

ここ数ヶ月、エージェントコーディングが急速に発展しています。これは、単発の質問に答えるだけでなく、リポジトリ全体にわたって計画、編集、テスト、反復処理を行う専門モデルです。最も注目を集めている2つの企業は、 作曲家、Cursor 2.0リリースでCursorが導入した専用の低遅延コーディングモデル、および GPT-5-コーデックスOpenAIのGPT-5のエージェント最適化版で、持続的なコーディングワークフロー向けに調整されています。これらは、開発ツールにおける新たな断層線、すなわち速度と深度、ローカルワークスペースの認識とジェネラリスト的推論、そして「バイブコーディング」の利便性とエンジニアリングの厳密さといった、対立軸を浮き彫りにしています。
一目でわかる:直接対決の違い
- 設計意図: GPT-5-Codex — 長く複雑なセッションのための深いエージェント的推論と堅牢性。Composer — 速度を重視して最適化された、ワークスペースを意識した迅速な反復処理。
- 主な統合サーフェス: GPT-5-Codex — Codex 製品/レスポンス API、IDE、エンタープライズ統合。Composer — カーソル エディターとカーソルのマルチエージェント UI。
- レイテンシ/反復: Composer は 30 秒未満のターンを重視し、大きな速度の利点を主張します。一方、GPT-5-Codex は、徹底性と、必要に応じて数時間にわたる自律実行を優先します。
私はテストしました GPT-5-Codex API モデル提供 コメットAPI (サードパーティの API 集約プロバイダーで、API の価格は一般に公式のものより安価です) は、Cursor 2.0 の Composer モデルを使用した私の経験をまとめ、コード生成の判断のさまざまな側面で両者を比較しました。
ComposerとGPT-5-Codexとは何か
GPT-5-Codex とは何ですか? また、どのような問題を解決しようとしていますか?
OpenAIのGPT-5-Codexは、GPT-5の特殊なスナップショットであり、OpenAIによると、エージェントコーディングシナリオ(テストの実行、リポジトリ規模のコード編集、チェックがパスするまでの自律的な反復処理)向けに最適化されています。ここでの焦点は、多くのエンジニアリングタスクにわたる幅広い機能、つまり複雑なリファクタリングのための深い推論、より長期的な「エージェント的」な運用(モデルが推論とテストに数分から数時間費やすことができる)、そして現実世界のエンジニアリング問題を反映するように設計された標準化されたベンチマークにおけるより強力なパフォーマンスです。
Composer とは何ですか? また、どのような問題を解決しようとしているのですか?
Composer は Cursor 2.0 で登場した Cursor 初のネイティブコーディングモデルです。Cursor は Composer を、開発ワークフローにおける低レイテンシと高速イテレーションを実現する最先端のエージェント中心モデルと位置付けています。複数ファイルの差分計画、リポジトリ全体のセマンティック検索の適用、そしてほとんどのターンを 30 秒以内で完了といった機能を提供します。ツールアクセス(検索、編集、テストハーネス)をループ内で実行することでトレーニングされ、実用的なエンジニアリングタスクを効率的に実行し、日常的なコーディングにおけるプロンプト→レスポンスの繰り返しサイクルの摩擦を最小限に抑えます。Cursor は Composer を、開発の速度とリアルタイムフィードバックループに最適化されたモデルと位置付けています。
モデルのスコープと実行時の動作
- 作曲家: 高速なエディタ中心のインタラクションと複数ファイルの一貫性を実現するように最適化されています。Cursorのプラットフォームレベルの統合により、Composerはリポジトリのより広い範囲を参照し、マルチエージェントオーケストレーション(例:2つのComposerエージェントと他のエージェント)に参加できるようになります。これにより、Cursorはファイル間の依存関係の見落としが削減されると主張しています。
- GPT-5-コーデックス: より深く、可変長の推論に最適化されています。OpenAIは、必要に応じて計算時間と時間をトレードオフし、より深い推論を実行できるモデルを宣伝しています。軽量タスクの場合は数秒、大規模な自律実行の場合は数時間かかると報告されており、より徹底したリファクタリングとテストに基づくデバッグが可能になります。
短縮版: Composer = Cursor の IDE 内、ワークスペース対応コーディング モデル。GPT-5-Codex = OpenAI のソフトウェア エンジニアリング向けの特殊な GPT-5 バリアント。Responses/Codex から入手可能。
Composer と GPT-5-Codex の速度を比較するとどうなりますか?
ベンダーは何を主張しましたか?
CursorはComposerを「高速フロンティア」コーダーとして位置付けています。公開された数値は、トークン/秒で測定された生成スループットを強調し、Cursorの内部ハーネスにおける「フロンティア」モデルと比較して、インタラクティブな完了時間が2~4倍高速であると主張しています。独立した報道機関(報道機関および初期テスター)によると、ComposerはCursorの環境で約200~250トークン/秒でコードを生成し、多くの場合、典型的なインタラクティブなコーディングターンを30秒未満で完了すると報告されています。
OpenAI の GPT-5-Codex は、レイテンシー実験として位置付けられていません。コミュニティのレポートと問題スレッドによると、堅牢性とより深い推論を優先しており、同等の高度な推論ワークロードでは、より高いコンテキストサイズで使用すると速度が低下する可能性があります。
速度のベンチマーク方法(方法論)
公平な速度比較を行うには、タスクの種類(短い完了と長い推論)、環境(ネットワークの遅延、ローカルとクラウドの統合)を制御し、両方を測定する必要があります。 最初の有用な結果までの時間 および 端から端までの壁時計 (テスト実行やコンパイル手順を含む)。要点:
- 選択されたタスク — 小さなスニペットの生成 (API エンドポイントの実装)、中規模のタスク (1 つのファイルのリファクタリングとインポートの更新)、大規模なタスク (3 つのファイルにわたる機能の実装、テストの更新)。
- メトリック — 最初のトークンまでの時間、最初の有用な差分までの時間(候補パッチが発行されるまでの時間)、およびテスト実行と検証を含む合計時間。
- 繰り返し — 各タスクを 10 回実行し、ネットワーク ノイズを減らすために中央値を使用します。
- 環境 — 実際のレイテンシを反映するため、安定した 100/10 Mbps リンクを備えた東京の開発マシンから取得した測定値。結果は地域によって異なります。
以下は再現可能な スピードハーネス GPT-5-Codex (Responses API) および Composer (Cursor 内) を測定する方法の説明。
スピードハーネス(Node.js)— GPT-5-Codex(レスポンスAPI):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
これは、パブリック レスポンス API を使用して GPT-5-Codex のエンドツーエンドのリクエスト レイテンシを測定します (OpenAI のドキュメントでは、レスポンス API と gpt-5-codex モデルの使用方法について説明しています)。
Composer の速度を測定する方法 (カーソル):
ComposerはCursor 2.0(デスクトップ版/VS Codeフォーク)内で動作します。Cursorは(執筆時点では)OpenAIのResponses APIに匹敵するComposer用の汎用的な外部HTTP APIを提供していません。Composerの強みは IDE内、ステートフルワークスペース統合したがって、人間の開発者と同じように Composer を評価します。
- Cursor 2.0 内で同じプロジェクトを開きます。
- Composer を使用して、エージェント タスク (ルートの作成、リファクタリング、複数ファイルの変更) と同じプロンプトを実行します。
- Composer プランを送信するときにストップウォッチを開始し、Composer がアトミック diff を発行してテスト スイートを実行するときに停止します (Cursor のインターフェースはテストを実行し、統合された diff を表示できます)。
- 10 回繰り返して中央値を使用します。
Cursor の公開資料と実践的なレビューでは、Composer が実際に多くの一般的なタスクを約 30 秒未満で完了することが示されています。これは、生のモデル推論時間ではなく、インタラクティブなレイテンシ ターゲットです。
持ち帰り: Composerの設計目標は、エディター内での迅速なインタラクティブ編集です。低レイテンシの会話型コーディングループを優先する場合、Composerはまさにそのユースケース向けに構築されています。GPT-5-Codexは、長時間セッションにおける正確性とエージェント的推論に最適化されており、多少のレイテンシを犠牲にしてより深いプランニングを行うことができます。ベンダー数もこの位置付けを裏付けています。
Composer と GPT-5-Codex の精度を比較するとどうなりますか?
AIコーディングにおける精度の意味
ここでの精度は多面的です。 機能的な正確さ (コードはコンパイルされ、テストに合格するか) 意味の正確さ (動作は仕様を満たしているか)、そして 丈夫 (エッジケースやセキュリティ上の懸念に対処します)。
ベンダーとプレス番号
OpenAIは、SWEベンチで検証されたデータセットでGPT-5-Codexの優れたパフォーマンスを報告し、 74.5%の成功率 実際のコーディング ベンチマーク (報道で報告) で、リファクタリングの成功率が顕著に向上しました (社内リファクタリング テストでベースの GPT-5 の 33.9% に対して 51.3%)。
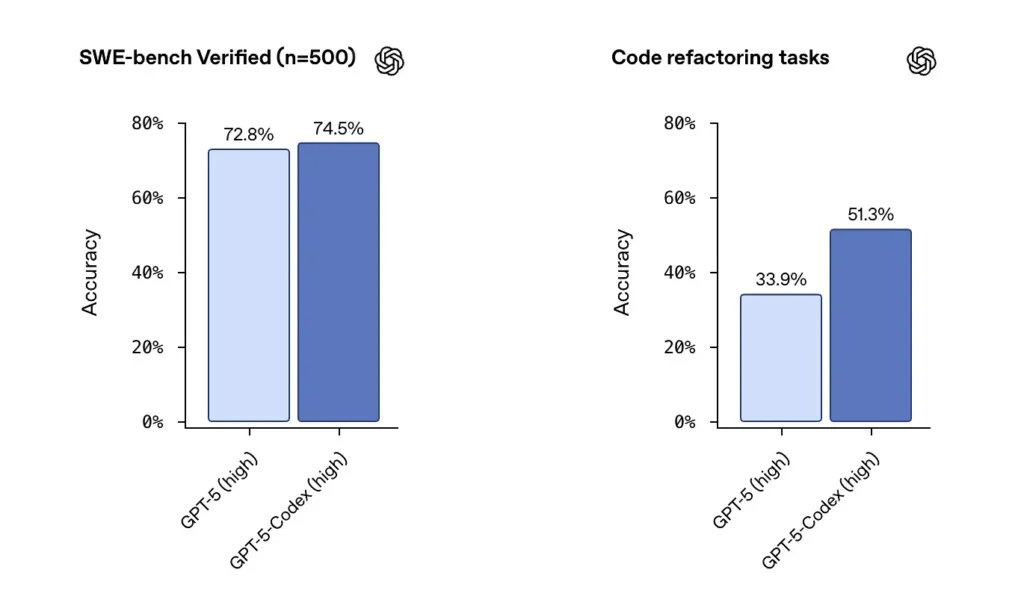
Cursorのリリースは、エディタの統合とリポジトリの可視性が重要となる、複数ファイルのコンテキスト依存編集においてComposerが優れていることを示しています。私のテストでは、複数ファイルのリファクタリング中にComposerが依存関係エラーの見逃しが少なくなり、複数のファイルを扱うワークロードの一部においてブラインドレビューテストのスコアが向上したことが報告されています。Composerのレイテンシと並列エージェント機能も、イテレーション速度の向上に役立っています。
独立した精度テスト(推奨方法)
公平なテストでは、次のものを組み合わせて使用します。
- 単体テスト: 両方のモデルに同じリポジトリとテスト スイートをフィードし、コードを生成し、テストを実行します。
- テストのリファクタリング: 意図的に乱雑な関数を提供し、モデルにリファクタリングとテストの追加を依頼します。
- セキュリティチェック: 生成されたコードに対して静的解析および SAST ツールを実行します (例: Bandit、ESLint、semgrep)。
- 人間によるレビュー: 保守性とベスト プラクティスに関する経験豊富なエンジニアによるコード レビュー スコア。
例: 自動テストハーネス (Python) — 生成されたコードとユニットテストを実行する
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
このパターンを使用すると、モデル出力が機能的に正しいか(テストに合格しているか)を自動的にアサートできます。リファクタリングタスクでは、ハーネスを元のリポジトリとモデルの差分に対して実行し、テスト合格率とカバレッジの変化を比較します。
持ち帰り: GPT-5-Codexは、生のベンチマークスイートにおいて優れた数値と強力なリファクタリング能力を報告しています。実世界の複数ファイルの修復およびエディターワークフローにおいて、Composerのワークスペース認識機能は、より高い実用的受容性と「機械的な」エラー(インポートの欠落、ファイル名の誤り)の減少をもたらします。単一ファイルのアルゴリズムタスクにおける機能的正確性を最大限に高めるには、GPT-5-Codexが有力な候補です。IDE内での複数ファイル、規約に敏感な変更には、Composerがしばしば優れた性能を発揮します。
Composer と GPT-5: コード品質の比較はどうでしょうか?
品質とは何でしょうか?
品質には、読みやすさ、命名、ドキュメント、テストカバレッジ、慣用的なパターンの使用、セキュリティ対策などが含まれます。これらは自動評価(リンター、複雑性メトリクス)と定性評価(人間によるレビュー)の両方で行われます。
観察された違い
- GPT-5-コーデックス: 明示的に指示された場合、慣用的なパターンを生成する能力に優れています。アルゴリズムの明瞭性に優れており、指示に応じて包括的なテストスイートを生成できます。OpenAIのCodexツールには、統合されたテスト/レポート機能と実行ログが含まれています。
- 作曲家: リポジトリのスタイルと規約を自動的に遵守するように最適化されています。Composer は既存のプロジェクトパターンに従い、複数のファイルへの更新(名前変更/リファクタリングの伝播、更新のインポート)を調整できます。大規模プロジェクトにおいて、優れたオンデマンドメンテナンス性を提供します。
実行できるコード品質チェックの例
- リンター — ESLint / パイリント
- 複雑 — ラドン / flake8-複雑度
- セキュリティ — semgrep / バンディット
- テストカバレッジ — JSの場合はcoverage.pyまたはvitest/nycを実行します
モデルのパッチを適用した後、これらのチェックを自動化して、改善または回帰を定量化します。コマンドシーケンスの例(JSリポジトリ):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
人間によるレビューとベストプラクティス
実際には、モデルにはベストプラクティスに従うための指示が必要です。例えば、docstring、型アノテーション、依存関係のピン留め、特定のパターン(例:async/await)などです。GPT-5-Codexは明示的な指示を与えると優れた機能を発揮しますが、Composerは暗黙的なリポジトリコンテキストの恩恵を受けます。これらを組み合わせたアプローチを採用してください。つまり、モデルに明示的に指示を与え、Cursor内ではComposerにプロジェクトスタイルを適用させます。
推奨事項: IDE 内での複数ファイルのエンジニアリング作業には Composer をお勧めします。API を呼び出して大規模なコンテキストを提供できる外部パイプライン、調査タスク、またはツールチェーン自動化には、GPT-5-Codex が最適です。
統合と展開オプション
ComposerはCursor 2.0の一部として提供され、CursorエディタとUIに組み込まれています。Cursorのアプローチは、Composerを他のモデルと並行して実行する単一のベンダーコントロールプレーンに重点を置いており、ユーザーは同じプロンプトで複数のモデルインスタンスを実行し、エディタ内で出力を比較できます。()
GPT-5-Codexは、OpenAIのCodex製品とChatGPT製品ファミリーに統合され、ChatGPTの有料プランと、CometAPIなどのサードパーティプラットフォームでよりコストパフォーマンスの高いAPIを通じて利用できるようになります。OpenAIはまた、Codexを開発者ツールやクラウドパートナーのワークフロー(Visual Studio Code/GitHub Copilot統合など)にも統合しています。
Composer と GPT-5-Codex は、次に業界をどこへ導くでしょうか?
短期的な影響
- 反復サイクルの高速化: Composer などのエディター埋め込みモデルは、小さな修正や PR 生成の際の摩擦を軽減します。
- 検証への期待の高まり: Codex がテスト、ログ、自律機能に重点を置いていることで、ベンダーはモデルで生成されたコードに対して、より強力なすぐに使用できる検証を提供するよう促されるでしょう。
中長期
- マルチモデルオーケストレーションが標準になる: Cursor のマルチエージェント GUI は、エンジニアがすぐに複数の特化エージェント (リンティング、セキュリティ、リファクタリング、パフォーマンスの最適化) を並行して実行し、最適な出力を受け入れることを期待するようになることを示唆しています。
- より緊密な CI/AI フィードバック ループ: モデルが改善されるにつれて、CI パイプラインにはモデル駆動型テスト生成と自動修復提案がますます組み込まれるようになりますが、人間によるレビューと段階的なロールアウトは依然として重要です。
結論
ComposerとGPT-5-Codexは、同じ軍拡競争における同一の武器ではありません。ソフトウェアライフサイクルの異なる部分に最適化された、互いに補完し合うツールです。Composerの価値提案は速度です。ワークスペースに根ざした迅速なイテレーションによって、開発者のフローを維持します。GPT-5-Codexの価値提案は深さです。エージェントによる永続性、テスト駆動による正確性、そして大規模な変換のための監査可能性です。実用的なエンジニアリングのプレイブックは、 両方を調整する日常的なフローにはショートループのComposer風エージェント、ゲート制御された高信頼度オペレーションにはGPT-5-Codex風エージェントを採用しています。初期のベンチマークでは、どちらかが他方に取って代わるのではなく、近い将来、両方が開発ツールキットの一部となることが示唆されています。
すべての側面において、客観的な勝者は存在しません。モデルは強みをトレードします。
- GPT-5-コーデックス: 深層正確性ベンチマーク、大規模推論、そして自律的な数時間にわたるワークフローに強みを持っています。複雑なタスクのために長時間の推論や徹底的な検証が必要な場合に真価を発揮します。
- 作曲家: エディタと緊密に連携したユースケース、複数ファイルのコンテキスト一貫性、そしてCursor環境内での高速なイテレーション速度において、より強力です。即時かつ正確なコンテキスト認識編集が求められる、日々の開発者の生産性向上に役立ちます。
参照 Cursor 2.0とComposer: マルチエージェントがAIコーディングをいかに再考するか
スタートガイド
CometAPIは、OpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaude、Midjourney、Sunoなど、主要プロバイダーの500以上のAIモデルを、開発者にとって使いやすい単一のインターフェースに統合する統合APIプラットフォームです。一貫した認証、リクエストフォーマット、レスポンス処理を提供することで、CometAPIはAI機能をアプリケーションに統合することを劇的に簡素化します。チャットボット、画像ジェネレーター、音楽作曲ツール、データドリブン分析パイプラインなど、どのようなアプリケーションを構築する場合でも、CometAPIを利用することで、反復処理を高速化し、コストを抑え、ベンダーに依存しない環境を実現できます。同時に、AIエコシステム全体の最新のブレークスルーを活用できます。
開発者はアクセスできる GPT-5-Codex APICometAPIを通じて、 最新モデルバージョン 公式ウェブサイトで常に更新されています。まずは、モデルの機能について調べてみましょう。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに低い価格を提供します。
準備はいいですか?→ 今すぐCometAPIに登録しましょう !