica—una storia di prodotto molto diversa da un assistente casual o un copilota di codice a contesto breve.
Un dettaglio pratico utile: GLM-5.1 è solo testo, è supportato nel GLM Coding Plan e può essere usato in agenti di coding popolari come Claude Code e OpenClaw, il che lo rende particolarmente rilevante per i team che vogliono un modello inserito in un flusso di lavoro sviluppatori esistente anziché sostituirlo.
Specifiche tecniche principali (ereditate e affinate da GLM-5):
- Architettura: Mixture-of-Experts (MoE) con 744 miliardi di parametri totali e circa 40 miliardi di parametri attivi per inferenza.
- Finestra di contesto: 203K–204.8K token (con supporto fino a 131K token di output).
- Miglioramenti chiave: DeepSeek Sparse Attention (DSA) per una gestione efficiente del contesto lungo e costi di deployment ridotti; infrastruttura avanzata di apprendimento per rinforzo asincrono (tramite il framework “slime” di Z.ai) per un post-training più efficace.
- Disponibilità: Pesi aperti (licenza MIT su Hugging Face via zai-org/GLM-5.1), accesso API tramite la piattaforma di Z.ai e aggregatori come CometAPI, e integrazione negli strumenti GLM Coding Plan (compatibile con Claude Code / OpenClaw).
A differenza dei modelli GLM precedenti focalizzati su intelligenza generale o “vibe coding” di breve durata, GLM-5.1 punta agli agenti autonomi di livello produttivo. Può pianificare, eseguire, effettuare benchmark, fare debug e iterare su progetti di ingegneria complessi per ore senza intervento umano—capacità che lo posizionano come concorrente diretto degli agenti di coding specializzati di Anthropic e OpenAI.
Il rilascio è coinciso con un aumento del prezzo API di ~10% (token di input ~$0.54/M, output ~$4.40/M), e resta comunque drasticamente più economico rispetto a equivalenti come Opus 4.6 di Anthropic (più costoso del 250–470%).
Prestazioni benchmark di GLM-5.1
Z.ai posiziona GLM-5.1 come il modello open source più potente al mondo e tra i primi 3 a livello globale nel coding agentico. I dati prestazionali provengono da valutazioni ufficiali su SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 e scenari personalizzati a lungo orizzonte.
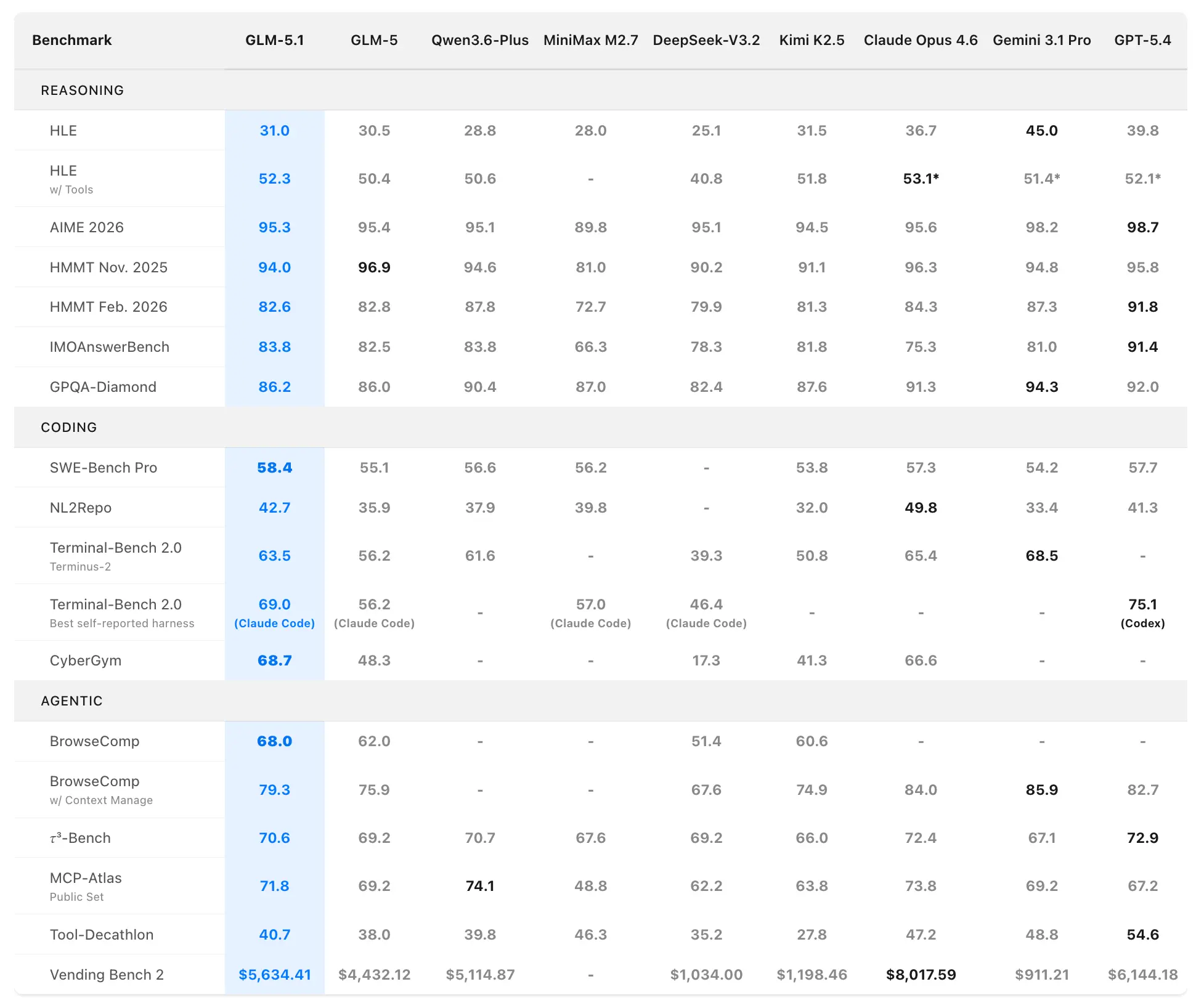
Benchmark di coding e agentici
SWE-Bench Pro (attività realistiche di ingegneria del software che richiedono navigazione nel repository, modifica del codice e verifica funzionale):
- GLM-5.1: 58.4 (nuovo state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 è il primo modello domestico (cinese) e open source a rivendicare il primo posto in questo rigoroso benchmark, che rispecchia da vicino i flussi di lavoro dei developer professionisti.
NL2Repo (dal linguaggio naturale alla generazione di un repository completo):
- GLM-5.1: 42.7 (ampio vantaggio su 35.9 di GLM-5)
- I modelli concorrenti variano tra 32.0–49.8 (i leader specifici variano a seconda dell’harness).
Terminal-Bench 2.0 (attività reali da terminale e di sistema):
- Harness Terminus-2: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Miglior valore auto-dichiarato (Claude Code): fino a 69.0.
In una valutazione separata con harness di coding (stile Claude Code), GLM-5.1 ha totalizzato 45.3—raggiungendo il 94.6% dei 47.9 di Claude Opus 4.6 e un miglioramento del 28% rispetto ai 35.4 di GLM-5.
Classifica composita: #1 open source, #1 modello cinese, #3 globale su SWE-Bench Pro + NL2Repo + Terminal-Bench.
Prestazioni su attività a lungo orizzonte: il vero elemento distintivo
I benchmark standard misurano prestazioni “one-shot” o su sessioni brevi. GLM-5.1 brilla in esecuzioni autonome prolungate:
- VectorDBBench Optimization (600+ iterazioni, 6,000+ chiamate a strumenti): Partendo da uno scheletro in Rust, GLM-5.1 ha ridisegnato iterativamente indicizzazione, compressione, instradamento e pruning, raggiungendo 21.5k QPS (6× rispetto al precedente best a 50 turni di 3,547 QPS di Claude Opus 4.6) mantenendo ≥95% di recall su SIFT-1M. Ha mostrato progressi “a gradini” con svolte strutturali ogni 100–200 iterazioni.
- KernelBench Level 3 (ottimizzazione completa di modelli ML, 1,000+ turni): Accelerazione media geometrica di 3.6× su 50 problemi complessi (superando 1.49× di torch.compile max-autotune). GLM-5.1 ha continuato a migliorare molto dopo il plateau di GLM-5; solo Claude Opus 4.6 lo ha superato con 4.2×.
- Linux Desktop Web App Build (8+ ore, aperta): Dato solo un prompt in linguaggio naturale e nessun codice iniziale, GLM-5.1 ha creato autonomamente un ambiente desktop in stile Linux funzionante—completo di barra delle applicazioni, finestre, interazioni e rifiniture—dove i modelli precedenti producevano solo scheletri basilari.
Questi risultati dimostrano la capacità di GLM-5.1 di mantenere coerenza, auto-valutarsi, rivedere strategie e uscire da ottimi locali su orizzonti estremamente lunghi—capacità che Z.ai ha esplicitamente ingegnerizzato per sistemi agentici reali.
In che cosa GLM-5.1 è diverso da GLM-5?
GLM-5 e GLM-5.1 sono strettamente correlati, ma non sono posizionati nello stesso modo. GLM-5 è l’earlier foundation model di Z.AI per l’ingegneria agentica. È progettato per l’ingegneria di sistemi complessi e attività agentiche di lungo raggio, con capacità di coding e agentiche SOTA a pesi aperti, e prestazioni di coding che si avvicinano a Claude Opus 4.5 in scenari reali di programmazione. Ottiene 77.8 su SWE-bench Verified e 56.2 su Terminal Bench 2.0.
GLM-5.1, per contro, è inquadrato come il passo successivo verso attività a lungo orizzonte e un’esecuzione sostenuta più affidabile, migliora stabilità, coerenza e uso degli strumenti su attività prolungate, ed è complessivamente più allineato a Claude Opus 4.6. In altre parole, GLM-5 è il precedente foundation model incentrato sull’ingegneria, mentre GLM-5.1 è il flaghsip più orientato alla resistenza sui compiti.
Ci sono anche differenze architetturali e di addestramento nella generazione GLM-5 che aiutano a spiegare il salto. GLM-5 è passato da 355B parametri (32B attivati) a 744B parametri (40B attivati), ha aumentato i dati di pre-training da 23T a 28.5T, ha aggiunto un framework di apprendimento per rinforzo asincrono e integrato DeepSeek Sparse Attention per preservare la qualità su testi lunghi migliorando l’efficienza. Questi dettagli sono legati a GLM-5, ma costituiscono la base su cui sembra costruito GLM-5.1.
GLM-5.1 vs altri modelli di frontiera
GLM-5.1 si distingue come il più forte contendente open source offrendo al contempo un rapporto prezzo/prestazioni convincente.
Tabella di confronto: principali benchmark di coding e agentici (aprile 2026)
| Modello | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Punteggio harness di coding | Sostenuto a lungo termine? | Open source? | Prezzo API appross. (Input/Output per M token) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% di Opus) | Sì (600+ iter, 8 ore) | Sì | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limitato | Sì | Più basso (prima dell’aumento) |
| GPT-5.4 | 57.7 | — | — | — | Forte | No | Più alto |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Il più forte | No | ~250–470% più costoso |
| Gemini 3.1 Pro | 54.2 | — | — | — | Buono | No | Più alto |
Verdetto: GLM-5.1 vince per accessibilità open source, costi e specifiche metriche di coding a lungo orizzonte. Se la gioca con i leader closed-source negli scenari agentici democratizzando al contempo capacità di frontiera.
Scenari di applicazione di GLM-5.1
1) Ingegneria del software autonoma
GLM-5.1 è più convincente quando il compito ricorda uno sprint di ingegneria reale: leggere il codebase, pianificare il cambiamento, implementarlo, testarlo, correggere le regressioni e iterare finché il risultato non è stabile. Le note di rilascio di Z.ai enfatizzano esplicitamente pianificazione autonoma, esecuzione sostenuta, correzione di bug e iterazione strategica, il che fa percepire questo modello come costruito su misura per agenti di coding e pipeline di delivery software.
2) Flussi di lavoro agentici di lunga durata
Se il tuo caso d’uso comporta molte chiamate a strumenti, workflow multi-step lunghi o auto-correzioni ripetute, il design di GLM-5.1 è un ottimo abbinamento. La documentazione evidenzia invocazione di strumenti, output strutturato, integrazione MCP e supporto al tool-streaming, tutti utili quando un modello non sta solo rispondendo, ma operando all’interno di un sistema più ampio.
3) Knowledge work e reportistica enterprise
GLM-5.1 è posizionato anche per attività di produttività d’ufficio come flussi PowerPoint, Word, PDF ed Excel. Z.ai afferma che migliora organizzazione di contenuti complessi, progettazione del layout, output strutturato e rifinitura visiva, il che lo rende una scelta plausibile per generazione di report, materiali didattici, sintesi di ricerca e altri lavori documentali.
4) Prototipazione front-end e artefatti
Secondo Z.ai, GLM-5.1 si adatta bene a generazione di siti web, pagine interattive e prototipazione front-end, con meno struttura preconfezionata e migliore qualità di completamento del compito. Ciò suggerisce un buon fit per i team di prodotto che necessitano di un ponte rapido dal brief al prototipo, specialmente quando il prototipo deve essere usabile e non solo gradevole.
5) Conversazione complessa e seguire istruzioni
Sebbene il tema principale sia il coding, GLM-5.1 è descritto come più forte anche in Q&A aperti, istruzioni complesse e interazioni multi-turno. Ciò lo rende utile per workflow in stile assistente in cui il modello deve tenere traccia dei vincoli, rivedere gli output e preservare il contesto lungo conversazioni più estese.
Conclusione: perché GLM-5.1 conta nel 2026
GLM-5.1 non è solo un altro rilascio incrementale—segnala l’arrivo di un’IA agentica open source davvero capace. Eccellendo nei benchmark di ingegneria del mondo reale più difficili e rimanendo accessibile e aperto, Z.ai ha alzato l’asticella per l’intero settore. Che tu sia uno sviluppatore singolo, un team enterprise o un ricercatore, GLM-5.1 offre un’autonomia senza pari per attività di coding a lungo orizzonte a una frazione dei costi proprietari.
Pronto a provarlo? Consulta il modello GLM-5.1 su CometAPI, il repository su Hugging Face o il GLM Coding Plan per un accesso immediato.