

AnthropicのClaudeシリーズは、急速に進化する大規模言語モデルの世界において、特に最先端のAI機能を求める企業や開発者にとって、礎となっています。4.1年5月2025日にリリースされるClaude Opus 4は、前身となるClaude Opus 22(2025年4.1月4.0日リリース)から段階的ながらもインパクトのあるアップグレードとなります。この記事では、公式発表、独立したベンチマーク、そして業界からのフィードバックに基づき、Opus XNUMXとOpus XNUMXのパフォーマンス、アーキテクチャ、安全性、そして実世界への適用性という観点から、主な違いを検証します。
Claude Opus 4.1は現在API経由で利用可能です(モデルID claude-opus-4-1-20250805)、Amazon Bedrock、Google Cloud の Vertex AI、そして有料版の Claude インターフェースで利用可能です。増分アップデートであるため、Opus 4 との完全な下位互換性が維持されており、価格、エンドポイント、既存の統合はすべて変更なく引き続き機能します。
Claude Opus 4.0 とは何ですか? なぜ重要なのですか?
Claude Opus 4.0は、堅牢な推論、拡張されたコンテキスト処理、そして高度なコーディング能力を単一のモデルに統合し、Anthropicの「フロンティアインテリジェンス」の追求において大きな飛躍を遂げました。これにより、以下の成果が達成されました。
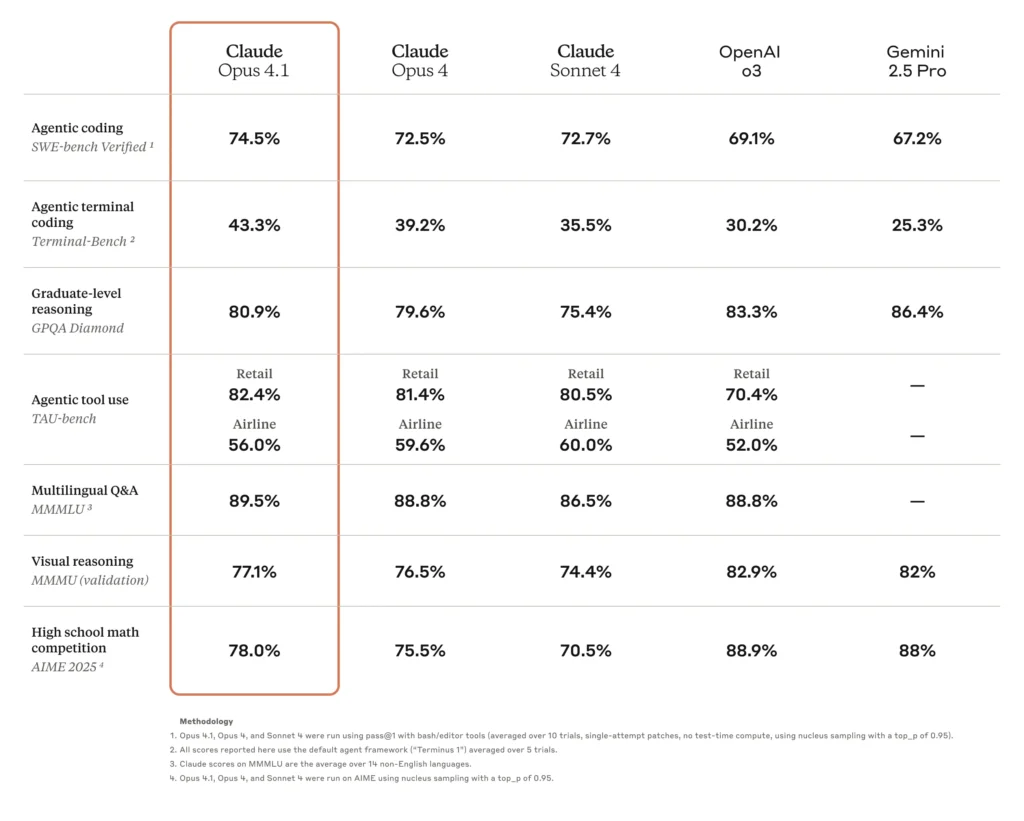
- 高いコーディング精度Opus 4.0 は、実際のコーディング課題のベンチマークである SWE-bench Verified で 72.5% のスコアを獲得し、ソフトウェア開発タスクへの実際の適用性が非常に高いことを実証しました。
- 高度なエージェント機能このモデルは、マルチステップの自律タスク実行に優れており、高度な AI エージェントがマーケティング オーケストレーションからリサーチ支援まで、ワークフローを管理できるようになりました。
- 創造力と分析力Opus 4.0 は、コーディング以外にも、クリエイティブ ライティング、データ分析、複雑な推論において最先端のパフォーマンスを実現し、ビジネス領域と技術領域の両方で多用途に使えるコラボレーターとなっています。
Opus 4.0 の幅広さと深さの組み合わせは、エンタープライズ AI の新たな基準を設定し、Claude Pro、Max、Team、および Enterprise プランでの急速な導入と、Amazon Bedrock および Google Cloud の Vertex AI への統合を促進しました。
Claude Opus 4.1 の新機能は何ですか?
コーディングタスクのベンチマークの改善
Opus 4.1の目玉となるアップグレードの一つは、コーディング精度の向上です。SWE-bench Verifiedでは、Opus 4.1は **74.5%**Opus 4.0の72.5%から増加しました。この2ポイントの増加は一見控えめに見えますが、デバッグサイクルの大幅な削減と、コード合成およびリファクタリングの精度向上に相当します。
エージェントタスクはどのような点で信頼性が高いのでしょうか?
Opus 4.1は、より強力な長期推論機能を提供し、AIエージェントが複雑で多段階的なプロセスをより一貫性を持って実行できるようにします。AWSによると、このモデルは、自律的なキャンペーン管理や部門横断的なワークフローオーケストレーションなど、思考の連鎖が長引くタスクにおいて「理想的な仮想コラボレーター」として機能するとのことです。
複数ファイルのリファクタリング精度
Opus 4.1の際立った特徴は、大規模なコード変更に対する保守的なアプローチです。Opus 4.0では相互接続されたファイル全体に不要な編集が行われることがありましたが、Opus 4.1は最小限の調整のみを分離することに優れており、付随的な変更を加えることなく正確な修正箇所を特定します。
主要なベンチマークで比較するとどうでしょうか?
コーディングベンチマーク
| モデル | SWEベンチ検証済み(%) | 複数ファイルのリファクタリングスコア |
|---|---|---|
| オーパス4.0 | 72.5 | ベースライン |
| オーパス4.1 | 74.5 | +1.2σゲイン |
出典: 人類学的システムカードと独立したベンチマーク
エージェントによる検索と調査
Opus 4.1は、 15% TAUベンチのエージェント評価が改善され、調査タスクにおける文脈保持と主体性が向上しました。ユーザーからは、関連情報への収束が速くなり、複数文書の要約がより一貫性のあるものになったという報告があります。
「エージェント探索」タスクにおけるベンチマーク比較では、Opus 4.1が計画、ツール活用、動的問題解決において高いスコアを達成していることが示されています。Anthropicによる社内のエージェント研究評価では、Opus 5と比較して、多段階推論の精度が7~4.0%向上し、自動データ分析パイプラインや研究レポート生成といったワークフローをより確実に実行できることが示されています。これらの進歩は、中間推論のトレーサビリティの強化によるところが大きく、この機能によりエンドユーザーはモデルの意思決定経路をより詳細に把握できるようになります。
最も大きな成果が得られるコーディングタスクは何ですか?
- 複数ファイルのリファクタリングOpus 4.1 では、相互依存モジュールを走査する際の一貫性が向上し、内部テストでファイル間エラーが 15% 以上削減されました。
- バグの特定と修復: このモデルにより、失敗したテストケースの根本原因をより確実に特定できるようになり、解決までの平均時間が 25% 短縮されます。
- ドキュメントの生成: 強化された自然言語の流暢性により、より包括的でコンテキストを認識した API ドキュメント文字列とインライン コメントがサポートされます。
Opus 4.1 はマルチステップタスクをどのように処理しますか?
- 改善された計画ヒューリスティック10 ステップのタスク チェーンにおける計画エラーを 8% 削減しました。
- 強化されたツール使用統合フォーマットエラーが少なくなり、より正確な API 呼び出しが可能になります。
- 中間推論プロンプト開発者が調整可能な「チェックポイント」でモデルの内部推論を検証および調整できるようにします。
指示コンプライアンス指標
単ターン評価では、Opus 4.1は違反リクエストに対して98.76%の無害な応答率を達成しました(Opus 97.27の4.0%から向上)。これは、禁止コンテンツに対する拒否率がより強力になったことを示しています()。無害なクエリに対する過剰拒否率は比較的低く(0.08% vs. 0.05%)、適切な状況でモデルが応答性を維持していることが保証されています。
どのような安全性とアライメントの強化が行われていますか?
シングルターン評価の改善
アントロピックによるOpus 4.1の簡易安全性監査では、児童の安全、バイアス、アライメントのベンチマークにおいて、一貫性のある、あるいは向上したパフォーマンスが確認されました。例えば、拡張思考における無害な反応率は97.67%から99.06%に上昇しました。
バイアスと堅牢性
BBQバイアスベンチマークにおいて、Opus 4.1の明確化されたバイアススコアは-0.51で、Opus 0.60の-4.0を上回りました。明確化されたクエリの精度は90%以上を維持し、曖昧なクエリではほぼ完璧でした。これらのわずかな変化は、センシティブなコンテキストにおいて中立性と高い忠実度が維持されていることを示しています。
アーキテクチャのアップグレードを支えるものは何ですか?
モデルの調整とデータの更新
Anthropic のチームは、次の点に重点を置いた、洗練された微調整プロトコルを実装しました。
- 拡張コードコーパス: より多くの注釈付きマルチファイル リポジトリを組み込みます。
- 拡張エージェントシナリオ: トレーニング中に長いタスク チェーンをキュレートして、長期的な推論能力を強化します。
- 強化された人間のフィードバックループ: エッジケースプロンプトに対する人間からのフィードバックからのターゲット強化学習 (RLHF) を活用して、幻覚を軽減します。
これらの調整により、Transformer のコア アーキテクチャを変更することなく測定可能な利点が得られ、既存の Anthropic API との互換性が確保されます。
インフラストラクチャとレイテンシー
生の推論レイテンシはOpus 4.0と同等ですが、Anthropicはサービスインフラストラクチャを最適化してコールドスタート時間を短縮しました。 **12%**Claude Chat や Copilot 統合などのインタラクティブ アプリケーションの応答性が向上します。
開発者や企業にとってどのような影響があるのでしょうか?
価格と可用性
クロード・オプス4.1は、 同じ値段 すべてのチャネル(Claude Pro、Max、Team、Enterprise、API、Amazon Bedrock、Google Vertex AI、Claude Code)でOpus 4.0としてアップグレードできます。アップグレードにコード変更は不要で、ユーザーはモデルピッカーで「Opus 4.1」を選択するだけです。
ユースケースの拡張
- ソフトウェア工学: デバッグの高速化、テスト生成の精度向上、CI/CD パイプラインの統合の改善。
- AIエージェント: マーケティング、財務、リサーチにおける信頼性の高い自律ワークフロー。
- エンタープライズインテリジェンス: データに基づく意思決定のための、強化された要約、レポート生成、詳細な分析。
これらのアップグレードにより、開発オーバーヘッドが削減され、AI を活用した取り組みの ROI が向上します。
Claude Opus の今後の予定は何ですか?
Anthropicは、Opus 4.1がより広範なロードマップのほんの一歩に過ぎないことを示唆しています。チームは今後のリリースで「大幅に大きな改善」を予定しており、おそらく以下の点を目標としていると思われます。
- さらに長いコンテキストウィンドウ (200万トークンを超える)
- マルチモーダル機能 画像、音声、コードを統合して理解します。
- より強力な解釈可能性 エージェントアクション中の意思決定経路を追跡するためのツール。
企業や開発者は、Anthropic のチャンネルで更新情報を確認する必要があります。段階的なアップグレードごとに、Claude は最も有能で安全な AI アシスタントとしての地位を固めていくからです。
スタートガイド
コメットAPI は、大手プロバイダーの 500 を超える AI モデルを集約した統合 API プラットフォームです。Claude Opus 4.1 は確かに CometAPI を通じてアクセス可能です。 CometAPI リスト anthropic/claude-opus-4.1 サポートされているモデルの中には、CometAPI の API を介してリクエストをルーティングできるものもあり、カーソル コード専用のモデルも利用できます。
まず、モデルの機能を調べてみましょう。 プレイグラウンド そして相談する クロード・オーパス4.1 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。
ベースURL: https://api.cometapi.com/v1/chat/completions
モデルパラメータ:
"claude-opus-4-1-20250805"→ 標準 Opus 4.1"claude-opus-4-1-20250805-thinking"→ 拡張推論を有効にしたOpus 4.1cometapi-opus-4-1-20250805→CometAPI専用。特に設計された標準バージョン カーソル 統合cometapi-opus-4-1-20250805-thinking→ CometAPI専用。CometAPI専用の拡張推論バージョン カーソル 統合
要約でClaude Opus 4.1はOpus 4.0の強みを基盤に、コーディング精度、エージェント推論、インフラパフォーマンスに的を絞った機能強化を提供します。しかも、コストの増加や統合パスの変更は発生しません。複雑なコードベースの改良、自律エージェントワークフローのオーケストレーション、高品質なビジネスインサイトの生成など、Opus 4.1は精度と汎用性を両立させた魅力的なアップグレードを提供します。AI環境が加速し続ける中、Anthropicの着実な改善により、Claude Opusは最先端の言語モデル機能の活用を目指す組織にとって最適な選択肢となっています。