

In un panorama dominato dalla filosofia “scala a tutti i costi”—dove modelli come Flux.2 e Hunyuan-Image-3.0 spingono il numero di parametri nell’enorme intervallo 30B–80B—è emerso un nuovo contendente che sta sconvolgendo lo status quo. Z-Image, sviluppato dal Tongyi Lab di Alibaba, è stato lanciato ufficialmente, infrangendo le aspettative con un’architettura snella da 6 miliardi di parametri che eguaglia la qualità d’uscita dei giganti del settore pur funzionando su hardware consumer.
Rilasciato a fine 2025, Z-Image (e la sua variante ultra-veloce Z-Image-Turbo) ha catturato istantaneamente l’attenzione della comunità AI, superando le 500.000 download nelle 24 ore successive al debutto. Offrendo immagini fotorealistiche in appena 8 passaggi di inferenza, Z-Image non è solo un altro modello; è una forza democratizzante nel generative AI, abilitando creazioni ad alta fedeltà su laptop che annasperebbero con i concorrenti.
Che cos’è Z-Image?
Z-Image è un nuovo modello di base open source per la generazione di immagini, sviluppato dal team di ricerca Tongyi-MAI / Alibaba Tongyi Lab. È un modello generativo da 6 miliardi di parametri costruito su una nuova architettura Scalable Single-Stream Diffusion Transformer (S3-DiT) che concatena token di testo, token semantici visivi e token VAE in un unico flusso di elaborazione. L’obiettivo progettuale è esplicito: offrire fotorealismo di primo livello e aderenza alle istruzioni riducendo drasticamente i costi di inferenza e consentendo un uso pratico su hardware di consumo. Il progetto Z-Image pubblica codice, pesi del modello e una demo online sotto licenza Apache-2.0.
Z-Image viene distribuito in più varianti. La release più discussa è Z-Image-Turbo — una versione distillata a pochi passaggi ottimizzata per la messa in produzione — oltre alla non distillata Z-Image-Base (checkpoint di base, più adatta al fine-tuning) e Z-Image-Edit (istruita per l’editing di immagini).
Il vantaggio “Turbo”: inferenza in 8 passaggi
La variante di punta, Z-Image-Turbo, utilizza una tecnica di distillazione progressiva nota come Decoupled-DMD (Distribution Matching Distillation). Questo consente di comprimere il processo di generazione dai 30–50 passaggi standard a soli 8 passaggi.
Risultato: Tempi di generazione inferiori al secondo su GPU enterprise (H800) e prestazioni praticamente in tempo reale su schede consumer (RTX 4090), senza l’aspetto “plastico” o “slavato” tipico di altri modelli turbo/lightning.
4 caratteristiche chiave di Z-Image
Z-Image è ricco di funzionalità che soddisfano sia gli sviluppatori tecnici sia i professionisti creativi.
1. Fotorealismo e estetica senza pari
Nonostante abbia solo 6 miliardi di parametri, Z-Image produce immagini di sorprendente nitidezza. Eccelle in:
- Texture della pelle: Riproduzione di pori, imperfezioni e illuminazione naturale sui soggetti umani.
- Fisica dei materiali: Rendering accurato di vetro, metallo e tessuti.
- Illuminazione: Gestione superiore di illuminazione cinematografica e volumetrica rispetto a SDXL.
2. Rendering di testo bilingue nativo
Uno dei problemi più significativi nella generazione di immagini AI è stato il rendering del testo. Z-Image lo risolve con supporto nativo per inglese e cinese.
- Può generare poster complessi, loghi e insegne con ortografia e calligrafia corrette in entrambe le lingue, una funzionalità spesso assente nei modelli occidentali.
3. Z-Image-Edit: editing basato su istruzioni
Insieme al modello base, il team ha rilasciato Z-Image-Edit. Questa variante è ottimizzata per attività image-to-image, consentendo di modificare immagini esistenti usando istruzioni in linguaggio naturale (es. “Fai sorridere la persona”, “Cambia lo sfondo in una montagna innevata”). Mantiene alta coerenza di identità e illuminazione durante le trasformazioni.
4. Accessibilità su hardware consumer
- Efficienza VRAM: Funziona comodamente con 6GB di VRAM (con quantizzazione) fino a 16GB di VRAM (precisione piena).
- Esecuzione locale: Supporta pienamente il deployment locale tramite ComfyUI e
diffusers, liberando gli utenti da dipendenze cloud.
Come funziona Z-Image?
Single-stream diffusion transformer (S3-DiT)
Z-Image si discosta dai classici design a doppio flusso (stream separati per encoder di testo e immagine) e invece concatena token di testo, token VAE d’immagine e token semantici visivi in un singolo input del transformer. Questo approccio single-stream migliora l’utilizzo dei parametri e semplifica l’allineamento cross-modale all’interno del backbone transformer, che secondo gli autori offre un favorevole compromesso efficienza/qualità per un modello da 6B.
Decoupled-DMD e DMDR (distillazione + RL)
Per consentire la generazione a pochi passaggi (8 passaggi) senza la consueta penalità di qualità, il team ha sviluppato un approccio di distillazione Decoupled-DMD. La tecnica separa l’augmentazione CFG (classifier-free guidance) dal distribution matching, consentendo di ottimizzare ciascuno indipendentemente. In seguito applicano una fase di reinforcement learning post-training (DMDR) per affinare l’allineamento semantico e l’estetica. Insieme, questi producono Z-Image-Turbo con molti meno NFE rispetto ai tipici modelli di diffusione mantenendo un alto realismo.
Throughput di training e ottimizzazione dei costi
Z-Image è stato addestrato con un approccio di ottimizzazione del ciclo di vita: pipeline dati curate, un curriculum snellito e scelte di implementazione attente all’efficienza. Gli autori riportano il completamento dell’intero workflow di training in circa 314K ore GPU H800 (≈ USD $630K) — una metrica ingegneristica esplicita e riproducibile che posiziona il modello come conveniente rispetto alle alternative molto grandi (>20B).
Risultati di benchmark del modello Z-Image
Z-Image-Turbo si è classificato in alto in diverse classifiche contemporanee, includendo una posizione top open source nella leaderboard Artificial Analysis Text-to-Image e prestazioni solide nelle valutazioni di preferenza umana dell’Alibaba AI Arena.
Ma la qualità nel mondo reale dipende anche dalla formulazione del prompt, dalla risoluzione, dalla pipeline di upscaling e da eventuali post-processing aggiuntivi.
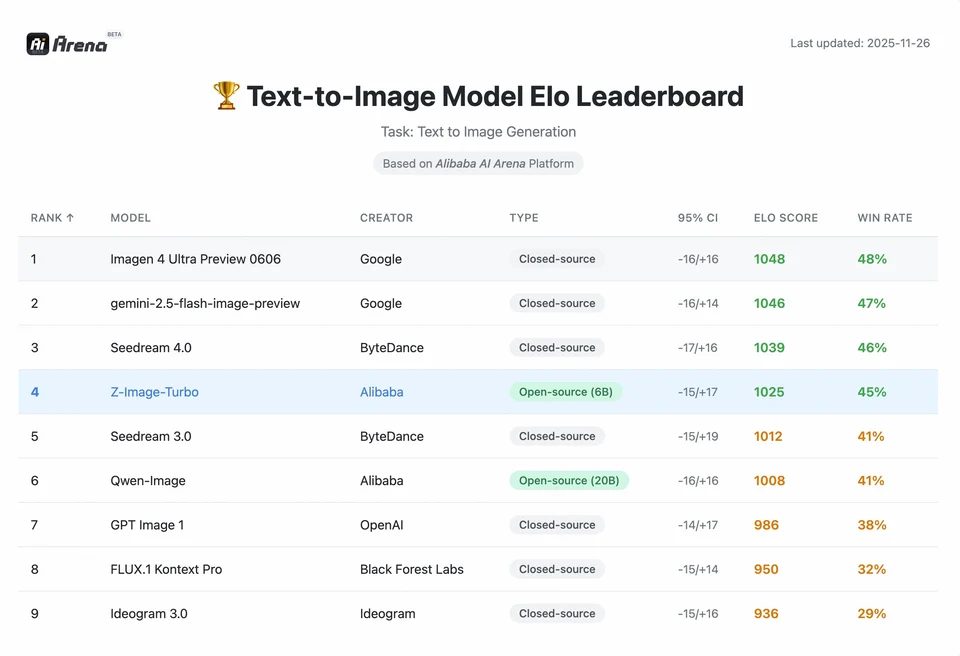
Per comprendere la portata del risultato di Z-Image, dobbiamo guardare ai dati. Di seguito è riportata un’analisi comparativa di Z-Image rispetto a modelli open source e proprietari leader.
Riepilogo comparativo dei benchmark
| Caratteristica / Metrica | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architettura | S3-DiT (single stream) | MM-DiT (doppio stream) | U-Net | Diffusion Transformer |
| Parametri | 6 miliardi | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Passaggi di inferenza | 8 passaggi | 25 - 50 passaggi | 1 - 4 passaggi | 30 - 50 passaggi |
| VRAM richiesta | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Rendering del testo | Alto (EN + CN) | Alto (EN) | Moderato (EN) | Alto (CN + EN) |
| Velocità di generazione (4090) | ~1,5 - 3,0 secondi | ~15 - 30 secondi | ~0,5 secondi | ~20 secondi |
| Punteggio di fotorealismo | 9,2/10 | 9,5/10 | 7,5/10 | 9,0/10 |
| Licenza | Apache 2.0 | Non commerciale (Dev) | OpenRAIL | Personalizzata |
Analisi dei dati e approfondimenti sulle prestazioni
- Velocità vs. qualità: Sebbene SDXL Turbo sia più veloce (1 passaggio), la sua qualità degrada significativamente con prompt complessi. Z-Image-Turbo centra il “punto di equilibrio” a 8 passaggi, eguagliando la qualità di Flux.2 pur essendo 5x–10x più veloce.
- Democratizzazione dell’hardware: Flux.2, pur potente, è di fatto vincolato a schede da 24GB di VRAM (RTX 3090/4090) per prestazioni ragionevoli. Z-Image consente agli utenti con schede di fascia media (RTX 3060/4060) di generare immagini professionali 1024×1024 in locale.
Come possono gli sviluppatori accedere e utilizzare Z-Image?
Ci sono tre approcci tipici:
- Hosted / SaaS (web UI o API): Utilizzare servizi come z-image.ai o altri provider che distribuiscono il modello ed espongono un’interfaccia web o un’API a pagamento per la generazione di immagini. È la via più rapida per sperimentare senza setup locale.
- Hugging Face + pipeline diffusers: La libreria
diffusersdi Hugging Face includeZImagePipelineeZImageImg2ImgPipelinee fornisce i tipici workflowfrom_pretrained(...).to("cuda"). Questo è il percorso consigliato per gli sviluppatori Python che desiderano integrazione semplice ed esempi riproducibili. - Inferenza nativa locale dal repo GitHub: Il repo Tongyi-MAI include script di inferenza nativa, opzioni di ottimizzazione (FlashAttention, compilazione, offload su CPU) e istruzioni per installare
diffusersda sorgente per l’integrazione più recente. Questo percorso è utile per ricercatori e team che vogliono pieno controllo o eseguire training/fine-tuning personalizzati.
Come appare un esempio Python minimale?
Di seguito un frammento Python conciso che dimostra la generazione testo-immagine con Z-Image-Turbo usando Hugging Face diffusers.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Note: i valori di default e le impostazioni consigliate per guidance_scale differiscono per i modelli Turbo; la documentazione suggerisce che la guidance possa essere impostata bassa o zero per Turbo, a seconda del comportamento desiderato.
Come eseguire image-to-image (edit) con Z-Image?
ZImageImg2ImgPipeline supporta l’editing di immagini. Esempio:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Questo rispecchia i pattern d’uso ufficiali ed è adatto ad attività di editing creativo e inpainting.
Come gestire prompt e guidance?
- Sii esplicito nella struttura: Per scene complesse, struttura i prompt includendo composizione della scena, soggetto focale, fotocamera/obiettivo, illuminazione, mood ed eventuali elementi testuali. Z-Image beneficia di prompt dettagliati e gestisce bene indicazioni posizionali/narrative.
- Regola con attenzione
guidance_scale: I modelli Turbo possono raccomandare valori di guidance più bassi; è necessaria sperimentazione. Per molti workflow Turbo,guidance_scale=0.0–1.0con seed e passaggi fissi produce risultati consistenti. - Usa image-to-image per modifiche controllate: Quando serve preservare la composizione ma cambiare stile/colori/oggetti, parti da un’immagine iniziale e usa
strengthper controllare l’entità del cambiamento.
Casi d’uso migliori e buone pratiche
1. Prototipazione rapida e storyboard
Use Case: Registi e game designer devono visualizzare le scene all’istante.
Perché Z-Image? Con generazione sotto i 3 secondi, i creatori possono iterare su centinaia di concept in una singola sessione, affinando illuminazione e composizione in tempo reale senza attendere minuti per un render.
2. E-commerce e pubblicità
Use Case: Generare sfondi di prodotto o scatti lifestyle per il merchandising.
Best Practice: Usa Z-Image-Edit.
Carica una foto grezza del prodotto e usa un prompt di istruzione come “Posiziona questa bottiglia di profumo su un tavolo di legno in un giardino illuminato dal sole.” Il modello preserva l’integrità del prodotto mentre “allucina” uno sfondo fotorealistico.
3. Creazione di contenuti bilingue
Use Case: Campagne di marketing globali che richiedono asset per mercati occidentali e asiatici.
Best Practice: Sfrutta la capacità di rendering del testo.
- Prompt: “Un’insegna al neon con la scritta ‘OPEN’ e ‘营业中’ che illumina un vicolo buio.”
- Z-Image renderizzerà correttamente sia i caratteri inglesi sia quelli cinesi, un’impresa che la maggior parte degli altri modelli non riesce a ottenere.
4. Ambienti a basse risorse
Use Case: Eseguire la generazione AI su dispositivi edge o laptop da ufficio standard.
Suggerimento di ottimizzazione: Usa la versione INT8 quantizzata di Z-Image. Riduce l’uso di VRAM sotto i 6GB con perdita di qualità trascurabile, rendendo fattibile le app locali su laptop non gaming.
In sintesi: chi dovrebbe usare Z-Image?
Z-Image è progettato per organizzazioni e sviluppatori che desiderano fotorealismo di alta qualità con latenza e costi pratici, e che preferiscono licenze aperte e hosting on-premises o personalizzato. È particolarmente attraente per i team che necessitano di iterazione veloce (strumenti creativi, mockup di prodotto, servizi in tempo reale) e per ricercatori/membri della community interessati al fine-tuning di un modello di immagini compatto ma potente.
CometAPI offre modelli Grok Image parimenti meno limitati, nonché modelli come Nano Banana Pro, GPT- image 1.5, Sora 2 (Sora 2 può generare contenuti NSFW? Come possiamo provarlo?) ecc.—a patto di avere i giusti suggerimenti e trucchi NSFW per aggirare le restrizioni e iniziare a creare liberamente. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore rispetto al prezzo ufficiale per aiutarti a integrare.
Pronto a iniziare?→ Prova gratuita per creare !