

Il 17 giugno 2025, MiniMax (nota anche come Xiyu Technology), leader dell'intelligenza artificiale con sede a Shanghai, ha rilasciato ufficialmente MiniMax-M1 (di seguito "M1"), il primo modello di ragionamento ibrido-attenzionale open-weight e su larga scala al mondo. Combinando un'architettura Mixture-of-Experts (MoE) con un innovativo meccanismo Lightning Attention, M1 raggiunge prestazioni leader del settore nelle attività orientate alla produttività, rivaleggiando con i migliori sistemi closed-source e mantenendo un rapporto costi-efficacia senza pari. In questo articolo approfondito, esploriamo cos'è M1, come funziona, le sue caratteristiche distintive e forniamo indicazioni pratiche per accedervi e utilizzarlo.
Che cosa è MiniMax-M1?
MiniMax-M1 rappresenta il culmine della ricerca di MiniMaxAI su meccanismi di attenzione scalabili ed efficienti. Basandosi sulle fondamenta di MiniMax-Text-01, l'iterazione M1 integra l'attenzione fulminea con un framework MoE per raggiungere un'efficienza senza precedenti sia durante l'addestramento che l'inferenza. Questa combinazione consente al modello di mantenere prestazioni elevate anche durante l'elaborazione di sequenze estremamente lunghe, un requisito fondamentale per attività che coinvolgono basi di codice estese, documenti legali o letteratura scientifica.
Architettura di base e parametrizzazione
MiniMax-M1 sfrutta un sistema MoE ibrido che instrada dinamicamente i token attraverso un sottoinsieme di sottoreti esperte. Sebbene il modello comprenda 456 miliardi di parametri in totale, solo 45.9 miliardi vengono attivati per ciascun token, ottimizzando l'utilizzo delle risorse. Questo design trae ispirazione da precedenti implementazioni MoE, ma perfeziona la logica di routing per ridurre al minimo il sovraccarico di comunicazione tra le GPU durante l'inferenza distribuita.
Attenzione fulminea e supporto a lungo termine
Una caratteristica distintiva di MiniMax-M1 è il suo meccanismo di attenzione fulminea, che riduce drasticamente l'onere computazionale dell'auto-attenzione per sequenze lunghe. Approssimando le matrici di attenzione attraverso una combinazione di kernel locali e globali, il modello riduce i FLOP fino al 75% rispetto ai trasformatori tradizionali durante l'elaborazione di sequenze di token da 100. Questa efficienza non solo accelera l'inferenza, ma apre anche le porte alla gestione di finestre di contesto fino a un milione di token senza requisiti hardware proibitivi.
In che modo MiniMax-M1 raggiunge l'efficienza di elaborazione?
I miglioramenti in termini di efficienza di MiniMax-M1 derivano da due innovazioni principali: la sua architettura ibrida Mixture-of-Experts e il nuovo algoritmo di apprendimento per rinforzo CISPO utilizzato durante l'addestramento. Insieme, questi elementi riducono sia i tempi di addestramento che i costi di inferenza, consentendo una rapida sperimentazione e implementazione.
Routing ibrido con mix di esperti
Il componente MoE impiega 32 sottoreti di esperti, ciascuna specializzata in diversi aspetti del ragionamento o in attività specifiche di dominio. Durante l'inferenza, un meccanismo di gating appreso seleziona dinamicamente gli esperti più rilevanti per ciascun token, attivando solo le sottoreti necessarie per elaborare l'input. Questa attivazione selettiva riduce drasticamente i calcoli ridondanti e riduce il fabbisogno di banda di memoria, garantendo a MiniMax-M1 un vantaggio sostanziale in termini di efficienza dei costi rispetto ai modelli con trasformatore monolitico.
CISPO: un nuovo algoritmo di apprendimento per rinforzo
Per rafforzare ulteriormente l'efficienza dell'addestramento, MiniMaxAI ha sviluppato CISPO (Clipped Importance Sampling with Partial Overrides), un algoritmo RL che sostituisce gli aggiornamenti del peso a livello di token con il clipping basato sul campionamento dell'importanza. CISPO mitiga i problemi di esplosione del peso comuni nelle configurazioni RL su larga scala, accelera la convergenza e garantisce un miglioramento stabile delle policy in diversi benchmark. Di conseguenza, l'addestramento RL completo di MiniMax-M1 su 512 GPU H800 si completa in sole tre settimane, con un costo di circa 534,700 dollari, una frazione del costo riportato per sessioni di addestramento GPT-4 comparabili.
Quali sono i parametri di prestazione di MiniMax-M1?
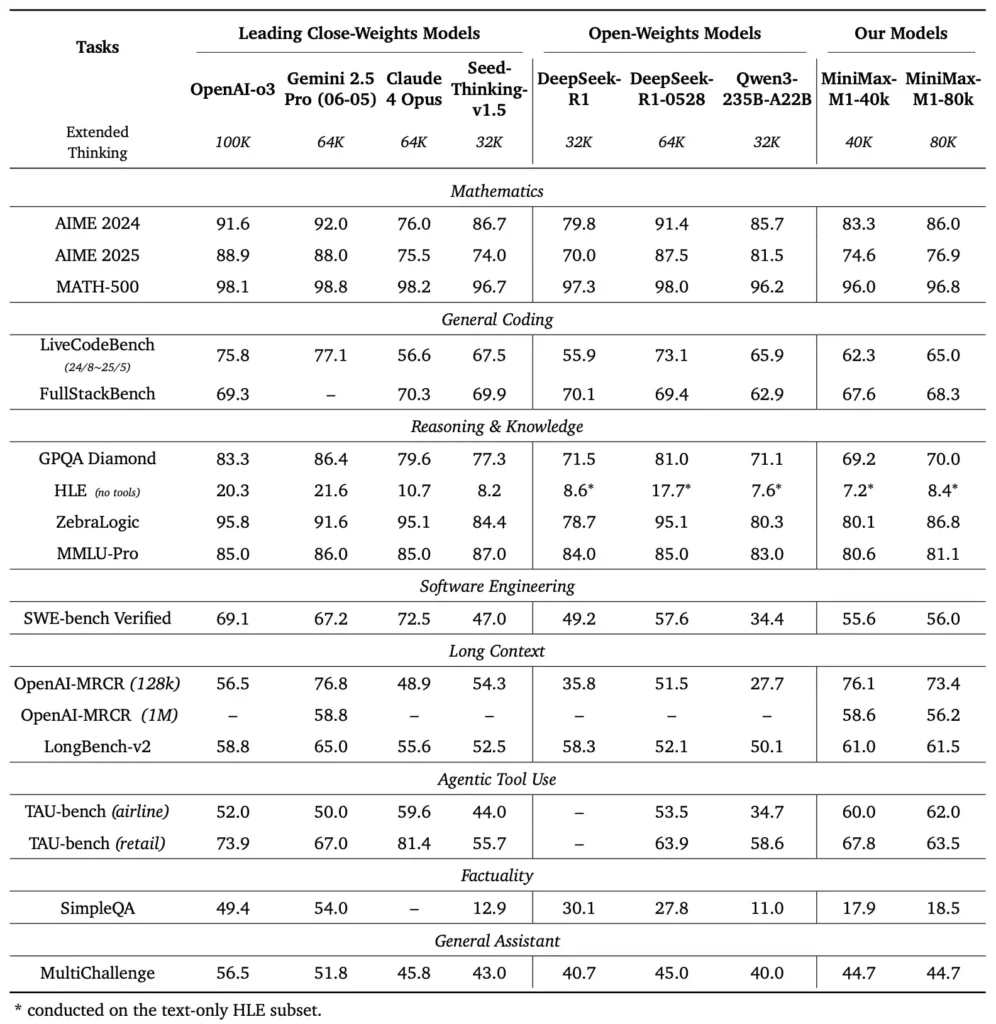
MiniMax-M1 eccelle in una varietà di benchmark standard e specifici di dominio, dimostrando la sua abilità nella gestione del ragionamento a lungo contesto, nella risoluzione di problemi matematici e nella generazione di codice.
Compiti di ragionamento a lungo contesto
In test approfonditi di comprensione dei documenti, MiniMax-M1 elabora finestre di contesto fino a 1,000,000 di token, superando DeepSeek-R1 di un fattore otto in termini di lunghezza massima del contesto e dimezzando i requisiti di elaborazione per sequenze di 100 token. In benchmark come la valutazione estesa del contesto di NarrativeQA, il modello raggiunge punteggi di comprensione all'avanguardia, attribuendo alla sua capacità di catturare in modo efficiente le dipendenze sia locali che globali.
Ingegneria del software e utilizzo degli strumenti
MiniMax-M1 è stato specificamente addestrato in ambienti di ingegneria del software sandbox che utilizzano RL su larga scala, consentendogli di generare e debuggare codice con notevole accuratezza. In benchmark di codifica come HumanEval e MBPP, il modello raggiunge percentuali di successo paragonabili o superiori a quelle di Qwen3-235B e DeepSeek-R1, in particolare in basi di codice multi-file e attività che richiedono riferimenti incrociati su lunghi segmenti di codice. Inoltre, le prime dimostrazioni di MiniMaxAI dimostrano la capacità del modello di integrarsi con gli strumenti di sviluppo, dalla generazione di pipeline CI/CD ai flussi di lavoro di auto-documentazione.
Come possono gli sviluppatori accedere a MiniMax-M1?
Per favorirne un'adozione diffusa, MiniMaxAI ha reso MiniMax-M1 disponibile gratuitamente come modello open-weight. Gli sviluppatori possono accedere a checkpoint pre-addestrati, pesi del modello e codice di inferenza tramite il repository ufficiale GitHub.
Rilascio open-weight su GitHub
MiniMaxAI ha pubblicato i file del modello di MiniMax-M1 e gli script di accompagnamento con una licenza open source permissiva su GitHub. Gli utenti interessati possono clonare il repository all'indirizzo https://github.com/MiniMax-AI/MiniMax-M1, che ospita checkpoint per le varianti con budget di token da 40 e 80, nonché esempi di integrazione per framework di ML comuni come PyTorch e TensorFlow.
Endpoint API e integrazione cloud
Oltre all'implementazione locale, MiniMaxAI ha stretto partnership con i principali provider cloud per offrire servizi API gestiti. Grazie a queste partnership, gli sviluppatori possono chiamare MiniMax-M1 tramite endpoint RESTful, con SDK disponibili per Python, JavaScript e Java. Le API includono parametri configurabili per la lunghezza del contesto, soglie di routing avanzate e budget dei token, consentendo agli utenti di personalizzare le prestazioni in base ai propri casi d'uso, monitorando al contempo il consumo di elaborazione in tempo reale.
Come integrare e utilizzare MiniMax-M1 in applicazioni reali?
Per sfruttare le funzionalità di MiniMax-M1 è necessario comprendere i suoi modelli API, le best practice per i prompt di contesto lungo e le strategie per l'orchestrazione degli strumenti.
Esempio di utilizzo base dell'API
Una tipica chiamata API prevede l'invio di un payload JSON contenente il testo di input e gli override di configurazione opzionali. Ad esempio:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
La risposta restituisce un JSON strutturato con testo generato, statistiche sull'utilizzo del token e registri di routing, consentendo un monitoraggio dettagliato delle attivazioni degli esperti.
Utilizzo degli strumenti e agente MiniMax
Oltre al modello principale, MiniMaxAI ha introdotto MiniMax Agent, un framework di agenti in versione beta in grado di richiamare internamente strumenti esterni, che vanno dagli ambienti di esecuzione del codice ai web scraper. Gli sviluppatori possono istanziare una sessione di agente che concatena il ragionamento del modello con l'invocazione di strumenti, ad esempio per recuperare dati in tempo reale, eseguire calcoli o aggiornare database. Questo paradigma di agente semplifica lo sviluppo di applicazioni end-to-end, consentendo a MiniMax-M1 di fungere da orchestratore in flussi di lavoro complessi.
Buone pratiche e insidie
- Ingegneria rapida per contesti lunghi: Suddividere gli input in segmenti coerenti, incorporare riepiloghi a intervalli logici e utilizzare strategie "riepiloga e poi ragiona" per mantenere l'attenzione sul modello.
- Compromessi tra calcolo e prestazioni: Sperimentare soglie di esperti più basse o budget di pensiero ridotti (ad esempio, la variante da 40K) per le applicazioni sensibili alla latenza.
- Monitoraggio e governance: Utilizzare i registri di routing e le statistiche sui token per verificare l'utilizzo degli esperti e garantire la conformità con i budget di costo, soprattutto negli ambienti di produzione.
Seguendo queste linee guida, gli sviluppatori possono sfruttare i punti di forza di MiniMax-M1 (gestione di contesti estesi e ragionamento efficiente) riducendo al contempo i rischi associati alle distribuzioni di modelli su larga scala.
Come si usa MiniMax-M1?
Una volta installato, M1 può essere richiamato tramite semplici script Python o notebook interattivi.
Come si presenta uno script di inferenza di base?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Questo esempio richiama la variante con budget di 40 k; passando a "MiniMax-AI/MiniMax-M1-80k" sblocca l'intero budget di ragionamento di 80 k ().
Come gestire i contesti molto lunghi?
Per gli input che superano le dimensioni tipiche del buffer, M1 supporta la tokenizzazione in streaming. Utilizzare stream=True flag nel tokenizzatore per alimentare i token in blocchi e sfruttare l'inferenza del checkpoint-restart per mantenere le prestazioni su sequenze di milioni di token.
Come è possibile adattare o ottimizzare M1?
Sebbene i checkpoint di base siano sufficienti per la maggior parte delle attività, i ricercatori possono applicare la messa a punto dell'RL utilizzando il codice CISPO incluso nel repository. Fornendo funzioni di ricompensa personalizzate, che vanno dalla correttezza del codice alla fedeltà semantica, i professionisti possono adattare M1 a flussi di lavoro specifici del dominio.
Conclusione
MiniMax-M1 si distingue come un modello di intelligenza artificiale innovativo, che amplia i confini della comprensione del linguaggio e del ragionamento a lungo contesto. Grazie alla sua architettura MoE ibrida, al meccanismo di attenzione Lightning e al regime di addestramento supportato da CISPO, il modello offre prestazioni elevate in attività che spaziano dall'analisi legale all'ingegneria del software, riducendo drasticamente i costi computazionali. Grazie alla sua versione open-weight e all'offerta di API cloud, MiniMax-M1 è accessibile a un ampio spettro di sviluppatori e organizzazioni desiderosi di sviluppare applicazioni basate sull'intelligenza artificiale di nuova generazione. Mentre la comunità dell'intelligenza artificiale continua a esplorare il potenziale dei modelli a lungo contesto, le innovazioni di MiniMax-M1 sono destinate a influenzare la ricerca e lo sviluppo di prodotti futuri in tutto il settore.
Iniziamo
CometAPI fornisce un'interfaccia REST unificata che aggrega centinaia di modelli di intelligenza artificiale, inclusa la famiglia ChatGPT, in un endpoint coerente, con gestione integrata delle chiavi API, quote di utilizzo e dashboard di fatturazione. Questo significa che non dovrete più destreggiarvi tra URL e credenziali di più fornitori.
Per iniziare, esplora le capacità dei modelli in Parco giochi e consultare il Guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API.
L'ultima integrazione dell'API MiniMax‑M1 apparirà presto su CometAPI, quindi rimanete sintonizzati! Mentre finalizziamo il caricamento del modello MiniMax‑M1, esplorate i nostri altri modelli su Pagina dei modelli oppure provali nel Parco giochi AIL'ultimo modello di MiniMax in CometAPI è API di anteprima ABAB7 di Minimax e al API MiniMax Video-01 ,fare riferimento a:
