

Seedance 2.0 è il modello di generazione video AI di nuova generazione di ByteDance, lanciato ufficialmente a marzo 2026. Supporta input di testo, immagine, audio e video, può utilizzare fino a 9 immagini, 3 clip video e 3 clip audio come riferimenti, ed è progettato per offrire controllo a livello di regia, stabilità del movimento e generazione audio‑video congiunta. Nelle classifiche a voto cieco attuali di Artificial Analysis, Seedance 2.0 guida le categorie text‑to‑video e image‑to‑video senza audio, con punteggi Elo rispettivamente di 1269 e 1351.
Che cos’è Seedance 2.0?
Seedance 2.0 è il modello di nuova generazione per la creazione di video di ByteDance Seed. Ufficialmente, si basa su un’architettura unificata di generazione congiunta audio‑video multimodale che accetta input di testo, immagine, audio e video, ed è posizionato come uno strumento per creator con capacità di riferimento ed editing insolitamente ampie. Seedance 2.0 è stato progettato per workflow di contenuti di livello industriale, con maggiore accuratezza fisica, realismo, controllabilità e stabilità in scene con movimenti complessi rispetto alla versione 1.5 precedente. Diversamente dai modelli precedenti che si concentravano principalmente sul text‑to‑video, Seedance 2.0 introduce una pipeline di generazione multimodale completamente unificata, che abilita:
- Generazione text‑to‑video
- Animazione image‑to‑video
- Editing video‑to‑video
- Output sincronizzato con l’audio
Questo lo rende una delle piattaforme di creazione video AI più complete disponibili nel 2026.
Perché è importante?
La maggior parte dei generatori di video è ancora ottimizzata per un workflow relativamente ristretto: prompt in, clip out. Seedance 2.0 va oltre trattando la generazione video più come uno spazio di lavoro da regista. Secondo ByteDance, può utilizzare più tipi di riferimento contemporaneamente, preservare la coerenza del soggetto, seguire istruzioni dettagliate in modo più fedele e persino pianificare il “linguaggio di macchina” in modo più “registico”. Questa combinazione è importante perché i problemi più difficili nella generazione video non sono solo estetici, ma riguardano continuità, coerenza del movimento e controllo su ciò che accade nel tempo.
Cosa c’è di nuovo e quali sono le funzionalità chiave di Seedance 2.0?
Generazione multimodale unificata
La caratteristica più importante è la capacità del modello di ragionare congiuntamente su più modalità. Seedance 2.0 supporta fino a 9 immagini, 3 video e 3 clip audio come riferimenti, insieme a istruzioni in linguaggio naturale, e può generare video fino a 15 secondi. In termini pratici, ciò significa che puoi guidare non solo il soggetto e la scena, ma anche lo stile del movimento, i movimenti di camera, gli effetti speciali e i cue audio in un’unica passata di generazione.
Controllo a livello di regia
Seedance 2.0 è costruito anche attorno a ciò che ByteDance descrive come controllo a livello di regia. I creator possono modellare performance, illuminazione, ombre e movimento della camera usando immagini, audio e video di riferimento. Il modello può preservare l’identità del soggetto in modo stabile, riprodurre script complessi con accuratezza e scegliere un linguaggio di macchina che rifletta una sorta di “logica di montaggio” incorporata. Per i creator, è un grande passo oltre il semplice text‑to‑video.
Editing ed estensione, non solo generazione
Un altro aggiornamento rilevante è che Seedance 2.0 non si ferma alla generazione. Seedance 2.0 aggiunge capacità di editing video ed estensione video, consentendo modifiche mirate a specifiche scene, personaggi, azioni o punti della trama e abilita inquadrature di follow‑on continue. L’articolo per sviluppatori spiega anche che il modello può essere utilizzato per “continuare le riprese” estendendo una clip invece di ricominciare da zero. Questo è importante per l’efficienza del workflow, perché riduce la necessità di rigenerare un’intera scena solo per correggere un segmento.
Migliore gestione dei movimenti complessi
Seedance 2.0 è significativamente più forte in scene con più soggetti, interazioni e movimenti complicati. La qualità di generazione è migliorata sensibilmente rispetto alla versione 1.5, con migliore accuratezza fisica, realismo e controllabilità. Il tasso di utilizzo di Seedance 2.0 in scene con movimenti difficili raggiunge un livello SOTA per il settore nel proprio quadro di valutazione interno, pur riconoscendo che sono necessari ulteriori miglioramenti nella stabilità dei dettagli fini, nel realismo e nella vividezza.
Benchmark delle prestazioni
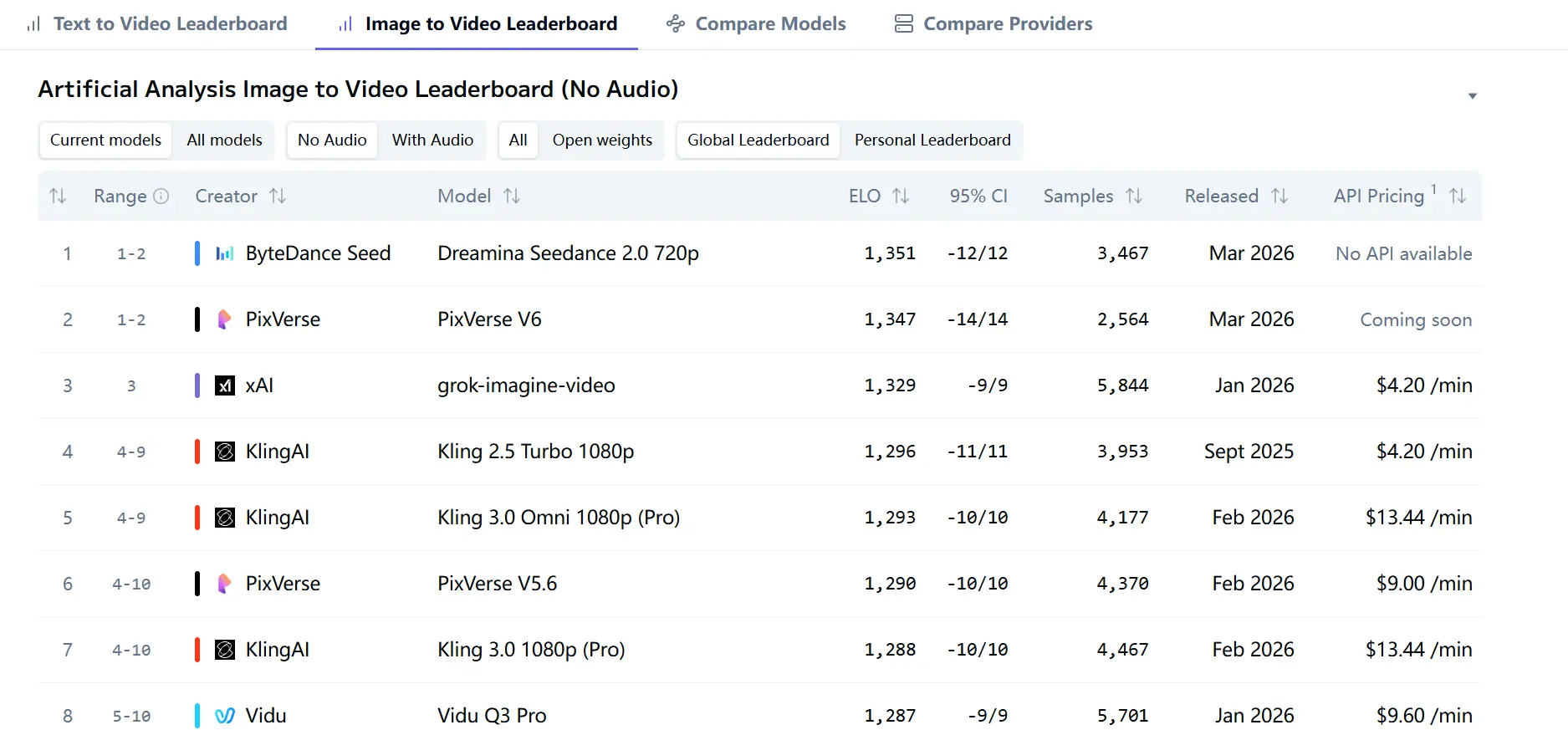
Il segnale di terze parti più forte nelle fonti esaminate è l’Artificial Analysis Video Arena. Nelle attuali pagine della classifica, Dreamina Seedance 2.0 720p guida l’Image‑to‑Video Arena senza audio con Elo 1351, e la Text‑to‑Video Arena senza audio con Elo 1269. Le pagine della classifica indicano inoltre che le posizioni derivano da voti ciechi degli utenti, il che è importante perché misura la preferenza umana su larga scala e non solo metriche interne al modello.
Questo è importante perché significa che Seedance 2.0 non è solo promosso come capace; attualmente è preferito dagli utenti in test comparativi diretti su due arene principali. Nel text‑to‑video senza audio, è davanti a Kling 3.0 1080p (Pro), SkyReels V4, PixVerse V6 e Kling 3.0 Omni 1080p (Pro). Nell’image‑to‑video senza audio, supera di poco PixVerse V6 e grok‑imagine‑video.

Istantanea delle prestazioni di Seedance 2.0
| Metrica | Seedance 2.0 |
|---|---|
| Posizionamento Image-to-Video | Top 15 a livello globale |
| Punteggio ELO | ~1258 |
| Posizionamento Text-to-Video | Top 25 |
| Costo | ~$1.56/min |
| Punto di forza | Equilibrio costo‑prestazioni |
👉 Interpretazione:
- Non sempre #1 in qualità pura
- Ma rapporto valore/prestazioni eccezionale
Quanto è valido, davvero, Seedance 2.0?
I suoi punti di forza principali
I punti di forza maggiori di Seedance 2.0 sono chiari: gestisce i movimenti complessi meglio di molti modelli video, supporta più modalità di riferimento, offre editing ed estensione, e guida attualmente le classifiche pubbliche più visibili in text‑to‑video e image‑to‑video senza audio. Miglioramenti in accuratezza fisica, realismo e controllabilità, che sono esattamente gli attributi che contano quando un modello passa dalle demo “da giocattolo” ai workflow professionali.
Le limitazioni attuali
Seedance non viene presentato da ByteDance come perfetto. C’è ancora margine per migliorare la stabilità dei dettagli, il realismo e la vividezza del movimento, e vengono segnalate sfide rimanenti nella coerenza multi‑soggetto, nella precisione del rendering del testo e negli effetti di editing complessi.
La mia valutazione
In base alle fonti esaminate, Seedance 2.0 sembra meno un aggiornamento marginale e più un passo serio verso un sistema video pronto per la produzione. Il suo punto di forza non è una singola demo appariscente, ma la combinazione di uno stack di input multimodale più ampio, controlli di editing diretti, estensione delle clip e una credibile leadership nelle classifiche pubbliche. Questo lo rende uno dei modelli video più importanti attualmente sul mercato, soprattutto per i team che tengono alla controllabilità tanto quanto alla qualità cinematografica pura.
Seedance 2.0 vs Sora 2 vs Veo 3.1
Tabella di confronto (leader AI video 2026)
| Caratteristica | Seedance 2.0 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Sviluppatore | ByteDance | OpenAI | |
| Tipi di input | Testo, immagine, audio, video | Testo | Testo + immagine |
| Generazione audio | ✅ Nativa | ❌ Limitata | ✅ |
| Lunghezza video max | 15–20 sec | ~25 sec | ~8 sec (estendibile) |
| Capacità di editing | ⭐ Avanzata (basata su riferimenti) | Moderata | Moderata |
| Classifica ELO | Top 15–25 | Alta | Alta |
| Efficienza dei costi | ⭐ Elevata | Media | Media |
| Uso commerciale | Sì | Limitato (filigrana) | Sì |
| Punto di forza unico | Editing multimodale | Narrazione lunga | Fedeltà visiva |
Punti chiave
- Seedance 2.0 = miglior editing + flessibilità multimodale
- Sora 2 = migliore lunghezza narrativa
- Veo 3.1 = migliore fedeltà image‑to‑video
Nelle attuali classifiche di Artificial Analysis per il text‑to‑video, Seedance 2.0 720p è davanti sia a Veo 3.1 sia a Sora 2 Pro nella categoria senza audio. Questo non chiude ogni dibattito sulla qualità, perché i modelli differiscono per workflow, vincoli di sicurezza e packaging di prodotto, ma mostra che Seedance 2.0 è entrato nello stesso top tier delle offerte occidentali più visibili.
Il vantaggio più evidente di Seedance 2.0 è l’ampiezza dell’input. ByteDance afferma che può elaborare congiuntamente testo, immagine, audio e video, e può utilizzare fino a 9 immagini, 3 video e 3 clip audio alla volta. La documentazione di Sora 2 di OpenAI, per contro, elenca come input testo e immagine e come output video e audio, con accesso tramite l’app Sora e sora.com; Sora 2 Pro è disponibile anche per gli utenti ChatGPT Pro sul web. Google Veo 3.1 si colloca nel mezzo: è costruito attorno alla creazione guidata da immagine e alla generazione di video ricchi di audio, con fino a 3 immagini di riferimento, estensione di scena e controllo del primo e dell’ultimo fotogramma.
Come accedere e dove confrontare
Se vuoi accedere contemporaneamente su un’unica piattaforma a Sora 2, Veo 3.1 e xx, ti consiglio CometAPI. Il Playground di CometAPI offre generazione video diretta usando solo un semplice comando o alcune immagini di riferimento. Se vuoi configurare programmaticamente la tua API di generazione video, allora CometAPI è ancora più da considerare. Fornisce API per Sora 2, Veo 3.1, ecc., ed è attualmente scontato del 20%.
Come usare Seedance 2.0 con CometAPI
Generazione Text‑to‑Video
Scrivi una descrizione della tua scena. Più è specifica, meglio è — includi movimenti di camera, illuminazione, mood e stile. La forte aderenza ai prompt di Seedance 2.0 fa sì che l’output corrisponda da vicino alla tua intenzione, rendendolo affidabile per la produzione di contenuti piuttosto che per tentativi ed errori.
All’interno del CometAPI Playground, puoi inserire direttamente i prompt e generare video usando il modello Seedance 2.0. Questo è particolarmente utile per contenuti social (Reels, TikTok, YouTube Shorts), video di brand e clip narrative brevi.
Come funziona:
- Apri CometAPI
- Seleziona il modello Seedance 2.0
- Inserisci il tuo prompt
- Regola i parametri (durata, risoluzione, rapporto d’aspetto)
- Avvia il job di generazione e attendi l’output
Da immagine a video con CometAPI
Carica un’immagine statica — come una foto di prodotto, un’illustrazione di concept o un mockup di design — e usa le capacità image‑to‑video di Seedance 2.0 tramite CometAPI per animarla.
Il risultato è un movimento fluido e consapevole del contesto generato dal tuo input visivo. È ideale per i team che dispongono già di asset di design e vogliono convertirli in video senza un workflow di produzione completo.
Come funziona:
- Usa
input_reference(o il campo di caricamento file equivalente nel Playground) - Aggiungi un prompt focalizzato sul movimento che descriva come dovrebbe muoversi la scena
Esempio di prompt:
“La camera avanza lentamente verso il prodotto, illuminazione da studio morbida, riflessi delicati, feeling da spot premium”
Generazione audio‑video in un unico passaggio
Invece di generare prima il video e poi aggiungere separatamente l’audio, CometAPI supporta la pipeline nativa di generazione audio‑video di Seedance 2.0.
Descrivendo in un unico prompt sia la componente visiva sia quella sonora, puoi generare in un solo step video e audio sincronizzati. Questo produce risultati più coesi e intenzionali, riducendo al contempo i tempi di editing.
Esempio di prompt:
“Una spiaggia tranquilla all’alba, onde che si infrangono dolcemente, luce dorata calda, musica ambient soffusa con suoni dell’oceano”
L’output include:
- Video generato
- Audio di sottofondo sincronizzato
- Tempistica e mood naturalmente allineati
Perché usare CometAPI per Seedance 2.0
- Accesso diretto via API o Playground
- Controllo semplice dei parametri (durata, risoluzione, formato)
- Supporta workflow sia text‑to‑video sia image‑to‑video
- Gestione integrata dei job per la generazione video asincrona
Conclusione
Seedance 2.0 sembra un autentico salto nella generazione video AI: un sistema multimodale che combina input di testo, immagine, audio e video; leader di classifica sia nel text‑to‑video sia nell’image‑to‑video; e un modello concepito per il controllo “da regista” più che per un uso occasionale. Se ti interessano solo la qualità percepita pura, le evidenze attuali indicano che è eccezionale.
Inizia a creare con Seedance 2.0 su CometAPI oggi stesso.